Machine Learning——DAY1
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Machine Learning——DAY1相关的知识,希望对你有一定的参考价值。
监督学习:分类和回归
非监督学习:聚类和非聚类
1.分类和聚类的区别:
分类(Categorization or Classification)就是按照某种标准给对象贴标签(label),再根据标签来区分归类。
聚类是指事先没有“标签”而通过某种成团分析找出事物之间存在聚集性原因的过程。
2.回归和分类的区别:
当我们试图预测的目标变量是连续的时,例如在我们的住房例子中,我们把学习问题称为回归问题。当y只能取一小部分离散值时(例如,考虑到居住区域,我们想预测一个住宅是房子还是公寓),我们称之为分类问题。
单个特征:
成本函数:
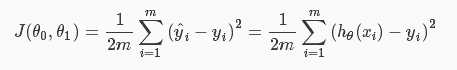
的添加是为了以后便于计算
梯度下降法:
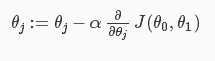

学习速率ɑ选择不能太大也不能太小。
拿线性回归拟合为例,则梯度下降过程如下:
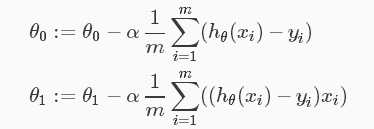
多个特征
hypothesis function(假设函数)
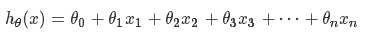
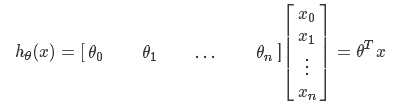
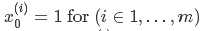 :可理解为第i个样本的第0个属性值为1,这样设置是为了便于θ’和X的矩阵运算
:可理解为第i个样本的第0个属性值为1,这样设置是为了便于θ’和X的矩阵运算
(试着将θ理解为平衡各个特征的权重)

(统计学习方法.李航中上标下标表示的意思与这里相反)
梯度下降法:
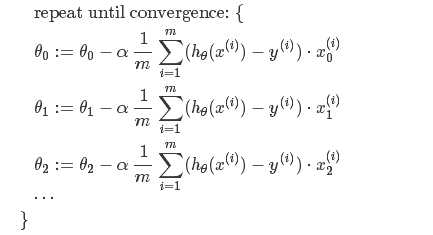
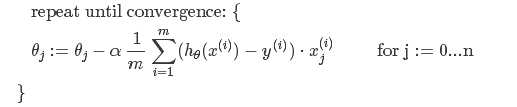
Feature Scaling(特征缩放):
它可以使得梯度下降的速度加快从而优化梯度下降法
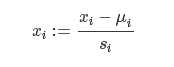
μi表示所有样本的第i个属性(特征)的平均值
Si表示所有样本第i个属性(特征)中(最大值-最小值),或者叫standard deviation(标准差)
Polynomial Regression(多项式回归)
当数据用线性拟合不太好时可以考虑用多项式回归,例如二次三次多项式甚至平方根
正规方程法
Normal Equations 的由来
假设我们有m个样本。特征向量的维度为n。因此,可知样本为{(x(1),y(1)), (x(2),y(2)),... ..., (x(m),y(m))},其中对于每一个样本中的x(i),都有x(i)={x1(i), xn(i),... ...,xn(i)}。令 H(θ)=θ0 + θ1x1 +θ2x2+... + θnxn,则有

若希望H(θ)=Y,则有
X · θ = Y
我们先来回忆一下两个概念:单位矩阵 和 矩阵的逆,看看它们有什么性质。
(1)单位矩阵E
AE=EA=A
(2)矩阵的逆A-1
要求:A必须为方阵
性质:AA-1=A-1A=E
再来看看式子 X · θ = Y
若想求出θ,那么我们需要做一些转换:
step1:先把θ左边的矩阵变成一个方阵。通过乘以XT可以实现,则有
XTX · θ = XTY
step2:把θ左边的部分变成一个单位矩阵,这样就可以让它消失于无形了……
(XTX)-1(XTX) · θ = (XTX)-1XTY
step3:由于(XTX)-1(XTX) = E,因此式子变为
Eθ = (XTX)-1XTY
E可以去掉,因此得到
θ = (XTX)-1XTY
这就是我们所说的Normal Equation了。
Normal Equation VS Gradient Descent
Normal Equation 跟 Gradient Descent(梯度下降)一样,可以用来求权重向量θ。但它与Gradient Descent相比,既有优势也有劣势。
优势:
Normal Equation可以不在意x特征的scale。比如,有特征向量X={x1, x2}, 其中x1的range为1~2000,而x2的range为1~4,可以看到它们的范围相差了500倍。如果使用Gradient Descent方法的话,会导致椭圆变得很窄很长,而出现梯度下降困难,甚至无法下降梯度(因为导数乘上步长后可能会冲出椭圆的外面)。但是,如果用Normal Equation方法的话,就不用担心这个问题了。因为它是纯粹的矩阵算法。
劣势:
相比于Gradient Descent,Normal Equation需要大量的矩阵运算,特别是求矩阵的逆。在矩阵很大的情况下,会大大增加计算复杂性以及对计算机内存容量的要求。
什么情况下会出现Normal Equation不可逆,该如何应对?
(1)当特征向量的维度过多时(如,m <= n 时)
解决方法:① 使用regularization方式
or ②delete一些特征维度
(2)有redundant features(也称为linearly dependent feature)
例如, x1= size in feet2
x2 = size in m2
feet和m的换算为 1m≈3.28feet所以,x1 ≈ 3.282 * x2, 因此x1和x2是线性相关的(也可以说x1和x2之间有一个是冗余的)
解决方法:找出冗余的特征维度,删除之。
梯度下降法和正规方程法的优劣比较:

以上是关于Machine Learning——DAY1的主要内容,如果未能解决你的问题,请参考以下文章
COMPSCI 361 Machine Learning 重点解析