python3下scrapy爬虫(第一卷:安装问题)
Posted 我爱在伊甸园吃苹果
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3下scrapy爬虫(第一卷:安装问题)相关的知识,希望对你有一定的参考价值。
一般爬虫都是用urllib包,requests包 配合正则.beautifulsoup等包混合使用,达到爬虫效果,不过有框架谁还用原生啊,现在我们来谈谈SCRAPY框架爬虫,
现在python3的兼容性上来了,SCRAPY不光支持python2版本了,有新的不用旧的,现在说一下让很多人望而止步的安装问题,很多人开始都安装不明白,
当前使用的版本是PYTHON3.5,安装时用PIP3
安装步骤:
1 安装wheel
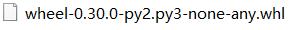
pip3 install wheel
2 安装twisted
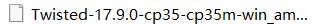
pip3 install Twisted-17.9.0-cp35-cp35m-win_amd64.whl
3 安装lxml
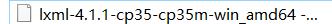
pip3 install lxml-4.1.1-cp35-cp35m-win_amd64.whl
4 安装scrapy
pip3 install scrapy
这样你就成功的安装上了scrapy,你可以创建文件,但是你任然不可爬虫,一旦执行爬虫文件就会报错
5 安装pywin32

一路下一步就行
接着我们创建scrapy文件夹
进入运行环境为python3.5的文件路径,如果你的电脑同时安装2,3版本一定要注意问题。两个版本会出现环境冲突问题,一旦python3版本下的scrapy运行在python2下就会出现版本不兼容问题,就会出现NO MOUDLE的报错
路径切换到python3运行的环境:
scrapy startproject filename
终端进入filename目录
scrapy genspider -t basic crawl1 webname.com
就会创建爬虫脚本文件
文件夹里几个文件我也就不介绍了,
我说下基本爬虫setting.py的应用
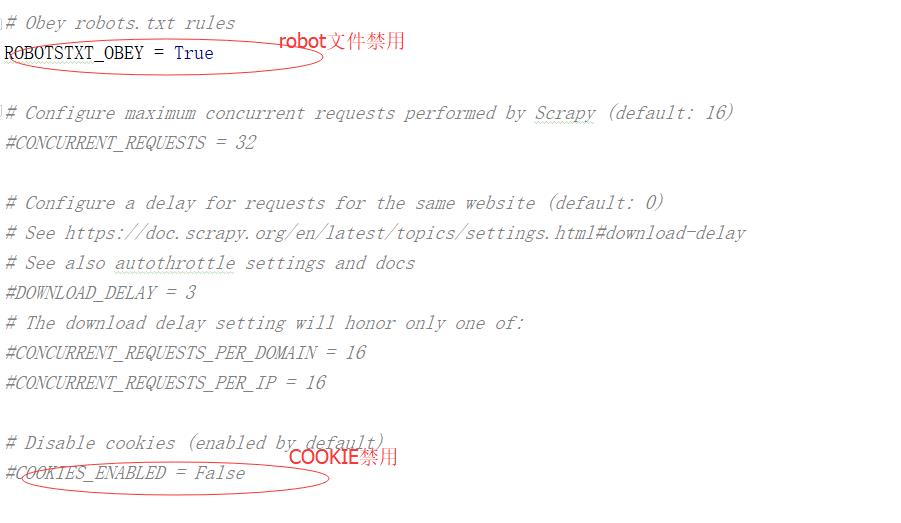
现在可以进行正常的爬取网页了
以上是关于python3下scrapy爬虫(第一卷:安装问题)的主要内容,如果未能解决你的问题,请参考以下文章