Kafka技术原理
Posted Hadoop大数据之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka技术原理相关的知识,希望对你有一定的参考价值。
一、整体架构
1、消息的发布(publish)简称producer,消息的订阅(subscribe)称为consumer,中间的存储阵列称为broker。
2、多个broker协同合作,producer、broker和consumer三者通过zookeeper来协调请求和转发。
3、producer生产和推送(push)到broker,consumer从broker拉取(pull)数据并行处理。
4、broker端不维护数据的消费状态,提高broker的TPS;
5、直接使用磁盘进行存储,线性读写,速度快,避免了数据在JVM内存和系统内存之间的复制,减少耗性能的创建对象和垃圾回收。
6、Kafka使用scala编写,可以运行在JVM上。
二、术语
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker。一台Kafka服务器就是一个broker,一个broker可以容纳多个topic。
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上,但是用户只需要指定消息的Topic即可生产或消费数据不必关心数据存于何处。
Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition。
Producer
负责发布消息到Kafka broker。
Consumer
消息消费者,向Kafka broker读取消息的客户端。
Consumer Group
每个consumer属于一个特定的Consumer Group(可为每个consumer指定group name,若不指定group name则属于默认的group)。各个consumer可以组成一个组,每个消息只能被组中的一个consumer消费,如果一个消息可以被多个consumer消费的话,那么这些consumer必须在不同的组。
Offset
Kafka的存储文件都是按照offset.kafka来命名,好处是方便查找。
Replica
partition的副本,保障partition的高可用。
Leader
replica中的一个角色,producer和consumer只能跟leader交互。
Follower
replica中的一个角色,从leader中复制数据。
三、技术原理
1、Topics/logs
一个topic可认为是一类消息,每个topic将被分成多个partition(分区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标识一条消息。Kafka并没有提供其它额外的索引机制来存储offset,因为Kafka不允许对消息进行“随机读写”。
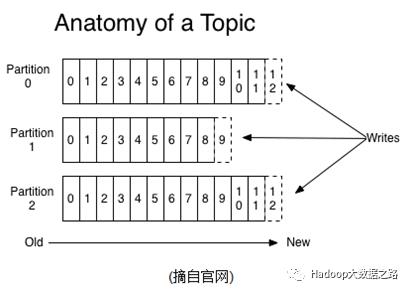
Kafka和JMS(Java Message Service)都实现了activeMQ,不同的是:即使消息被消费,消息仍然不会被立即删除,日志文件将会根据broker中的配置要求,保留一定的时间之后删除。
对于consumer而言,它需要保存消费消息的offset,对于offset的保存和使用由consumer来控制;当consumer正常消费消息时,offset将会线性向前驱动,即消息将依次顺序被消费,事实上consumer可以使用任意顺序消费消息,只需要将offset重置为任何值。
Kafka集群不维护任何consumer和producer状态信息,这些信息由Zookeeper保存,因此producer和consumer的实现是非常轻量级,它们可以随意离开,而不会对集群造成额外的影响。
partition的设计目的有多个,最根本原因是Kafka基于文件存储,通过分区可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partition都会被当前server(Kafka实例)保存,可以将一个topic切分任意多个partitions来提高消息保存/消费的效率,此外越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力。
2、Distribution
一个Topic的多个partitions被分布在Kafka集群中的多个server上,每个server(Kafka实例)负责partitions中消息的读写操作,此外Kafka还可以配置partitions需要备份的个数(replica),每个partition将会备份到多台机器上以提高可用性。
基于replicated方案,那么就意味着需要对多个备份进行调度,每个partition都有一个server为“leader”,leader负责所有的读写操作,如果leader失败,那么将会有其它follower来接管成为新的leader,follower只是单调的和leader跟进,同步消息即可,由此可见,作为leader的server承载了全部的请求压力,从集群的整体考虑,有多少个partitions就意味着有多少个“leader”,Kafka会将“leader”均衡分散在每个实例上,来确保整体的性能稳定。
3、Producers
producer将消息发布到指定的Topic中,同时producer也能指定将此消息归属于那个partition。
4、Consumers
本质上Kafka只支持Topic,每个consumer属于一个consumer group,反过来说,每个group中可以有多个consumer,发送到topic的消息,只会被订阅到此topic的每个group的一个consumer消费。
如果所有的consumer都具有相同的group,这种情况和queue模式很像,消息将会在consumers之间负载均衡。如果所有的consumer都具有不同的group,那这就是“发布”-“订阅”,消息将会广播给所有的消费者。
