python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)
Posted 我爱在伊甸园吃苹果
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)相关的知识,希望对你有一定的参考价值。
现在我们现在一个分机上引入一个SCRAPY的爬虫项目,要求数据存储在MONGODB中
现在我们需要在SETTING.PY设置我们的爬虫文件
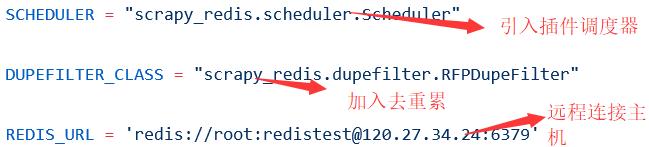
再添加PIPELINE

注释掉的原因是爬虫执行完后,和本地存储完毕还需要向主机进行存储会给主机造成压力
设置完这些后,在MASTER主机开启REDIS服务,将代码复制放在其它主机中,注意操作系统类型以及配置
然后分别在各个主机上进行爬取,爬取速度加大并且结果不同

setting中加入这个可以保证爬虫不会被清空

设置这个决定重新爬取时队列是否清空,一般都用FALSE
我们现在是否分别到主机上执行爬取,现在我想直接在一台主机上控制所有的爬虫程序,现在引入SCRAPYD,他会启动WEB服务来管理所有的项目
看下步骤
1启动SCRAPYD
2可以远程访问
3运用SCPRAPYD-CLIENT来打包项目
4修改爬虫的scrapy.cfg文件

将地址改为远程的SCRAPYD服务地址
执行此命令完成部署

开启一个远程进程
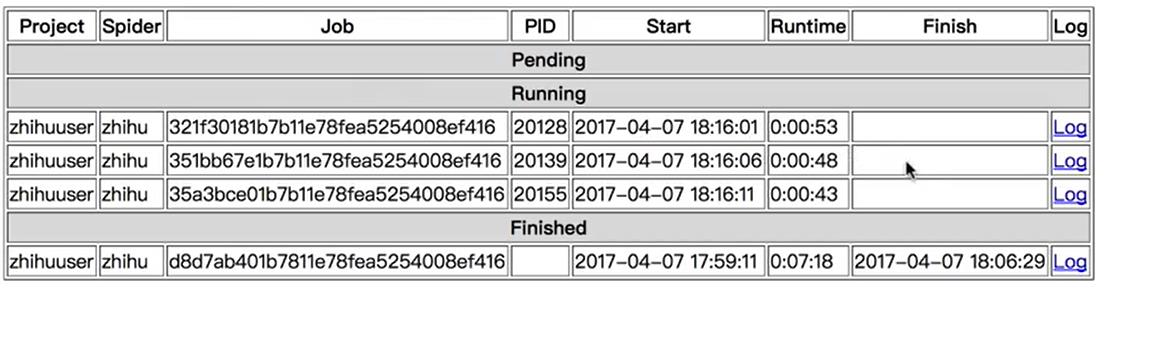
开几条指令,执行几条进程,每一个JOB都个ID如果是多个机器的任务那么ID则不同
以上是关于python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)的主要内容,如果未能解决你的问题,请参考以下文章
python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
python3下scrapy爬虫(第九卷:scrapy数据存储进JSON文件)