python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
Posted 我爱在伊甸园吃苹果
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)相关的知识,希望对你有一定的参考价值。
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列,
看一下单机的流程图:
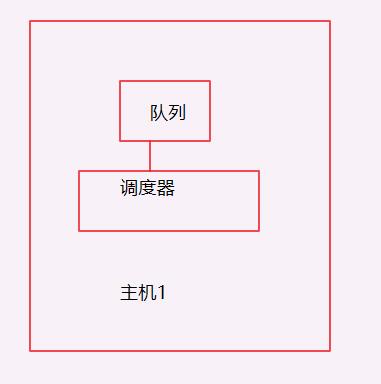
一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点出来了,共享请求队列,看一下架构:
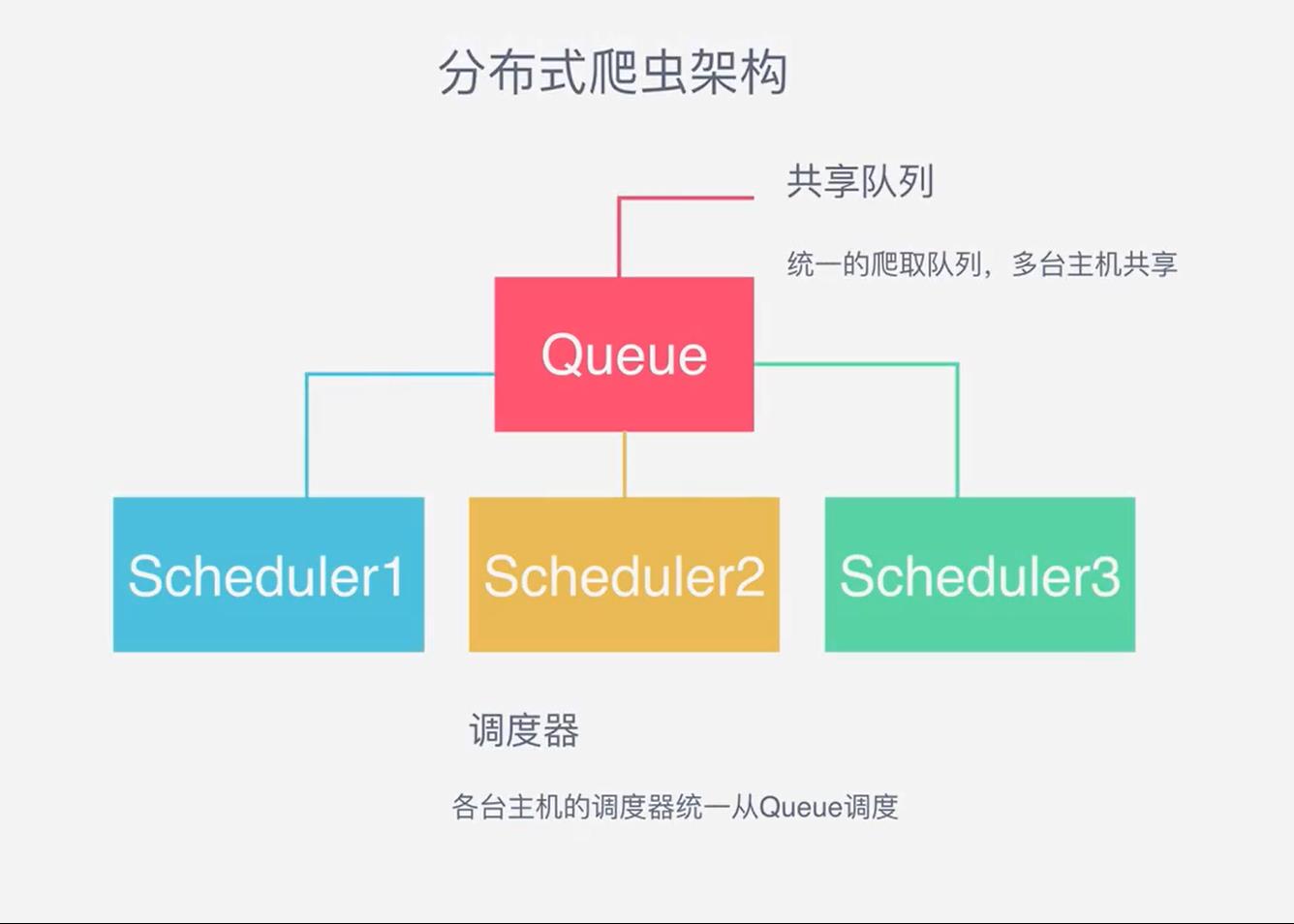
三台主机由一个队列控制,意味着还需要一个主机来控制队列,我们一般来用REDIS来控制队列,形成如下分布式架构