在Kafka中,一个partition中的消息只会被group中的一个consumer消费,每个group中consumer消息消费相互独立,可以认为一个“group”是一个订阅者,一个topic中的每个partitions只会被一个“订阅者”中的一个consumer消费,不过一个consumer可以消费多个partitions中的数据。Kafka只能保证一个partition中的消息被某个consumer消费时,消息是顺序的,事实上,从Topic角度来看,消息仍不是有序的。Kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
5、消息传送机制
1)at most once:最多一次,发送一次,无论成败,将不会重发。消费者fetch消息,先保存offset,然后处理消息,当client保存offset后,但是在消息处理过程中出现异常导致部分消息未能继续处理,那么此后“未处理”的消息将不能被fetch到。
2)at least once:消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功。消费者fetch消息,先处理消息,然后保存offset,如果消息处理成功,但是在保存offset阶段由于Zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,原因offset没有及时的提交给Zookeeper,Zookeeper恢复正常还是之前的offset状态。
3)exactly once:消息只会发送一次。Kafka中并没有严格地去实现。
四、参数配置说明

五、性能调优
1、设置vm.swappiness为较小值(swap机制)
计算机的内存分为虚拟内存和物理内存,物理内存是真实的内存,虚拟内存是用磁盘来代替内存,通过swap机制实现磁盘到物理内存的加载和替换。在写文件的时候,Linux首先将数据写入没有被使用的内存中,这些内存被称为内存页(page cache),然后读的时候,Linux会优先从page cache中查找,如果找不到就会从磁盘中查找。当物理内存使用达到一定的比例后,Linux就会进行swap,使用磁盘作为虚拟内存。通过cat /proc/sys/vm/swappiness可以看到swap参数,这个参数表示swap磁盘代替的虚拟内存占了多少百分比。0表示最大限度的使用内存,100表示使用swap磁盘。系统默认的参数60,当物理内存使用率达到40%,就会频繁进行swap,影响系统性能,推荐将vm.swappiness设置为较低值1。
2、提高partition个数
Kafka是一个高吞吐量分布式消息系统,其高性能有两个特点:1)利用磁盘连续读写性高于随机读写;2)并发,将一个topic拆分多个partition。因此,将一个topic拆分为多个partition可以提高吞吐量,但有个前提就是partition需要位于不同磁盘,如果多个partition位于同一个磁盘,那么意味着有多个进程同时对一个磁盘的多个文件进行读写,使得操作系统会对磁盘读写进行频繁调度,也就是破坏磁盘读写的连续性。
3、挂盘优于磁盘阵列,小块盘优于大块盘
充分利用多磁盘并发读写,又能保证每个磁盘连续读写的特性。
4、JVM参数优化
推荐使用最新的G1来代替CMS作为垃圾回收器。G1是一种适用于服务器端的垃圾回收器,很好地平衡了吞吐量和响应能力。
5、Producer优化
提高message的缓冲区大小;默认发送不进行压缩,推荐配置一种适合的压缩算法;
6、Broker参数优化
1)网络和IO操作线程配置优化
# broker处理消息的最大线程数
num.network.threads=xxx
# broker处理磁盘IO的线程数
num.io.threads=xxx
num.network.threads用于接收并处理网络请求的线程数,默认为3。其内部实现是采用selector模型,启动一个线程作为acceptor来负责建立连接,再配合启动num.network.threads个线程来轮流负责从socket读取请求,一般无需改动,除非上下游并发请求量过大。一般num.network.threads主要处理网络io,读写缓冲区数据,基本没有io等待,配置线程数量为CPU核数加1。num.io.threads主要进行磁盘io操作,高峰期可能有些io等待,因此配置需要大些,配置线程数量为CPU核数2倍,最大不超过3倍。
2)log数据文件刷盘策略
为了提高producer写入吞吐量,需要定期批量写文件。
log.flush.interval.messages=10000
log.flush.interval.ms=1000
3)日志保存策略
根据实际应用及数据增长速率调整磁盘数据过期时间。
log.retention.hours=72
log.segment.bytes=1073741824
4)配置jmx服务
Kafka server中默认是不启动jmx端口的,需要用户配置。
vim bin/kafka-run-class.sh
#最前面添加一行 JMX_PORT=8060
5)Replica相关配置
replica.lag.time.max.ms=10000
replica.lag.max.messages=4000
num.replica.fetchers=1
default.replication.factor=1
在Replica上会启动若干Fetch线程把对应的数据同步到本地,而num.replica.fetchers这个参数是用来控制Fetch线程的数量;Replica过少会影响数据的可用性,太多则会白白浪费存储资源,一般建议在2~3为宜。
6)分区数量
num.partitions=1
分区数影响topic并发读写的线程数,通常设置为磁盘数来提高Kafka的吞吐量。
以上是关于Kafka技术原理的主要内容,如果未能解决你的问题,请参考以下文章