CVICML2015_Unsupervised Learning of Video Representations using LSTMs
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CVICML2015_Unsupervised Learning of Video Representations using LSTMs相关的知识,希望对你有一定的参考价值。
Unsupervised Learning of Video Representations using LSTMs
Note here: it‘s a learning notes on new LSTMs architecture used as an unsupervised learning way of video representations.
(More unsupervised learning related topics, you can refer to:
Learning Temporal Embeddings for Complex Video Analysis
Unsupervised Learning of Visual Representations using Videos
Unsupervised Visual Representation Learning by Context Prediction)
Link: http://arxiv.org/abs/1502.04681
Motivation:
- Understanding temporal sequences is important for solving many video related problems. We should utilize temporal structure of videos as a supervisory signal for unsupervised learning.
Proposed model:
In this paper, the author proposed three models based on LSTM:
1) LSTM Autoencoder Model:
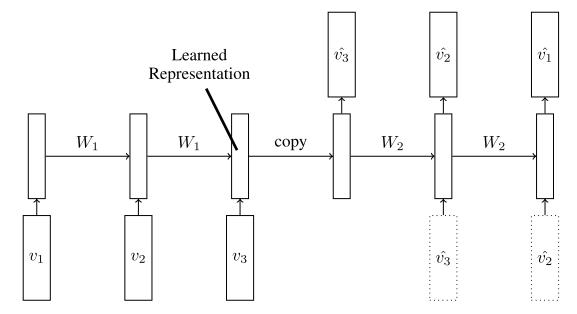
This model is composed of two parts, the encoder and the decoder.
The encoder accepts sequences of frames as input, and the learned representation generated from encoder are copied to decoder as initial input. Then the decoder should reconstruct similar images like input frames in reverse order.
(This is called unconditional version, while a conditional version receives last generated output of decoder as input, shown as the dashed boxes below)
Intuition: The reconstruction work requires the network to capture information about the appearance of objects and the background, this is exactly the information that we would like the representation to contain.
2) LSTM Future Predictor Model:
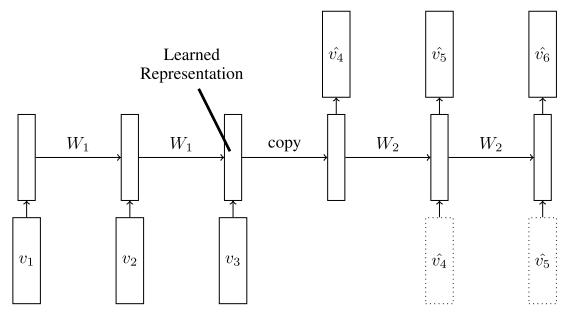
This model is similar with the one above. The main difference lies in the output. Output of this model is the prediction of frames that come just after the input sequences. It also varies with conditional/unconditional versions just like the description above.
Intuition: In order to predict the next few frames correctly, the model needs information about which objects are present and how they are moving so that the motion can be extrapolated.
3) A Composite Model:
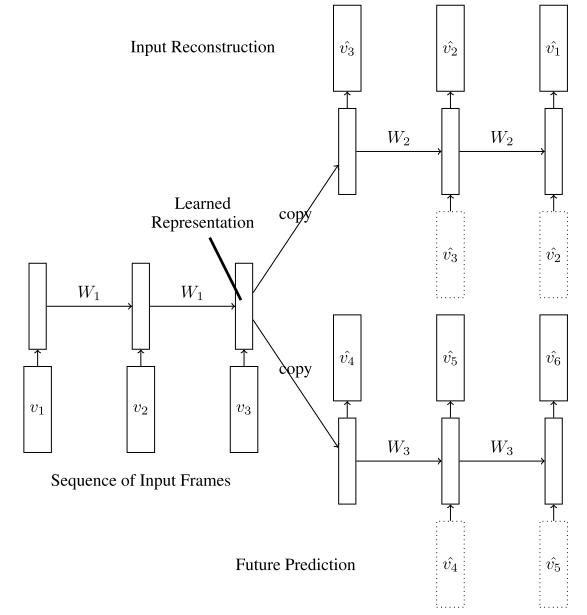
This model combines "input reconstruction" and "future prediction" together to form a more powerful model. These two modules share a same encoder, which encodes input sequences into a feature vector and copy them to different decoders.
Intuition: this only encoder learns representations that contain not only static appearance of objects&background, but also the dynamic informations like moving objects and their moving pattern.
以上是关于CVICML2015_Unsupervised Learning of Video Representations using LSTMs的主要内容,如果未能解决你的问题,请参考以下文章
cvpr2019_Unsupervised Person Re-identification by Soft Multilabel Learning
论文导读Towards Unsupervised Domain Generalization
A Probabilistic Formulation of Unsupervised Text Style Transfer