[转]Hash表
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[转]Hash表相关的知识,希望对你有一定的参考价值。
转自:http://www.cnblogs.com/dolphin0520/
Hash表
Hash表也称散列表,也有直接译作哈希表,Hash表是一种特殊的数据结构,它同数组、链表以及二叉排序树等相比较有很明显的区别,它能够快速定位到想要查找的记录,而不是与表中存在的记录的关键字进行比较来进行查找。这个源于Hash表设计的特殊性,它采用了函数映射的思想将记录的存储位置与记录的关键字关联起来,从而能够很快速地进行查找。
1.Hash表的设计思想
对于一般的线性表,比如链表,如果要存储联系人信息:
张三 13980593357
李四 15828662334
王五 13409821234
张帅 13890583472
那么可能会设计一个结构体包含姓名,手机号码这些信息,然后把4个联系人的信息存到一张链表中。当要查找”李四 15828662334“这条记录是否在这张链表中或者想要得到李四的手机号码时,可能会从链表的头结点开始遍历,依次将每个结点中的姓名同”李四“进行比较,直到查找成功或者失败为止,这种做法的时间复杂度为O(n)。即使采用二叉排序树进行存储,也最多为O(logn)。假设能够通过”李四“这个信息直接获取到该记录在表中的存储位置,就能省掉中间关键字比较的这个环节,复杂度直接降到O(1)。Hash表就能够达到这样的效果。
Hash表采用一个映射函数 f : key —> address 将关键字映射到该记录在表中的存储位置,从而在想要查找该记录时,可以直接根据关键字和映射关系计算出该记录在表中的存储位置,通常情况下,这种映射关系称作为Hash函数,而通过Hash函数和关键字计算出来的存储位置(注意这里的存储位置只是表中的存储位置,并不是实际的物理地址)称作为Hash地址。比如上述例子中,假如联系人信息采用Hash表存储,则当想要找到“李四”的信息时,直接根据“李四”和Hash函数计算出Hash地址即可。下面讨论一下Hash表设计中的几个关键问题。
1. Hash函数的设计
Hash函数设计的好坏直接影响到对Hash表的操作效率。下面举例说明:
假如对上述的联系人信息进行存储时,采用的Hash函数为:姓名的每个字的拼音开头大写字母的ASCII码之和。
因此address(张三)=ASCII(Z)+ASCII(S)=90+83=173;
address(李四)=ASCII(L)+ASCII(S)=76+83=159;
address(王五)=ASCII(W)+ASCII(W)=87+87=174;
address(张帅)=ASCII(Z)+ASCII(S)=90+83=173;
假如只有这4个联系人信息需要进行存储,这个Hash函数设计的很糟糕。首先,它浪费了大量的存储空间,假如采用char型数组存储联系人信息的话,则至少需要开辟174*12字节的空间,空间利用率只有4/174,不到5%;另外,根据Hash函数计算结果之后,address(张三)和address(李四)具有相同的地址,这种现象称作冲突,对于174个存储空间中只需要存储4条记录就发生了冲突,这样的Hash函数设计是很不合理的。所以在构造Hash函数时应尽量考虑关键字的分布特点来设计函数使得Hash地址随机均匀地分布在整个地址空间当中。通常有以下几种构造Hash函数的方法:
1)直接定址法
取关键字或者关键字的某个线性函数为Hash地址,即address(key)=a*key+b;如知道学生的学号从2000开始,最大为4000,则可以将address(key)=key-2000作为Hash地址。
2)平方取中法
对关键字进行平方运算,然后取结果的中间几位作为Hash地址。假如有以下关键字序列{421,423,436},平方之后的结果为{177241,178929,190096},那么可以取{72,89,00}作为Hash地址。
3)折叠法
将关键字拆分成几部分,然后将这几部分组合在一起,以特定的方式进行转化形成Hash地址。假如知道图书的ISBN号为8903-241-23,可以将address(key)=89+03+24+12+3作为Hash地址。
4)除留取余法
如果知道Hash表的最大长度为m,可以取不大于m的最大质数p,然后对关键字进行取余运算,address(key)=key%p。
在这里p的选取非常关键,p选择的好的话,能够最大程度地减少冲突,p一般取不大于m的最大质数。
2.Hash表大小的确定
Hash表大小的确定也非常关键,如果Hash表的空间远远大于最后实际存储的记录个数,则造成了很大的空间浪费,如果选取小了的话,则容易造成冲突。在实际情况中,一般需要根据最终记录存储个数和关键字的分布特点来确定Hash表的大小。还有一种情况时可能事先不知道最终需要存储的记录个数,则需要动态维护Hash表的容量,此时可能需要重新计算Hash地址。
3.冲突的解决
在上述例子中,发生了冲突现象,因此需要办法来解决,否则记录无法进行正确的存储。通常情况下有2种解决办法:
1)开放定址法
即当一个关键字和另一个关键字发生冲突时,使用某种探测技术在Hash表中形成一个探测序列,然后沿着这个探测序列依次查找下去,当碰到一个空的单元时,则插入其中。比较常用的探测方法有线性探测法,比如有一组关键字{12,13,25,23,38,34,6,84,91},Hash表长为14,Hash函数为address(key)=key%11,当插入12,13,25时可以直接插入,而当插入23时,地址1被占用了,因此沿着地址1依次往下探测(探测步长可以根据情况而定),直到探测到地址4,发现为空,则将23插入其中。
