unordered_map 与 map 的对比(转)
Posted 鸭子船长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了unordered_map 与 map 的对比(转)相关的知识,希望对你有一定的参考价值。
unordered_map和map类似,都是存储的key-value的值,可以通过key快速索引到value。不同的是unordered_map不会根据key的大小进行排序,
存储时是根据key的hash值判断元素是否相同,即unordered_map内部元素是无序的,而map中的元素是按照二叉搜索树存储,进行中序遍历会得到有序遍历。
所以使用时map的key需要定义operator<。而unordered_map需要定义hash_value函数并且重载operator==。但是很多系统内置的数据类型都自带这些,
那么如果是自定义类型,那么就需要自己重载operator<或者hash_value()了。
1.结论
结论:如果需要内部元素自动排序,使用map,不需要排序使用unordered_map
运行效率方面:unordered_map最高,而map效率较低但 提供了稳定效率和有序的序列。
占用内存方面:map内存占用略低,unordered_map内存占用略高,而且是线性成比例的。
需要无序容器,快速查找删除,不担心略高的内存时用unordered_map;有序容器稳定查找删除效率,内存很在意时候用map。
2.原理
map的内部实现是二叉平衡树(红黑树);hash_map内部是一个hash_table一般是由一个大vector,vector元素节点可挂接链表来解决冲突,来实现.
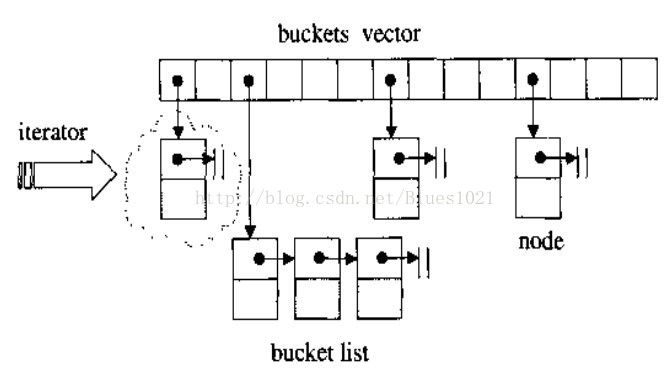
- 得到key
- 通过hash函数得到hash值
- 得到桶号(一般都为hash值对桶数求模)
- 存放key和value在桶内。
- 得到key
- 通过hash函数得到hash值
- 得到桶号(一般都为hash值对桶数求模)
- 比较桶的内部元素是否与key相等,若都不相等,则没有找到。
- 取出相等的记录的value。
3.性能特点
python中的map就是hashmap实现的,所以查询效率会比C++的map查询快。(java,python官方版的虚拟机都是用C语言实现的,所以内部的思想和方法都是通用的。)
若考虑有序,查询速度稳定,容器元素量少于1000,非频繁查询那么考虑使用map。
若非常高频查询(100个元素以上,unordered_map都会比map快),内部元素可非有序,数据大超过1k甚至几十万上百万时候就要考虑使用unordered_map(元素上千万上亿时4GB的内存就要担心内存不足了,需要数据库存储过程挪动到磁盘中)。
hash_map相比unordered_map就是千万级别以上内存占用少15MB,上亿时候内存占用少300MB,百万以下都是unordered_map占用内存少,
且unordered_map插入删除相比hash_map都快一倍,查找效率相比hash_map差不多,或者只快了一点约1/50到1/100。
综合非有序或者要求稳定用map,都应该使用unordered_map,set类型也是类似的。
unordered_map 查找效率快五倍,插入更快,节省一定内存。如果没有必要排序的话,尽量使用 hash_map(unordered_map 就是 boost 里面的 hash_map 实现)。
4.使用案例
map:
1 #include<string> 2 #include<iostream> 3 #include<map> 4 5 using namespace std; 6 7 struct person 8 { 9 string name; 10 int age; 11 12 person(string name, int age) 13 { 14 this->name = name; 15 this->age = age; 16 } 17 18 bool operator < (const person& p) const 19 { 20 return this->age < p.age; 21 } 22 }; 23 24 map<person,int> m; 25 int main() 26 { 27 person p1("Tom1",20); 28 person p2("Tom2",22); 29 person p3("Tom3",22); 30 person p4("Tom4",23); 31 person p5("Tom5",24); 32 m.insert(make_pair(p3, 100)); 33 m.insert(make_pair(p4, 100)); 34 m.insert(make_pair(p5, 100)); 35 m.insert(make_pair(p1, 100)); 36 m.insert(make_pair(p2, 100)); 37 38 for(map<person, int>::iterator iter = m.begin(); iter != m.end(); iter++) 39 { 40 cout<<iter->first.name<<"\\t"<<iter->first.age<<endl; 41 } 42 43 return 0; 44 }
输出为:(根据age进行了排序的结果)
Tom1 20
Tom3 22
Tom4 23
Tom5 24
因为Tom2和Tom3的age相同,由我们定义的operator<只是比较的age,所以Tom3覆盖了Tom2,结果中没有Tom2。
如果运算符<的重载是如下
1 bool operator < (const person &p)const{ 2 return this->name < p.name; 3 }
输出结果: 按照 那么进行的排序,如果有那么相同则原来的那么会被覆盖
Tom1 20
Tom2 22
Tom3 22
Tom4 23
Tom5 24
以上是关于unordered_map 与 map 的对比(转)的主要内容,如果未能解决你的问题,请参考以下文章