Kafka技术之旅Kafka的基本原理及介绍
Posted 浩宇天尚/Alex
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka技术之旅Kafka的基本原理及介绍相关的知识,希望对你有一定的参考价值。
kafka架构与原理
Kafka的介绍和历史
-
Kafka是最初由Linkedin公司开发,是一个分布式(Distribute)、分区(Partition)的、多副本(Replica)的、多生产者(Producer)、多订阅者(Consumer)。
-
最初是基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
Kakfa的概念和定义
- 【Kafka】是一个分布式的基于发布/订阅模式的消息队列(message queue),主要应用于大数据的实时处理领域,它可以让你发布和订阅记录流。在这方面,它类似于一个消息队列或企业消息系统,它可以让你持久化收到的记录流,从而具有容错能力。
Kafka的主要应用场景
日志收集系统和消息系统。
-
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer;
-
消息系统:解耦生产者和消费者、缓存消息等;
-
用户活动跟踪:kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后消费者通过订阅这些topic来做实时的监控分析,亦可保存到数据库;
-
运营指标:kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
-
流式处理:推荐系统或者推荐新闻文章的处理管道,我们可以将从RSS提要中抓取文章的内容,然后将内容发布到文章的主题中,有兴趣可以了解Apache Kafka官网查看,它从0.10.0.0开始,提供了一个轻量级流处理库Kafka Streams,是用于执行上的数据处理的,这个功能非常的强大。流处理还有storm、samza、flink。
-
检测数据:Kafka可以作为检测数据,比如分布式应用程序中的聚合统计数据,然后我们统一集中处理。
Kafka的基本特性
首先,明确几个概念:
-
分布式部署:Kafka运行在一个或多个服务器,分布式系统,易于向外扩展,所有的producer、broker和consumer都会有多个,均为分布式的,无需停机即可扩展机器。
-
持久化特性:将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。通过将数据持久化到硬盘以及replication防止数据丢失。
-
存储的方式:Kafka集群分类存储的记录流被称为主题,其实是以分区为单位。
-
消息的结构:Kafka每个消息记录包含一个键(key),一个值(value)和时间戳(timestamp)。
-
高性能吞吐量:Kafka服务同时为发布和订阅提供高吞吐量:据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
-
