笔记:unsupervised domain adaptation by backpropagation
Posted 泡温水澡的青蛙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了笔记:unsupervised domain adaptation by backpropagation相关的知识,希望对你有一定的参考价值。
这篇文章是结合对抗网络框架与深度学习技术解决domain adaptation应用的一个工作。具体而言,在这个框架中对三个部分进行训练:一个是feature extractor,这个是用于提取特征的,一般由卷积层与pooling层组成;另一个是label classifier,使用全连接层+逻辑斯蒂分类器;第三个在一般的分类器中不会出现,也就是和feature extractor构成对抗网络框架的分类器domain classifier,它也是一个分类器,由全连接层+交叉熵分类器构成。其中全连接层的激活函数都是relu函数。对抗体现在对于domain classifier损失在训练阶段两个相反的要求。具体而言:对于domain adaptation应用,我们希望网络学到的特征表示具有领域不变(domain invariant)的特征,那么就要求dimain classifier不能正确进行领域分类,也就是要求domain classifier的分类损失最大;另一方面在对domain classifier训练时,我们肯定要求分类器能尽可能的正确分类,也就是domain classifier的分类损失最小。这种对抗的框架最早出现在Goodfellow的文章Generative adversarial networks,它针对的应用是图像生成,为了训练一个生成模型学习样本的分布,在框架中引入了一个判别模型用于区分样本是由模型生成还是来源于真实分布,感兴趣的可以仔细看那篇文章的框架。下面给出这篇文章的框架。
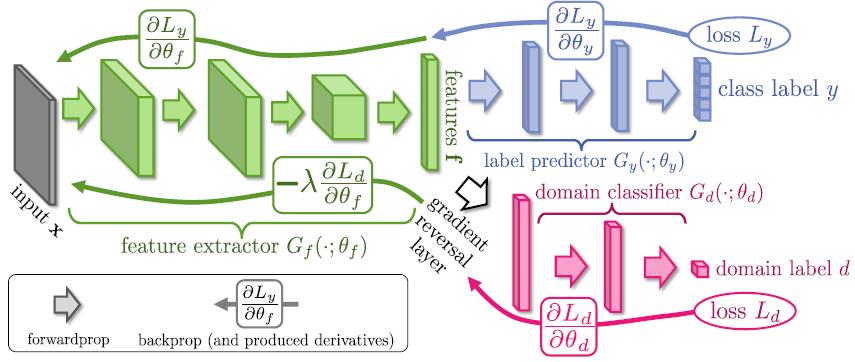
其中绿色部分是feature extractor;蓝色部分是label classifier;红色部分是domain classifier
下面从模型以及优化算法两个方面来介绍这篇文章。
一、模型
首先来介绍模型的构成及其关系。
domain adaptation的应用中有两个域:一个包含大量的标签信息,称为源域(source domain);另一个只有少量的甚至没有标签,但是却包含我们要预测的样本 ,称为目标域(target domain)。所以,按照常理,我们可以在源域上通过一般的机器学习方法来训练得到判别模型。但是由于源域和目标域上的dataset bias,这个判别模型不能直接移植到目标域。如何在尽量不损失判别模型的条件下将判别模型由源域迁移到目标域,就是domain adaptation要解决的问题,也称为迁移学习(transfer learning)。关于这个问题,一般有shared-classifier假设:如果可以在源域和目标域上,学习到一个公共的特征表示空间,那么在这个特征空间上,源域特征上学到的判别模型也可以用到目标域的特征上。所以domain adaptation问题往往转换为寻找公共特征表示空间的问题,也就是学习域不变特征(domain invariant feature)。本文就是利用对抗网络的框架来学习域不变特征。
具体而言,如果学习得到一个domain classifier,它能对不同域进行区分。学习不变特征的假设就是,在训练好的domain classifier上,如果不同域上的特征在这个分类器上不能区分,也就是这个分类器的分类损失很大, 那么这个特征就可以看作是不变特征。一个极端的例子是如果源域和目标域在这个空间上完全重合,那么所有的domain classifier按照常理都会失效,都相当于一个随机分类器的效果。
另一方面,对于label classification,我们要让学到的特征尽可能具有label的分类判别信息,也就是最小化label classifier的分类损失。
实际上在训练domain classifier的时候要求它的分类损失最小化,而要求得到不变特征,要求分类损失最大化,这是一个互相对抗的要求,可以表示如下:
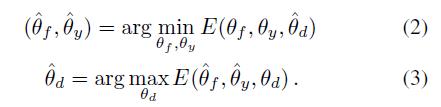
其中:
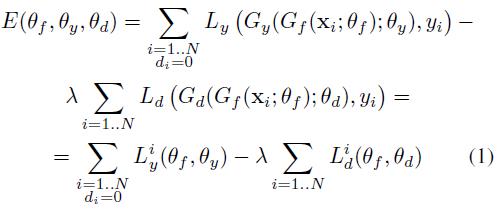
其中theta_f表示特征提取的参数,theta_y表示label classifier的分类器,theta_d表示domain classifier的参数,L_y表示label classifier的分类器,L_d表示domain classifier的分类器。N代表所有样本的数目,d_i代表域标签,0代表源域。
下面介绍如何在标准的梯度下降法中优化这个函数。
二、优化
针对上面(2)和(3)中的问题,可以用下面的方法对网络参数进行更新:
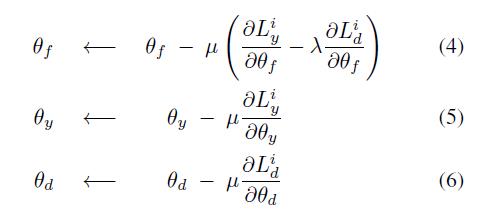
这个区别于对抗网络中的固定一个更新另一个的过程,在一个循环里面对网络参数同时进行更新。其中mu是学习的速度,lambda表示一个超参数。如果不使用lambda参数,作者表明会使得训练得到的特征最小化domain classifier loss,也就是不能学到域不变的特征。
为了使上面的式子符合标准的方向传播的表示,作者定义了一个中间函数,它在前向和反向过程中有两个不等价的表现形式:
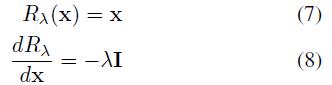
对应的损失函数表示为:
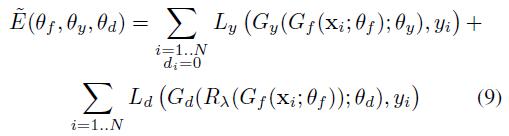
这样就可以用标准的SGD方法进行反向传播。
以上是关于笔记:unsupervised domain adaptation by backpropagation的主要内容,如果未能解决你的问题,请参考以下文章