斯坦福机器学习视频笔记 Week6 关于机器学习的建议 Advice for Applying Machine Learning
Posted yangmang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了斯坦福机器学习视频笔记 Week6 关于机器学习的建议 Advice for Applying Machine Learning相关的知识,希望对你有一定的参考价值。
我们将学习如何系统地提升机器学习算法,告诉你学习算法何时做得不好,并描述如何\'调试\'你的学习算法和提高其性能的“最佳实践”。要优化机器学习算法,需要先了解可以在哪里做最大的改进。 我们将讨论如何理解具有多个部分的机器学习系统的性能,以及如何处理偏斜数据。
Evaluating a Hypothesis

设想当你训练的模型对预测数据有很大偏差的时候,接下来你会选择怎么做?

这个需要花时间去实现,但是对你的帮助也会很大,使你不盲目的做一些决定来提升算法,而是直观地看出哪些是对提升算法是有效的。
我们将数据分为两个集合,Training Set(70%),Test set(30%)
算法评估过程如下:
1.从Training Set学习参数(通过最小化误差J(theta)实现);
2.计算测试误差J(test).
下面是线性回归和分类问题的误差计算方式:

Model Selection and Train/Validation/Test Sets
从多个假设中选择一个训练误差最小的,只能说明它对Training Set有很好的拟合效果,它也可能是Overfit,然后导致Prediction很差。
所以我们下面将数据集分为3个:

这里以之前的房价预测作为例子。
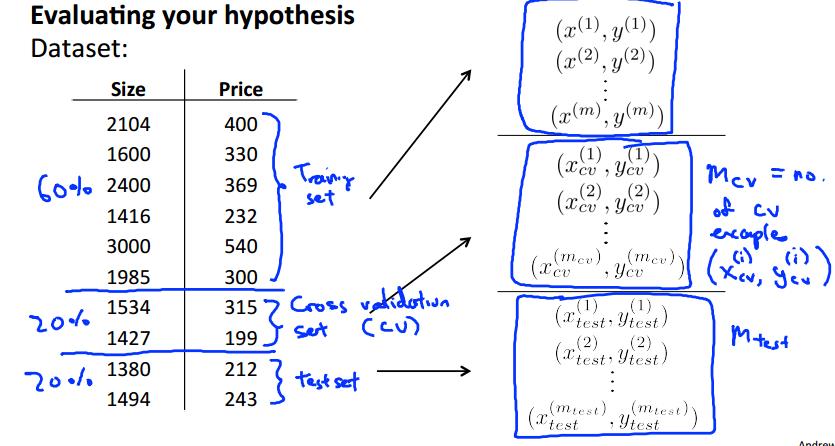
每种误差类型的计算方法如下:

模型选择方法:

1.使用Training Set 最小化 Jtrain(theta)学习得到参数theta;
2.使用训练得到的参数,在Cross Validation Set上计算误差,找到使Jcv(theta)最小的模型,作为训练的最终模型;
3.在训练出的模型上使用test Set计算泛化误差,评价算法好坏。
Diagnosing Bias vs. Variance

在这之前我们都已经讨论过关于underfit和overfit了。那么当你的模型结果不理想时,怎么判断到底是出现了哪种情况呢。

High Bias(underfit):训练误差Jtrain和交叉验证Jcv都很高,Jcv~Jtrain
High Variance(overfit):Jtain很小,Jcv很大且>>Jtrain.
Regularization and Bias/Variance

下面讲解如何选择regularization parameter避免underfit和overfit。

这里除了我们的objective function使用lambda参数外,其他的Jtrain、Jcv和Jtest都不使用lambda进行计算,计算公式如上面。

选择过程:
1.列出所有可能的lambda取值,老师建议每次增加2倍的取值。
2.建立假设模型,h(theta)。
3.遍历所有的lambda,通过minJ(theta)学习参数。
4.在cv集合使用训练的参数theta计算误差Jcv,选择使Jcv最小的theta;
5.用学习到的theta参数,在test set上测试泛化误差。
下面是Jcv和Jtrain关于lambda的函数图象。注意:我们只是在objective funtion J(theta)中使用了lambda,而非Jtrain和Jcv。
可以看出:随着lambda增大,Jtrain是单调增大的;而Jcv先是减小到一个拐点,然后增大。

而我们需要算法有一个小的Jcv,这里就有一个“just right”,也就是那个Jcv的最小值点,就是我们需要选择的lambda。
Learning Curves
以error和training set size作函数图象,作为learning cruvers。
下面是算法处于高偏差(underfit)的情况。

判断模型处于High Bias:
样本少:Jtrain低,Jcv高;
样本多:Jtrain、Jcv都高,且Jtrain ~Jcv
若算法处于High bias,增加更多的训练样本对模型提高不会有太大帮助。
下面是算法处于High variance(overfit)的情况
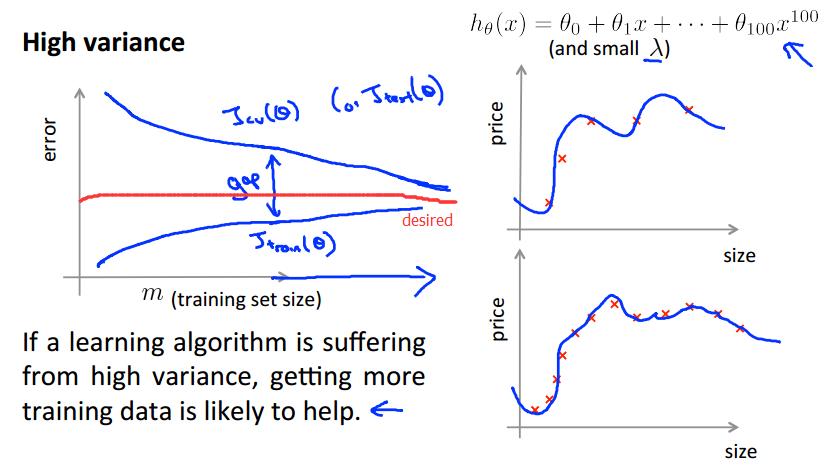
算法处于High variance:
样本少:Jtrain 低,Jcv高;
样本多:Jtrain升高且会一直升高,Jcv降低且一直降低,Jtrain < Jcv且大小明显。
若算法处于high variance,增加训练样本会有帮助。
Deciding What to Do Next Revisited
回顾一下本课开头提出的问题,如何提高你的算法?经过上面的讨论,我们可以得到以下结论:

关于神经网络的underfit和overfit及其解决。

以上所谈对建立一个好的机器学习算法至关重要,而且可以节约不少时间,少走弯路。
以上是关于斯坦福机器学习视频笔记 Week6 关于机器学习的建议 Advice for Applying Machine Learning的主要内容,如果未能解决你的问题,请参考以下文章
斯坦福机器学习视频笔记 Week3 Logistic Regression and Regularization
斯坦福大学Andrew Ng - 机器学习笔记 -- 异常检测
斯坦福机器学习视频笔记 Week2 Linear Regression with Multiple Variables
斯坦福大学Andrew Ng - 机器学习笔记 -- 神经网络模型