自处理特性:消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡(Rebalance)。支持online和offline的场景。
Kafka的设计目标
-
时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
-
高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒10万条消息的传输。
-
支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
-
同时支持离线数据处理和实时数据处理。
-
支持在线水平扩展。
Kafka的基础架构
-
Kafka的整体架构非常简单,是显式分布式架构,producer、broker和consumer。
-
kafka的架构是可以有多个Producer,consumer实现Kafka注册的接口。
-
数据从producer发送到broker。
-
broker承担一个中间缓存和分发的作用,即活跃的数据和离线处理系统之间的缓存。
-
broker分发注册到系统中的consumer。
-
客户端和服务器端的通信,是基于简单,高性能,且与编程语言无关的TCP协议。
-

- 有两种主要的消息传递模式:点对点传递模式、发布-订阅模式。大部分的消息系统选用发布-订阅模式。Kafka就是一种发布-订阅模式。
Kafka的总体架构
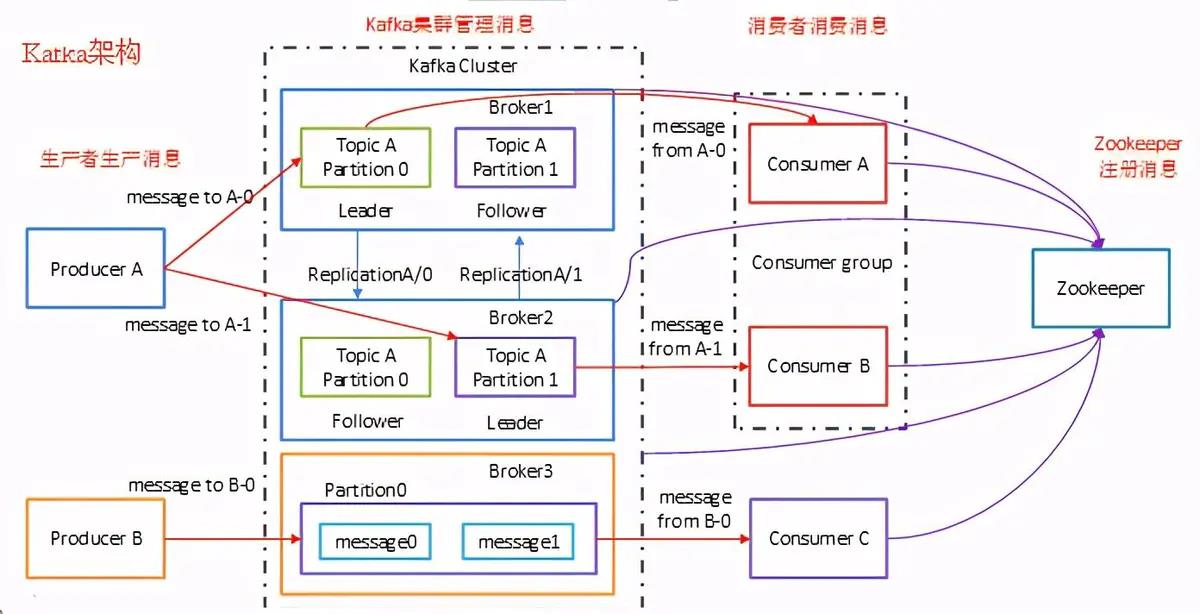
Kafka成员的基础概念
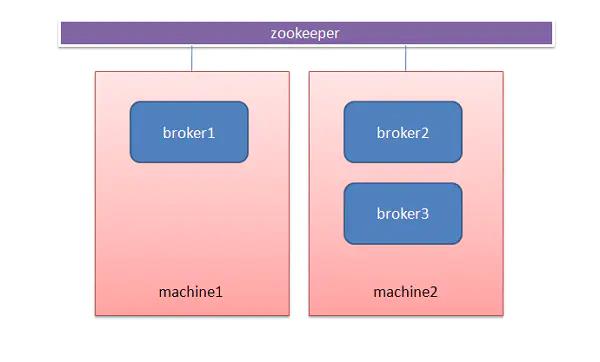
Broker(服务节点)
Kafka集群中的一台或多台服务器统称为broker,多个broker组成kafka组,主要负责缓存代理,一个机器上可以部署一个或者多个broker,这多个broker连接到相同的Zookeeper就组成了Kafka集群,如下图所示。
Topic(主题)
主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务,这里的逻辑容器可以看做是消息的类别,我们将同一类的消息放在一个Topic,特指Kafka处理的消息源(feeds of messages)的不同分类。
Topic与broker的关系
一个Broker上可以创建一个或者多个Topic。同一个topic可以在同一集群下的多个Broker中分布。
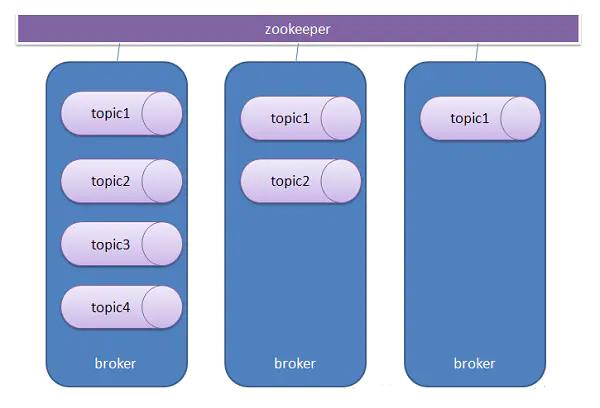
Topic只是一个逻辑组件,真正在Broker间分布式的Partition。
Partition(分区)
-
分区是物理上的分组,Kafka会为每个topic维护了多个分区(partition),每个partition是一个有序的队列。
-
分区会给每个消息记录分配一个顺序ID号 – 偏移量(Offset),能够唯一地标识该分区中的每个记录。,每个分区会映射到一个逻辑的日志(log)文件。
-
partition属于不可变的消息序列,新的消息不断追加到这个有组织的有保证的日志上。
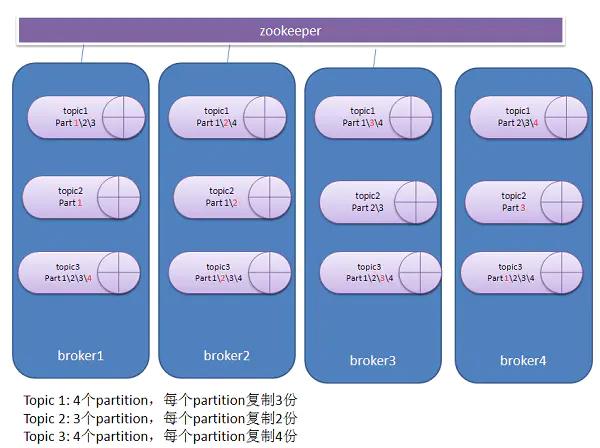