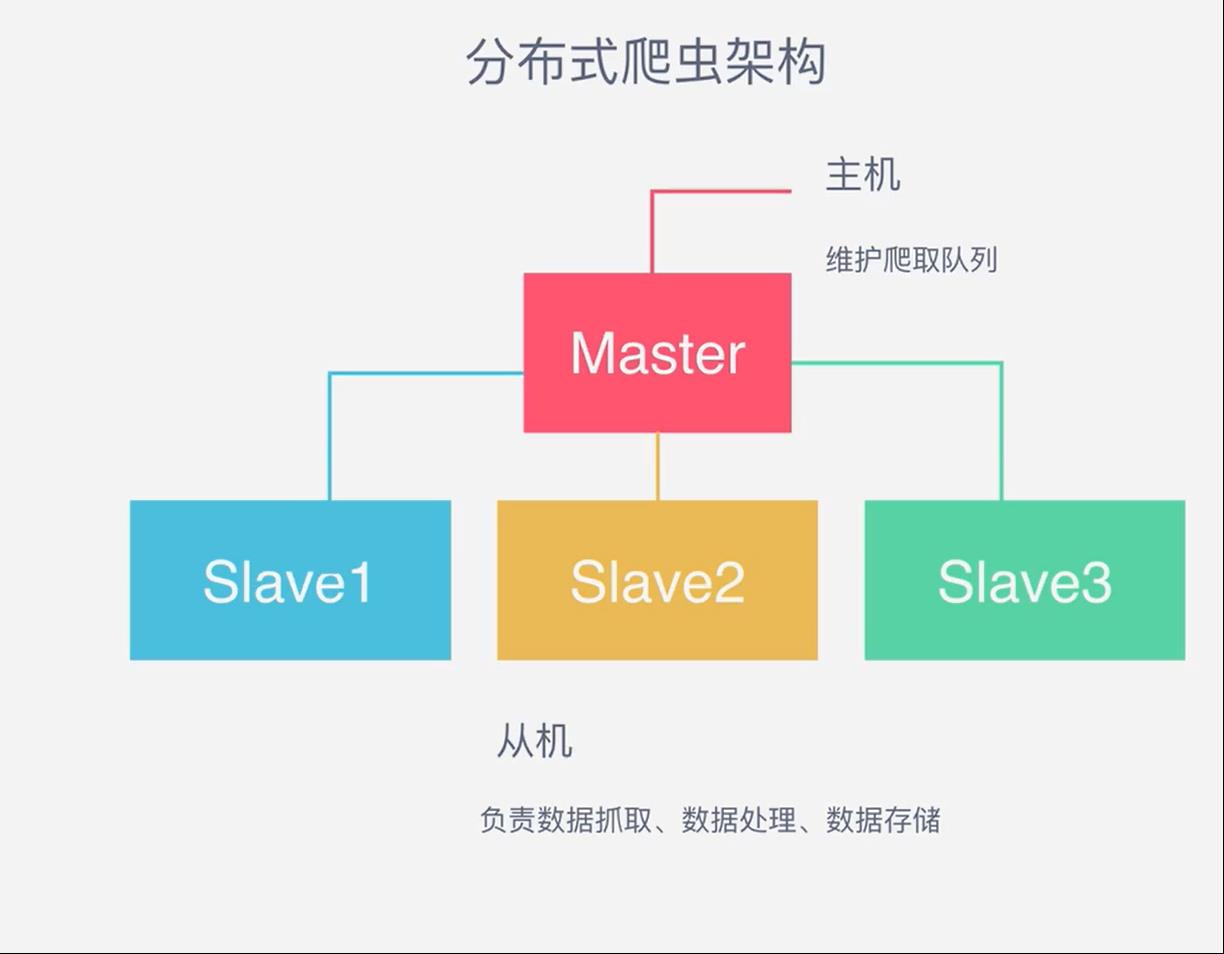
从机抓取,存储主机负责控制队列
SCRAPY_REDIS这个插件解决了SCRAPY不能做分布式爬取的问题
它内部的CONNECTION.PY作为连接MASTER的REDIS
DUPEFILTER.PY用作去重,添加指纹,以及判断功能,现在整个框架了解了,现在该做执行了
以上是关于python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)的主要内容,如果未能解决你的问题,请参考以下文章
python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)
第三百二十三节,web爬虫,scrapy模块以及相关依赖模块安装
python3下scrapy爬虫(第九卷:scrapy数据存储进JSON文件)