(笔记)斯坦福机器学习第五讲--生成学习算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(笔记)斯坦福机器学习第五讲--生成学习算法相关的知识,希望对你有一定的参考价值。
本讲内容
1. Generative learning algorithms(生成学习算法)
2. GDA(高斯判别分析)
3. Naive Bayes(朴素贝叶斯)
4. Laplace Smoothing(拉普拉斯平滑)
1.生成学习算法与判别学习算法
判别学习算法:直接学习 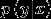 或者学习一个假设
或者学习一个假设 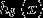 直接输出0或者1。logistic回归是判别学习算法的一个例子。
直接输出0或者1。logistic回归是判别学习算法的一个例子。
生成学习算法:对 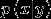 建模,即在给定所属的类别的情况下,对特征出现的概率建模。出于技术上的考虑,也会对
建模,即在给定所属的类别的情况下,对特征出现的概率建模。出于技术上的考虑,也会对 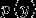 建模。
建模。
根据贝叶斯公式 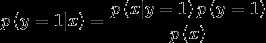 得到后验概率。
得到后验概率。
其中
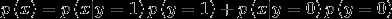
2.高斯判别分析
高斯判别分析属于生成学习算法
首先,高斯判别分析的两个假设:
(1).  , 且是连续值
, 且是连续值
(2). 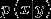 属于高斯分布
属于高斯分布
多元高斯分布
当一个随机变量z满足多元高斯分布时,
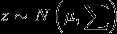
所以z的概率密度函数如下
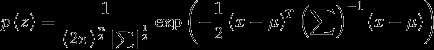
向量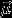 是高斯分布的均值,矩阵
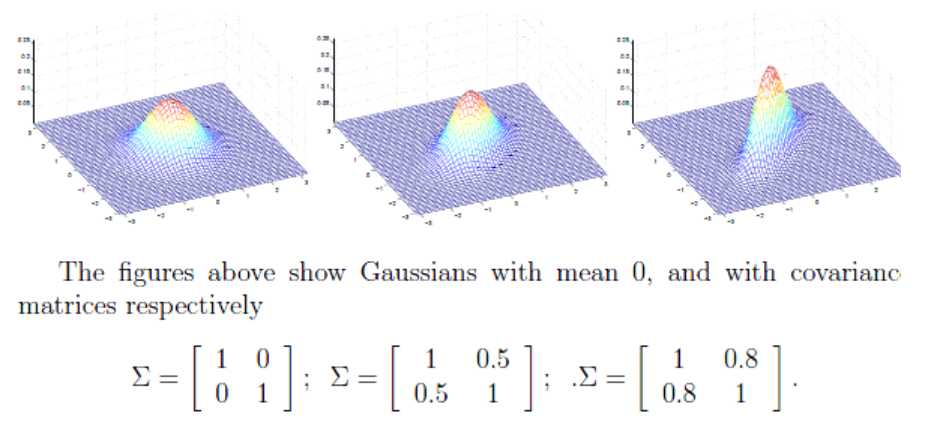
是高斯分布的均值,矩阵 是协方差矩阵,
是协方差矩阵,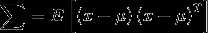
协方差矩阵对角线元素的值控制图像起伏的程度,反对角线元素的值控制图像起伏的方向。
均值控制图像中心的位置。
高斯判别分析模型
假设y服从伯努利分布,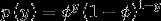
用高斯分布对 建模
建模
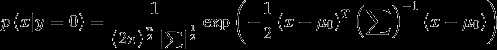
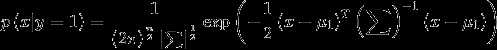
这个模型的参数为 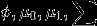
对这些参数作极大似然估计
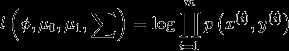
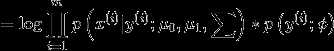
这个公式被称为joint likelihood(联合似然性)
对于判别学习算法,我们的参数似然性公式定义如下
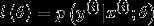
这个公式被称为conditional likelihood(条件似然性)
因此,对于生成学习算法,我们对参数的联合似然函数作极大似然估计
对于判别学习算法,我们对参数的条件似然函数作极大似然估计
对联合似然函数作极大似然估计,得到参数的值为
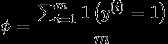
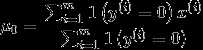
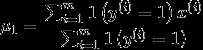
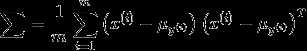
得到参数值之后, 对于一个新样本x,预测值为

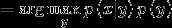
高斯判别分析和logistic回归的关系
假设 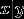 属于高斯分布,那么一定可以推出
属于高斯分布,那么一定可以推出 是一个logistic函数,但是反推不成立。
是一个logistic函数,但是反推不成立。
这说明,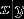 服从高斯分布的假设,要比
服从高斯分布的假设,要比 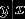 服从logistic分布的假设更强。
服从logistic分布的假设更强。
那么该如何权衡高斯判别分析模型和logistic回归模型呢?
