第十章-内建模块
Posted weihuchao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第十章-内建模块相关的知识,希望对你有一定的参考价值。
1 datetime
datetime是Python处理日期和时间的标准库
1) 获取当前时间
from datetime import datetime
now = datetime.now()
print(now)
# 2017-04-25 09:10:21.452000
2) 获得指定日期和时间
dt = datetime(2017, 4, 25, 12, 30)
print(dt)
# 2017-04-25 12:30:00
其中datetime可以传入参数, 分别是年月日时分秒, 没有的参数置为0
3) datetime转化为timestamp
时间戳timestamp, 是相对于 1970年1月1日 00:00:00 UTC+00:00 的秒数, 在1970年之前得到的是负数秒数
1970年1月1日 00:00:00 UTC+00:00时区的时刻是 epoch time
获得时间戳的方法是 timestamp()
>>> from datetime import datetime
>>> dt = datetime(2015, 4, 19, 12, 20) # 用指定日期时间创建datetime
>>> dt.timestamp() # 把datetime转换为timestamp
1429417200.0
4) timestamp转化为datetime
获得当前时间和UTC标准时间的方法 fromtimestamp 和 utcfromtimestamp
>>> from datetime import datetime
>>> t = 1429417200.0
>>> print(datetime.fromtimestamp(t)) # 本地时间
2015-04-19 12:20:00
>>> print(datetime.utcfromtimestamp(t)) # UTC时间
2015-04-19 04:20:00
5) str转化为datetime
使用strptime
>>> from datetime import datetime
>>> cday = datetime.strptime(\'2015-6-1 18:19:59\', \'%Y-%m-%d %H:%M:%S\')
>>> print(cday)
2015-06-01 18:19:59
5) datetime转化为str
使用strftime
>>> now = datetime.now()
>>> print(now.strftime(\'%a, %b %d %H:%M\'))
Mon, May 05 16:28
6) datetime的加减
需要导入 timedelta
>>> from datetime import datetime, timedelta
>>> now = datetime.now()
>>> now
datetime.datetime(2015, 5, 18, 16, 57, 3, 540997)
>>> now + timedelta(hours=10)
datetime.datetime(2015, 5, 19, 2, 57, 3, 540997)
>>> now - timedelta(days=1)
datetime.datetime(2015, 5, 17, 16, 57, 3, 540997)
>>> now + timedelta(days=2, hours=12)
datetime.datetime(2015, 5, 21, 4, 57, 3, 540997)
2 collections
collections提供了很多集合类
1) namedtuple
使用namedtuple可以自定义tuple对象, 并且规定元素的个数, 并且可以通过指定键值来获得值
生成的对象是tuple的实例的同时, 还是自定义类的实例
>>> from collections import namedtuple
>>> Point = namedtuple(\'Point\', [\'x\', \'y\'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2
2) deque
list只是单向列表
要想实现双向列表, 能够前后插入和删除, 需要使用deque
具体是使用append, appendleft, pop, popleft
>>> from collections import deque
>>> q = deque([\'a\', \'b\', \'c\'])
>>> q.append(\'x\')
>>> q.appendleft(\'y\')
>>> q
deque([\'y\', \'a\', \'b\', \'c\', \'x\'])
3) defaultdict
在使用dict的时候, 如果访问不存在的键, 则会出现KeyError错误
要设置不存在key值时有默认值, 可以使用defaultdict
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: \'N/A\')
>>> dd[\'key1\'] = \'abc\'
>>> dd[\'key1\'] # key1存在
\'abc\'
>>> dd[\'key2\'] # key2不存在,返回默认值
\'N/A\'
4) OrderedDict
dict是无序的, 要想字典有序, 可以使用OrderedDict
具体的说, OrderedDict使用的是插入时候的顺序
>>> from collections import OrderedDict
>>> d = dict([(\'a\', 1), (\'b\', 2), (\'c\', 3)])
>>> d # dict的Key是无序的
{\'a\': 1, \'c\': 3, \'b\': 2}
>>> od = OrderedDict([(\'a\', 1), (\'b\', 2), (\'c\', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([(\'a\', 1), (\'b\', 2), (\'c\', 3)])
5) Counter
统计元素出现的次数
默认是按次数递减的顺序排列
>>> from collections import Counter
>>> c = Counter()
>>> for ch in "hello world":
c[ch] = c[ch] + 1
>>> c
Counter({\'l\': 3, \'o\': 2, \'h\': 1, \'e\': 1, \' \': 1, \'w\': 1, \'r\': 1, \'d\': 1})