2)链地址法
采用数组和链表相结合的办法,将Hash地址相同的记录存储在一张线性表中,而每张表的表头的序号即为计算得到的Hash地址。如上述例子中,采用链地址法形成的Hash表存储表示为:
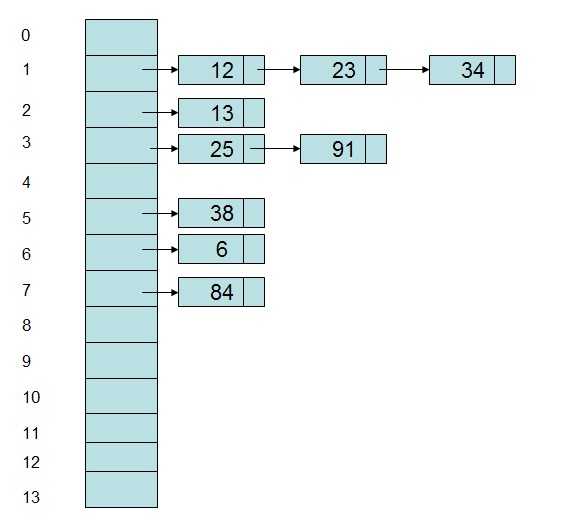
虽然能够采用一些办法去减少冲突,但是冲突是无法完全避免的。因此需要根据实际情况选取解决冲突的办法。
4.Hash表的平均查找长度
Hash表的平均查找长度包括查找成功时的平均查找长度和查找失败时的平均查找长度。
查找成功时的平均查找长度=表中每个元素查找成功时的比较次数之和/表中元素个数;
查找不成功时的平均查找长度相当于在表中查找元素不成功时的平均比较次数,可以理解为向表中插入某个元素,该元素在每个位置都有可能,然后计算出在每个位置能够插入时需要比较的次数,再除以表长即为查找不成功时的平均查找长度。
下面举个例子:
有一组关键字{23,12,14,2,3,5},表长为14,Hash函数为key%11,则关键字在表中的存储如下:
地址 0 1 2 3 4 5 6 7 8 9 10 11 12 13
关键字 23 12 14 2 3 5
比较次数 1 2 1 3 3 2
因此查找成功时的平均查找长度为(1+2+1+3+3+2)/6=11/6;
查找失败时的平均查找长度为(1+7+6+5+4+3+2+1+1+1+1+1+1+1)/14=38/14;
这里有一个概念装填因子=表中的记录数/哈希表的长度,如果装填因子越小,表明表中还有很多的空单元,则发生冲突的可能性越小;而装填因子越大,则发生冲突的可能性就越大,在查找时所耗费的时间就越多。因此,Hash表的平均查找长度和装填因子有关。有相关文献证明当装填因子在0.5左右的时候,Hash的性能能够达到最优。因此,一般情况下,装填因子取经验值0.5。
5.Hash表的优缺点
Hash表存在的优点显而易见,能够在常数级的时间复杂度上进行查找,并且插入数据和删除数据比较容易。但是它也有某些缺点,比如不支持排序,一般比用线性表存储需要更多的空间,并且记录的关键字不能重复。
代码实现:

/*Hash表,采用数组实现,2012.9.28*/
#include<stdio.h>
#define DataType int
#define M 30
typedef struct HashNode
{
DataType data; //存储值
int isNull; //标志该位置是否已被填充
}HashTable;
HashTable hashTable[M];
void initHashTable() //对hash表进行初始化
{
int i;
for(i = 0; i<M; i++)
{
hashTable[i].isNull = 1; //初始状态为空
}
}
int getHashAddress(DataType key) //Hash函数
{
return key % 29; //Hash函数为 key%29
}
int insert(DataType key) //向hash表中插入元素
{
int address = getHashAddress(key);
if(hashTable[address].isNull == 1) //没有发生冲突
{
hashTable[address].data = key;
hashTable[address].isNull = 0;
}
else //当发生冲突的时候
{
while(hashTable[address].isNull == 0 && address<M)
{
address++; //采用线性探测法,步长为1
}
if(address == M) //Hash表发生溢出
return -1;
hashTable[address].data = key;
hashTable[address].isNull = 0;
}
return 0;
}
int find(DataType key) //进行查找
{
int address = getHashAddress(key);
while( !(hashTable[address].isNull == 0 && hashTable[address].data == key && address<M))
{
address++;
}
if( address == M)
address = -1;
return address;
}
int main(int argc, char *argv[])
{
int key[]={123,456,7000,8,1,13,11,555,425,393,212,546,2,99,196};
int i;
initHashTable();
for(i = 0; i<15; i++)
{
insert(key[i]);
}
for(i = 0; i<15; i++)
{
int address;
address = find(key[i]);
printf("%d %d\\n", key[i],address);
}
return 0;
}
以上是关于[转]Hash表的主要内容,如果未能解决你的问题,请参考以下文章