Kafka集群中按照主题分类管理,一个主题可以有多个分区,一个分区可以有多个副本分区。
Message(消息)
-
消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。
-
消息的结构:Kafka每个消息记录包含一个键(key),一个值(value)和时间戳(timestamp)。
Producer(生产者)
消息和数据生产者,向Kafka的一个topic发布消息的过程叫做生产消息。
发送消息流程
-
producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里。
-
kafka集群接收到Producer发过来的消息后,将其持久化到硬盘,并保留消息指定时长(可配置),而不关注消息是否被消费。
Consumer(消费者)
-
从kafka集群pull数据,并控制获取消息的offset。
-
消息和数据消费者,订阅topics并处理其发布的消息的过程叫做consumers。
-
对于消息中间件,消息分推拉两种模式。Kafka只有消息的拉取,没有推送,可以通过轮询实现消息的推送。
Consumer Group (消费组)
-
Consumer group下有多个Consumer(消费者),顾名思义其实就是一组消费者,将消费者组织在一个组下,便于管理对于每个消费者组 (Consumer Group),Kafka都会为其分配一个全局唯一的Group ID,Group内部的所有消费者共享该ID。
-
订阅的topic下的每个分区只能分配给某个group下的一个consumer(当然该分区还可以被分配给其他group)。同时,Kafka为每个消费者分配一个Consumer ID,通常采用"Hostname:UUID"形式表示。
Kafka的四个核心API
-
Producer API:允许应用程序将记录流发布到一个或多个Kafka主题。
-
Consumer API:允许应用程序订阅一个或多个主题并处理为其生成的记录流。
-
Streams API:允许应用程序充当流处理器,使用一个或多个主题的输入流,并生成一个或多个输出主题的输出流,从而有效地将输入流转换为输出流。
-
Connector API:允许构建和运行将Kafka主题连接到现有应用程序或数据系统的可重用生产者或使用者。例如,关系数据库的连接器可能会捕获对表的所有更改。
Kafka的客户端和服务器之间的通信是靠一个简单的,高性能的,与语言无关的TCP协议完成的。这个协议有不同的版本,并保持向前兼容旧版本。Kafka不光提供了一个Java客户端,还有许多语言版本的客户端。
核心优势
-
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒;
-
可扩展性:kafka集群支持热扩展;
-
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
-
容错性:允许集群中节点故障(若副本数量为n,则允许n-1个节点故障);
-
高并发:支持数千个客户端同时读写。
以上是关于Kafka技术之旅Kafka的基本原理及介绍的主要内容,如果未能解决你的问题,请参考以下文章