GDA做出了一个更强的假设,即 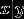 服从高斯分布,一旦这个假设正确或者近似正确,那么GDA算法的表现将会比logistic回归要好。
服从高斯分布,一旦这个假设正确或者近似正确,那么GDA算法的表现将会比logistic回归要好。
因为这个算法利用了更多数据的信息,算法知道数据服从高斯分布。
相反地,如果不确定 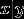 的分布情况,那么logistic回归将会表现的更好,logistic回归的弱假设使得logistic回归算法具有更好的鲁棒性,对不确定的数据分布依然能够得到一个较好的结果。
的分布情况,那么logistic回归将会表现的更好,logistic回归的弱假设使得logistic回归算法具有更好的鲁棒性,对不确定的数据分布依然能够得到一个较好的结果。
进一步,假设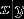 的分布属于指数分布簇,那么一定可以推出 是一个logistic函数,但是反推不成立。
的分布属于指数分布簇,那么一定可以推出 是一个logistic函数,但是反推不成立。
事实证明,使用生成学习算法的好处是,生成学习算法要比判别学习算法需要更少的数据,
即使在数据量特别小的情况下,生成学习算法依然能够拟合出一个还不错的模型。
3.朴素贝叶斯
朴素贝叶斯属于生成学习算法
对于一个垃圾邮件分类的问题,这是一个二分类的问题 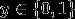
那么对于一封邮件,我们如何创建特征向量x?
普遍的做法是创建一个词典,假设该词典包含50000个单词,那么对于邮件中出现的单词,我们在词典的相应位置置1,邮件中没有出现的单词,
词典中相应的位置置0.这样对于每一封邮件,我们就可以得到一个长度为50000的特征向量x
解决了特征向量的表示问题,那么该如何对 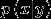 建模呢?
建模呢?
假设采用多项式分布,特征向量x的取值有2^50000个,那么需要2^50000-1个参数,参数量实在是太大了。
因此朴素贝叶斯做了一个非常强的假设:给定y的时候,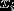 是相互独立的,(是指邮件中第i个位置的单词)
是相互独立的,(是指邮件中第i个位置的单词)

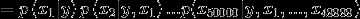 (链式法则)
(链式法则)
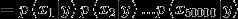 (朴素贝叶斯的强假设)
(朴素贝叶斯的强假设)
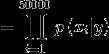
很显然朴素贝叶斯的假设是不可能成立的,但是事实证明朴素贝叶斯算法确实是一个非常有效的算法。
该模型的参数:
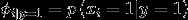
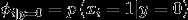
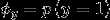
联合似然函数为
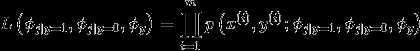
作极大似然估计(求偏导数,然后让其等于0)求得参数
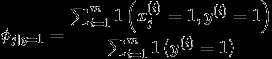
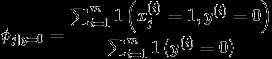
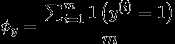
因此对于一封新的邮件x,预测值y为
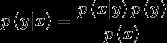
高斯判别分析模型和朴素贝叶斯模型的区别?
当随机变量X的取值是连续值时,可以采用GDA模型进行预测,
当随机变量X的取值是离散值时,可以采用朴素贝叶斯模型。
对于上述邮件的例子,是否是垃圾邮件属于二分类问题, ,因此对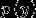 建模为伯努利分布
建模为伯努利分布
在给定y的情况下,朴素贝叶斯假设每个单词的出现互相独立,每个单词是否出现也是一个二分类问题,即 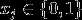 ,因此对
,因此对 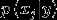 也建模为伯努利分布。
也建模为伯努利分布。
在GDA模型中,假设我们要处理的依然是二分类问题,对 依然建模为伯努利分布。
在给定y的情况下,x的取值是连续值,所以我们对 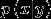 建模为高斯分布。
建模为高斯分布。
在上述邮件例子中存在一个问题:假设在一封邮件中出现了一个以前邮件从来没有出现的词,那么在预测该邮件是否是垃圾邮件时,
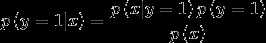
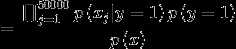
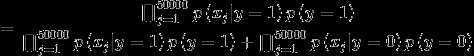
存在 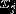 使得
使得 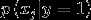 和
和 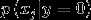 都为0
都为0
那么 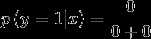 模型失灵。
模型失灵。
换句话说,在有限的训练集中没有出现过的特征,不可以简单的认为该特征以后会出现的概率为0.
修正方法是采用laplace平滑。
4.laplace平滑
假设y可以取k个不同的值,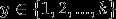 ,那么
,那么
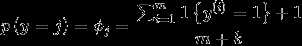
即 分子加1,分母加k,以避免 在预测从未见过的新值时,分子分母都为0的情况。
在上述邮件问题中,
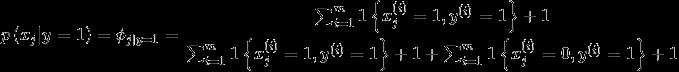
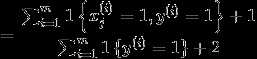
同理
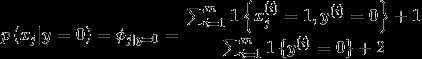
第五讲完。
以上是关于(笔记)斯坦福机器学习第五讲--生成学习算法的主要内容,如果未能解决你的问题,请参考以下文章
斯坦福大学Andrew Ng - 机器学习笔记 -- 机器学习算法的选择与评估
斯坦福机器学习视频笔记 Week6 关于机器学习的建议 Advice for Applying Machine Learning
从零开始CS224W-图机器学习-2021冬季学习笔记13.2:Community Structure in Networks——BigCLAM算法