由内搜推送思考Kafka 的原理
Posted XiaoTeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了由内搜推送思考Kafka 的原理相关的知识,希望对你有一定的参考价值。
刚入公司的两周多,对CDX项目有了进一步的认识和理解,在这基础上,也开始了解部门内部甚至公司提供的一些中间服务。CDX项目中涉及到的二方服务和三方服务很多,从之前写过的SSO,Auth,到三方图库的各个接口,以及图片存储的云服务Gift,以及今天说到的内搜系统。
由于内搜推送信息是到一个kafka队列中消费,虽然作为业务开发不涉及消息中间件的建设,但还是希望能了解内部选型的一些思想,一点一点学习和理解部门的各个服务。这里我也参加了内部的一些分享,想说说自己对Kafka的初识吧。
首先是Kafka的官方介绍和原理:
Apache Kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
组成:
-
话题(Topic):是特定类型的消息分类。
-
生产者(Producer):是能够发布消息到话题的任何对象,在内搜这个模型中,我们各个业务系统就是消息的生产者。
-
服务代理(Broker):已发布的消息保存在一组服务器中,它们被称为代理(Broker)或Kafka集群。
-
消费者(Consumer):可以订阅一个或多个话题,并从Broker,pull数据,从而消费这些已发布的消息,Kafka都是pull的方式,并且涉及到消费的机制,等一下说。
- 组(Group): 包含多个消费者,但是默认情况下,在一个组内,同一个消息只会被一个Consumer消费。当然内搜的订阅者应该只存在一个组中。
消息推送方式:Push,Pull
这里有一副对比图很好的说明了两种情况的优劣,Kafka是使用pull的方式。
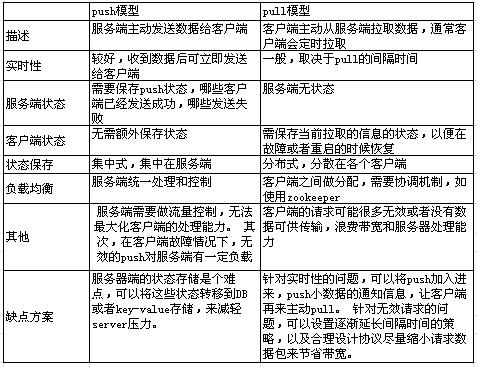
消费机制三种:
At most once—consumer先记录log再消费,这样消息可能会丢失造成没有消费,但不会重复消费。
At least once—consumer先消费了再记录log,这样保证消息一定被消费,但有可能重复。(听了EP的分享好像目前使用的是这种)
Exactly once—确保消费并且确保只消费一次,这种是最理想的状态(同时处理消息并把result和log同时写入)。
存储策略:
1)kafka以topic来进行消息管理,每个topic包含多个partition,每个partition对应一个逻辑log,有多个segment组成。
2)每个segment中存储多条消息,消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
3)每个part在内存中对应一个index,记录每个segment中的第一条消息偏移。
4)发布者发到某个topic的消息会被均匀的分布到多个partition上(或根据用户指定的路由规则进行分布),broker收到发布消息往对应partition的最后一个segment上添加该消息,当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到,segment达到一定的大小后将不会再往该segment写数据,broker会创建新的segment。
上面这四条是标准的一个叙述,我想针对其中两点进行说明:
1. partition路由分配规则:一种是轮询方式,这样会保证消息分部均匀,但是没有逻辑上的区分;另外一种是指定路由规则(比如hash方法),这样可以进行一定的映射,如将统一用户的分到一片等等。
2.持久化方式:log分为.index和.log文件,文件都会有一个offset偏移量,记得听人分享过,使用了linux内核sendFile函数直接进行随机写的操作,提高了效率。
另外,关于Kafka与ZK的协调配置还需要我去学习(不过好像kafka的新版本offset是保存在自己服务器上的,不借助zk来保存)。
来了公司发现很多东西都停留理论层面,需要学习和实践的还有很多,希望自己能不断进步吧。
以上是关于由内搜推送思考Kafka 的原理的主要内容,如果未能解决你的问题,请参考以下文章