hash表
Posted 明耀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hash表相关的知识,希望对你有一定的参考价值。
1、哈希表概念
是根据关键码值(key,value)而直接进行访问的数据结构,把key值通过hash函数转换成一个整形数字,然后将该数字对数组长度取余,取余的结果当成数组的下标,value存储在以该数字为下标的数组空间里。
2、哈希表最常见的实现方法为拉链法如图所示:
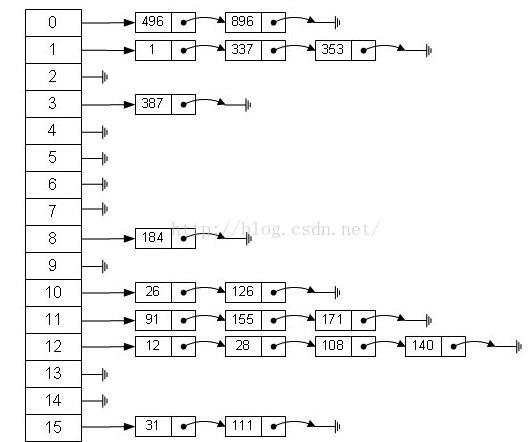
最左边的数组存储指针,每个指针指向一个链表的头。当通过hash函数获得的存储位置下标相同的,存在同一个链表了,数组该下标位置存储链表的头指针。
hash函数的构造方法:
1、直接定址法:
取关键字或关键字的某个线性函数值为哈希地址:H(key)=key 或 H(key)=a·key+b
其中a和b为常数,这种哈希函数叫做自身函数。
例:有一个从1岁到100岁的人口数字统计表,其中,年龄作为关键字,哈希函数取关键字自身。这样,若要询问25岁的人有多少,则只要查表的第25项即可。
由于直接定址所得地址集合和关键字集合的大小相同。因此,对于不同的关键字不会发生冲突。但实际中能使用这种哈希函数的情况很少。
2、 相乘取整法
该方法包括两个步骤:首先用关键字key乘上某个常数A(0<A<1),并抽取出key.A的小数部分;然后用m乘以该小数后取整。即:
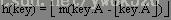
该方法最大的优点是m的选取比除余法要求更低。比如,完全可选择它是2的整数次幂。虽然该方法对任何A的值都适用,但对某些值效果会更好。Knuth建议选取

3、平方取中法
取关键字平方后的中间几位为哈希地址。
通过平方扩大差别,另外中间几位与乘数的每一位相关,由此产生的散列地址较为均匀。这是一种较常用的构造哈希函数的方法。
例:将一组关键字(0100,0110,1010,1001,0111)
平方后得(0010000,0012100,1020100,1002001,0012321)
若取表长为1000,则可取中间的三位数作为散列地址集:(100,121,201,020,123)。
4、折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址,这方法称为折叠法(folding)。
如国际标准图书编号0-442-20586-4的哈希地址分别如

5、除余法:
取关键字被数p除后所得余数为哈希地址:H(key)=keyMOD p (p≤m)
这是一种最简单,也最常用的构造哈希函数的方法。它不仅可以对关键字直接取模(MOD),也可在折迭、平方取中等运算之后取模。值得注意的是,在使用除留余数法时,对p的选择很重要。一般情况下可以选p为质数或不包含小于20的质因素的合数。
6、随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key)=random (key),其中random为随机函数。通常,当关键字长度不等时采用此法构造哈希函数较恰当。
冲突的解决
1)开放定址法
即当一个关键字和另一个关键字发生冲突时,使用某种探测技术在Hash表中形成一个探测序列,然后沿着这个探测序列依次查找下去,当碰到一个空的单元时,则插入其中。比较常用的探测方法有线性探测法,比如有一组关键字{12,13,25,23,38,34,6,84,91},Hash表长为14,Hash函数为address(key)=key%11,当插入12,13,25时可以直接插入,而当插入23时,地址1被占用了,因此沿着地址1依次往下探测(探测步长可以根据情况而定),直到探测到地址4,发现为空,则将23插入其中。
2)链地址法
采用数组和链表相结合的办法,将Hash地址相同的记录存储在一张线性表中,而每张表的表头的序号即为计算得到的Hash地址。(拉链法)
3)再哈希。就是当冲突时,采用另外一种映射方式来查找。
4)建立一个缓冲区,把凡是拼音重复的人放到缓冲区中。当我通过名字查找人时,发现找的不对,就在缓冲区里找。
以上是关于hash表的主要内容,如果未能解决你的问题,请参考以下文章