>>>
3 base64
1) 基本原理
base64是以6位为单位的, 也就是形称了26的数量, 也就是base64
有与6位是不规则的, 所以最少需要3个字节整除
也就是说, base64是以3字节为一个处理部分, 共分为3*8/6=4组来处理
如果原有的内容剩下1个或者2个字节, base64会使用 \\x00 来补足, 用在编码后末尾加上=的数量来表示加了多少字节
2) 生成编码
使用b64encode来生成编码
使用b64decode来还原编码
>>> import base64
>>> base64.b64encode(b\'binary\\x00string\')
b\'YmluYXJ5AHN0cmluZw==\'
>>> base64.b64decode(b\'YmluYXJ5AHN0cmluZw==\')
b\'binary\\x00string\'
但是计算的结果又+和/不能放入url中, 此时需要使用 urlsafe_b64encode, urlsafe_b64decode 方法编解码
>>> base64.b64encode(b\'i\\xb7\\x1d\\xfb\\xef\\xff\')
b\'abcd++//\'
>>> base64.urlsafe_b64encode(b\'i\\xb7\\x1d\\xfb\\xef\\xff\')
b\'abcd--__\'
>>> base64.urlsafe_b64decode(\'abcd--__\')
b\'i\\xb7\\x1d\\xfb\\xef\\xff\'
3) 主要用途
主要是应用于URL, Cookie等网络传输少量二进制数
不能用于做加密处理
可以用于在避免网络传输编码的问题
4 struct
struct用于任意类型数据和指定的格式长度的bytes数据之间进行转化
1) 把任意类型转化为bytes
使用pack函数
>>> import struct
>>> struct.pack(\'>I\', 10240099)
b\'\\x00\\x9c@c\'
2) 将bytes转换回来
使用unpack函数
>>> struct.unpack(\'>IH\', b\'\\xf0\\xf0\\xf0\\xf0\\x80\\x80\')
(4042322160, 32896)
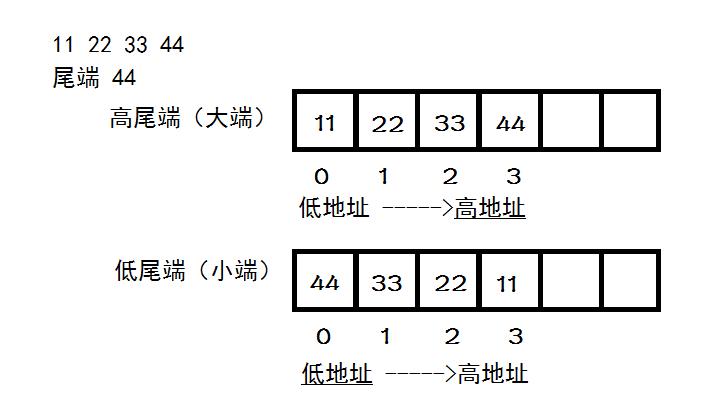
其中>表示字节顺序是大端方式(big-endian), 也是网络序
I表示4字节无符号整数
H表示2字节无符号整数
大端方式(big-endian)
大端方式就是 数据高字节-->内存低地址, 数据低字节-->内存高地址 [和正常阅读一致]
小端方式(little-endian)
小端方式就是 数据高字节-->内存高地址, 数据低字节-->内存低地址
5 hashlib
hashlib是用于加密的, 主要有md5个sha1等
摘要算法又称哈希算法, 散列算法
6 itertools
itertools提供了很多用于操作迭代对象的函数
1) 无限迭代器
count() 可以传入一个整数参数, 表示从参数开始逐一递增, 默认从0开始
>>> import itertools
>>> ns = itertools.count(1)
>>> for n in ns:
print(n)
1
2
3
4
...
2) 无限重复
cycle()需要传入一个序列, 遍历时会不断循环该序列
>>> import itertools
>>> cs = itertools.cycle([\'a\', \'b\', \'c\'])
>>> for c in cs:
print(c)
a
b
c
a
b
c
...
3) 限定重复
repeat()可以传入两个参数, 一个是重复的值, 另一个是重复的次数
如果不传入第二个参数, 仍然会不停的产生元素
>>> import itertools
>>> ns = itertools.repeat(\'abc\', 3)
>>> for n in ns:
print(n)
abc
abc
abc
>>>
4) 限定无限序列
使用takewhile可以传入一个函数, 该函数通过返回值的真假来判断是否返回序列中的元素
>>> natuals = itertools.count(1)
>>> ns = itertools.takewhile(lambda x: x <= 10, natuals)
>>> list(ns)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
5) 串联多个可迭代对象
使用chain() 里面可以传入多个不同类型的迭代对象
>>> import itertools
>>> for n in itertools.chain(\'ABC\',[1,2,3],(4,5,6)):
print(n)
A
B
C
1
2
3
4
5
6
>>>
6) 调出相邻重复的元素
groupby()
第一个参数是需要处理的对象
第二个参数是一个函数, 用于处理对第一个参数元素的处理
>>> for key, group in itertools.groupby(\'AaaBBbcCAAa\', lambda c: c.upper()):
print(key, list(group))
A [\'A\', \'a\', \'a\']
B [\'B\', \'B\', \'b\']
C [\'c\', \'C\']
A [\'A\', \'A\', \'a\']
>>>
7 contetlib
如果实现了上下文管理, 就可以是用with语句进行处理
需要实现两个函数 __enter__ 和__exit__
但是使用contextlib可以更简洁的实现
具体是使用装饰器contextmanager
使用装饰器contextmanager可以具体来形成同样的效果
具体的, 先执行装饰器函数yield和yield前面的内容, 将yield的返回值作为as后面的对象, 这个部分相当于__enter__
yield之后的代码相当于__exit__的代码
具体使用如下
from contextlib import contextmanager
class Hello(object):
def __init__(self, name):
self.name = name
def hi(self):
print(\'你好啊, %s!\' % self.name)
@contextmanager
def create_hello(name):
print(\'执行yiled前的代码..\')
q = Hello(name)
yield q
print(\'执行yiled后的代码..\')
with create_hello(\'魏胡超\') as q:
q.hi()
