Scrapy基础(十三)————ItemLoader的简单使用
Posted 若鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy基础(十三)————ItemLoader的简单使用相关的知识,希望对你有一定的参考价值。
ItemLoader的简单使用:目的是解决在爬虫文件中代码结构杂乱,无序,可读性差的缺点
经过之前的基础,我们可以爬取一些不用登录,没有Ajax的,等等其他的简单的爬虫
回顾我们的代码,是不是有点冗长,将所需字段通过xpath或者css解析出来,再自定义语句(还不是函数中)
进行清洗;然后再装入Item中,有没有这样一种方法:从Item中可以直接清洗岂不是很简单
今天就学习 ItemLoader这样一种对戏,简单代码,可读增强
思路:
1,创建一个ItemLoad对象
2,通过该对象的add_css或者add_xpath或者add_value方法将解析语句装入ItemLoader
3,在Item.py中在Filder()中调用函数,用来清洗,处理数据
4,artical_item = item_loader.load_item() 调用这个对象的此方法,写入到Item中
具体代码:
在爬虫文件中:
1 #先引入 2 from ArticalSpider.items import JobboleArticalItem,ArticalItemLoader 3 #使用Itemloader来简化这个解析,装入Item这个过程,使得代码量减少 4 #先创建一个itemLoader()这样一个对象,不需解析list第一个等问题 5 #这里的ArticalItemLoader是继承了itemloader,并重写了部分功能,实现定制 6 item_loader = ArticalItemLoader(item=JobboleArticalItem(), response=response) 7 #使用ItemLoader这个对象的xpath解析器 8 item_loader.add_xpath("title",\'/html//div[@class="entry-header"]/h1/text()\') 9 #使用get_value()直接从response中选取内容 10 item_loader.add_value("url_object_id",get_md5(response.url)) 11 item_loader.add_xpath("add_time", \'/html//p[@class="entry-meta-hide-on-mobile"]/text()\') 12 item_loader.add_value("url", response.url) 13 item_loader.add_value("front_image_url", [front_image_url]) 14 item_loader.add_value("front_image_url2",front_image_url) 15 item_loader.add_xpath("tags",\'/html//p[@class="entry-meta-hide-on-mobile"]/a/text()\') 16 item_loader.add_xpath("comment_num",\'//span[@class="btn-bluet-bigger href-style hide-on-480"]/text()\') 17 item_loader.add_xpath("fav_num",\'//span[contains(@class,"bookmark-btn")]/text()\') 18 item_loader.add_xpath("like_num",\'//span[contains(@class,"vote-post-up")]/h10/text()\') 19 item_loader.add_xpath("content",\'//div[@class="entry"]\') 20 #装入Item 21 artical_item = item_loader.load_item() 22 23 yield artical_item
在Item.py中
1 #继承ItemLoader这个方法,并自定义自己的方法(属性) 2 class ArticalItemLoader(ItemLoader): 3 #实现之前的extract_first()方法 4 #这里只是重载这个属性,设置为只选取第一个值 5 default_output_processor = TakeFirst() 6 7 #以下将之前的各种清洗语句整合到函数中 8 def add_title_jobbole(value): 9 return value+"---jobbole" 10 11 def get_time(value): 12 #这个好像更改不了 13 try: 14 add_time = datetime.datetime.strptime(value,"%Y/%m/%d").data() 15 except Exception as e: 16 print(e) 17 add_time = datetime.datetime.now().date() 18 return add_time 19 20 def get_tags(value): 21 tag_list = [x for x in value if not str(x).strip().endswith("评论") ] 22 23 return tag_list 24 def get_comment_num(value): 25 re_comment = re.match(".*(\\d+).*",value) 26 if re_comment: 27 comment_num = int(re_comment.group(1)) 28 else: 29 comment_num = 0 30 return comment_num 31 def get_fav_num(value): 32 re_fav_num = re.match(".*(\\d+).*",value) 33 if re_fav_num: 34 fav_num = int(re_fav_num.group(1)) 35 else: 36 fav_num = 0 37 return fav_num 38 #小技巧:在出IteaLoad时,将之前进入的类型按原先的返回,怎么进入怎么返回 39 def get_value(value): 40 return value 41 class JobboleArticalItem(scrapy.Item): 42 title = scrapy.Field( 43 #调用方法,为传进的数据字段进行清洗,调用外部的方法 44 #input_processor 方法是将进入的数据进行调用函数清洗 45 #MapCompose 调用函数名 46 input_processor = MapCompose(add_title_jobbole) 47 ) 48 add_time = scrapy.Field( 49 input_processor = MapCompose(get_time), 50 #只获取传入Item的这个列表中的第一个值作为Item的值 51 #但是要是字段太多,都得写下面这个语句,岂不麻烦,所以可以继承ItemLoader这个类,完成自己类 52 #TakeFirsr()就是 extrct_first() 53 output_processor = TakeFirst() 54 ) 55 url = scrapy.Field() 56 content = scrapy.Field() 57 #不同url长度不同,通过md5统一长度 58 url_object_id = scrapy.Field() 59 60 front_image_url = scrapy.Field( 61 #自定义的类之后,所有的Item都默认了list的第一个值,但传入下载图片的管道时会报错,因为下载图片的Item为list 62 #出去ItemLoader时处理数据的方法 63 output_processor = MapCompose(get_value) 64 ) 65 front_image_url2 = scrapy.Field() 66 #url本地存放路径 67 front_image_path = scrapy.Field() 68 69 tags = scrapy.Field( 70 input_processor = MapCompose(get_tags), 71 #使用processor自带的Join拼接方法 72 output_processor = Join(",") 73 ) 74 comment_num = scrapy.Field( 75 input_processor = MapCompose(get_comment_num) 76 ) 77 fav_num = scrapy.Field( 78 input_processor = MapCompose(get_fav_num) 79 ) 80 like_num = scrapy.Field( 81 82 )
注意:
在保存要下载的图片的URL时,保存在Item中的应该是List;否则报错:
raise ValueError: Missing scheme in request url: h
原因:1,我们继承了Itemloader并重写了default_output_processor = TakeFirst();所以,这时图片URL为str
解决办法:
自定义方法:将怎样进来的value怎样出去(因为进来的是list)

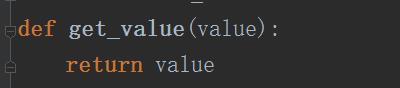
以上是关于Scrapy基础(十三)————ItemLoader的简单使用的主要内容,如果未能解决你的问题,请参考以下文章
四十三 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)