Spark机器学习:朴素贝叶斯算法
Posted 代码空间
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark机器学习:朴素贝叶斯算法相关的知识,希望对你有一定的参考价值。
1. 贝叶斯定理
条件概率公式:

这个公式非常简单,就是计算在B发生的情况下,A发生的概率。但是很多时候,我们很容易知道P(A|B),需要计算的是P(B|A),这时就要用到贝叶斯定理:
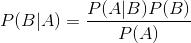
2. 朴素贝叶斯分类
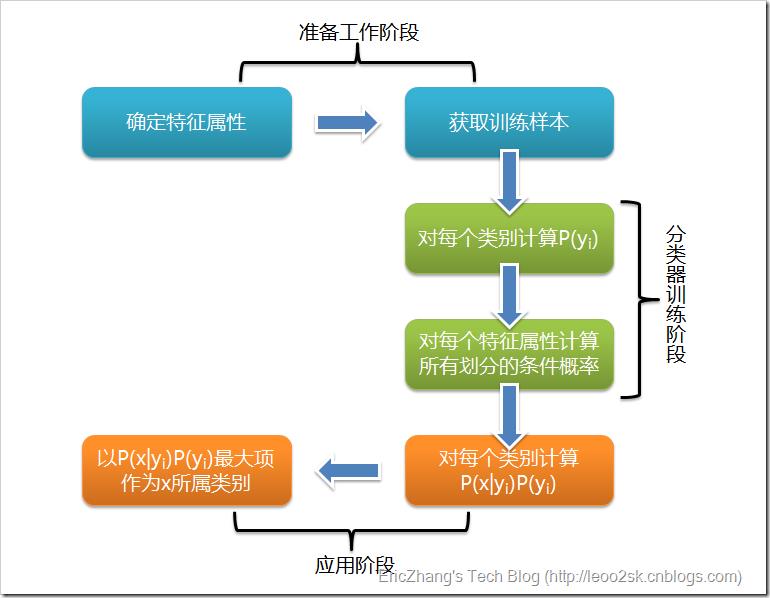
朴素贝叶斯分类的推导过程就不详述了,其流程可以简单的用一张图来表示:
举个简单的例子来说,下面这张表说明了各地区的人口构成:

这个时候如果一个黑皮肤的人走过来(一个待分类项(0,0,1)),他是来自欧美,亚洲还是非洲呢?可以根据朴素贝叶斯分类进行计算:
欧美=0.30×0.90×0.20×0.40=0.0216
亚洲=0.95×0.10×0.05×0.40=0.0019
非洲=0.90×1.00×0.90×0.20=0.1620
即他来自非洲的可能性最大,来自欧美的可能性次之,来自亚洲的可能性最小,那么我们就判断他来自非洲,这和我们日常生活中的经验是一致的。
如果特征属性是连续值,则按照下面的公式计算:


3. MLlib的贝叶斯分类
直接上代码:
import org.apache.log4j.{Level, Logger} import org.apache.spark.mllib.classification.NaiveBayes import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.mllib.regression.LabeledPoint import org.apache.spark.{SparkConf, SparkContext} object NaiveBayesTest { def main(args: Array[String]) { // 设置运行环境 val conf = new SparkConf().setAppName("Naive Bayes Test") .setMaster("spark://master:7077").setJars(Seq("E:\\\\Intellij\\\\Projects\\\\MachineLearning\\\\MachineLearning.jar")) val sc = new SparkContext(conf) Logger.getRootLogger.setLevel(Level.WARN) // 读取样本数据并解析 val dataRDD = sc.textFile("hdfs://master:9000/ml/data/sample_naive_bayes_data.txt") val parsedDataRDD = dataRDD.map { line => val parts = line.split(\',\') LabeledPoint(parts(0).toDouble, Vectors.dense(parts(1).split(\' \').map(_.toDouble))) } // 样本数据划分,训练样本占0.8,测试样本占0.2 val dataParts = parsedDataRDD.randomSplit(Array(0.8, 0.2)) val trainRDD = dataParts(0) val testRDD = dataParts(1) // 建立贝叶斯分类模型并训练 val model = NaiveBayes.train(trainRDD, lambda = 1.0, modelType = "multinomial") // 对测试样本进行测试 val predictionAndLabel = testRDD.map(p => (model.predict(p.features), p.label, p.features)) val showPredict = predictionAndLabel.take(50) println("Prediction" + "\\t" + "Label" + "\\t" + "Data") for (i <- 0 to showPredict.length - 1) { println(showPredict(i)._1 + "\\t" + showPredict(i)._2 + "\\t" + showPredict(i)._3) } val accuracy = 1.0 * predictionAndLabel.filter(x => x._1 == x._2).count() / testRDD.count() println("Accuracy=" + accuracy) } }
其中,NaiveBayes是贝叶斯分类伴生对象,train方法进行模型训练,三个参数分别是训练样本,平滑参数和模型类别。模型类别有两个:multinomial(多项式)和bernoulli(伯努利),这里使用的是multinomial。predict方法根据特征值进行判断分类。
运行结果:

以上是关于Spark机器学习:朴素贝叶斯算法的主要内容,如果未能解决你的问题,请参考以下文章