# 执行yiled前的代码..
# 你好啊, 魏胡超 !
# 执行yiled后的代码..
8 XML
XML在很多领域现在还在使用, 所以需要初步了解XML的基本处理方法
操作XML有两种方法
DOM, 把整个XML读入内存, 解析成为树形结构, 占用内存大, 解析速度慢
SAX, 流模式, 边读边解析, 占用内存小, 解析速度快, 优先考虑SAX处理XML
SAX在读取的时候, 会产生三个事件 start_element, end_element和char_data
具体解析可以先定义一个自己处理的类
这个类对象三个事件进行处理
生成一个解析对象, 将解析对象的三个时间的Handler绑定给写好的类的函数
执行Parse()解析XML就可以了
具体代码如下
from xml.parsers.expat import ParserCreate
class DefaultSaxHandler(object):
def start_element(self, name, attrs):
print(\'sax:start_element: %s, attrs: %s\' % (name, str(attrs)))
def end_element(self, name):
print(\'sax:end_element: %s\' % name)
def char_data(self, text):
print(\'sax:char_data: %s\' % text)
xml = r\'\'\'<?xml version="1.0"?>
<ol>
<li><a href="/python">Python</a></li>
<li><a href="/ruby">Ruby</a></li>
</ol>
\'\'\'
handler = DefaultSaxHandler()
parser = ParserCreate()
parser.StartElementHandler = handler.start_element
parser.EndElementHandler = handler.end_element
parser.CharacterDataHandler = handler.char_data
parser.Parse(xml)
9 htmlParaser
通过HTMLParaser可以解析HTML文件
可以通过继承HTMLParaser来实现自己的解析器
具体需要形成函数参考实例如下
from html.parser import HTMLParser
from html.entities import name2codepoint
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print(\'<%s>\' % tag)
def handle_endtag(self, tag):
print(\'</%s>\' % tag)
def handle_startendtag(self, tag, attrs):
print(\'<%s/>\' % tag)
def handle_data(self, data):
print(data)
def handle_comment(self, data):
print(\'<!--\', data, \'-->\')
def handle_entityref(self, name):
print(\'&%s;\' % name)
def handle_charref(self, name):
print(\'&#%s;\' % name)
parser = MyHTMLParser()
parser.feed(\'\'\'<html>
<head></head>
<body>
<!-- test html parser -->
<p>Some <a href=\\"#\\">html</a> HTML tutorial...<br>END</p>
</body></html>\'\'\')
11 urllib
urllib提供了一系列操作URL的功能
12 PIL
由于PIL比较古老, 仅仅只是支持到2.7
现在支持到3.x的是志愿者们写的兼容版本 Pillow
安装方法
pip install pillow
1) 操作图片
导入包
from PIL import Image
打开图片
im = Image.open(\'test.jpg\')
缩放图片
w, h = im.size
im.thumbnail((w//2, h//2))
im.save(\'thumbnail.jpg\', \'jpeg\')
模糊处理
im = Image.open(\'test.jpg\')
im2 = im.filter(ImageFilter.BLUR)
im2.save(\'blur.jpg\', \'jpeg\')
2) 生成模糊的验证码
from PIL import Image, ImageDraw, ImageFont, ImageFilter
import random
def rndChar():
return chr(random.randint(65, 90))
def rndColor():
return (random.randint(64, 255), random.randint(64, 255), random.randint(64, 255))
def rndColor2():
return (random.randint(32, 127), random.randint(32, 127), random.randint(32, 127))
width = 60 * 4
height = 60
image = Image.new(\'RGB\', (width, height), (255, 255, 255))
font = ImageFont.truetype(r\'C:\\Windows\\winsxs\\amd64_microsoft-windows-font-truetype-arial_31bf3856ad364e35_6.1.7601.17514_none_d0a9759ec3fa9e2d\\Arial.ttf\', 36)
draw = ImageDraw.Draw(image)
# 填充每个像素:
for x in range(width):
for y in range(height):
draw.point((x, y), fill=rndColor())
# 输出文字:
for t in range(4):
draw.text((60 * t + 10, 10), rndChar(), font=font, fill=rndColor2())
# 模糊:
image = image.filter(ImageFilter.BLUR)
image.save(\'code.jpg\', \'jpeg\')
以上是关于第十章-内建模块的主要内容,如果未能解决你的问题,请参考以下文章