斯坦福CS231n—深度学习与计算机视觉----学习笔记 课时14&&15
Posted 草莓鲍鲍
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了斯坦福CS231n—深度学习与计算机视觉----学习笔记 课时14&&15相关的知识,希望对你有一定的参考价值。
课时14 卷积神经网络详解(上)
CNN处理的是一些数据块,在这之间有很多层,一系列的层将输入数据变换为输出数据,所以完成操作的中间量不仅是NN时候讲的那些向量,而是立体结构,有宽,高和深度,在整个计算过程中要保持这些三维特征。这里的深度指的是一个数据体的第三个维度。
工作流程
我们得到一些数据,作为网络的输入,在CNN中我们有这样的滤波器,假设现在我们只有一个滤波器,这些滤波器空间维度很小,我们用这个滤波器来和输入图像做卷积运算。这里的卷积运算,意思是说滤波器要在这个图像的空域范围内全部位置滑动,而且,在每一个位置滤波器和图像做点乘。滤波器表示为w,把这些滤波器当做你的一堆w,然后你在图像范围内滑动这个滤波器,随着我们滑动滤波器,还要计算w的转置和x的乘积加上b。这里的x是输入数据的一小块区域,大小为滤波器的大小。当滤波器在滑动的时候,最后得到的整个结果,我们叫做激活图。激活图给出了在每个空间位置处滤波器的反应。
课时15 卷积神经网络详解(下)
我们每次做池化层时都扔掉了一小部分信息
在全连接层之前会有深度减少的地方
输入的数据中,边缘的数据可能和中心不太一样
我们不会为滤波器进行特定的初始化
池化层没有参数,只有卷积层有参数
规范化层是一个进行规范化的特殊的层,在2012年之后就不再用到了。
当在做反向传播的时候一定要注意,因为参数是共享的,当你在用滤波器做卷积时,所有的神经元都共享参数。你必须小心,所有的滤波器的梯度都汇总到一个权重。
ZFNet
基于AlexNet构建
conv1的滤波器大小、步长比AlexNet更小,对原始图像做更密集的计算。
conv3、conv4、conv5相比AlexNet有更多的过滤器
VGG NET
VGG并没有在疯狂的架构选择(例如你如何设定过滤器个数,尺寸大小,过滤器的大小等参数)上做非常多的工作,VGG的关键点在于在这个操作你重复了多少次(多少层),最后同样的这组参数设定的网络结构重复层叠至16层
VGG网络有一个非常简单的线性结构
GoogLeNet
最关键的创新点是引入了inception模块,但是它仅仅是inception模块的序列,一个接一个进行排列,他们使用的是inception层而不是卷积层,随后他们使用average pool而非全连接层,所以他们省去了大量的参数,他致力于同时减少对内存和计算量的需求。
必须小心处理增加层数,如果仅仅是简单的去做,他将没有什么用处
ResNet
大致的工作原理是我们有plain net,然后选取一张图片,接着有conv,pool,然后继续conv,conv,conv,conv.在ResNet中,在这些有趣的跳跃连接中,除了这种严格将一个容量转移到下一个容量的传递之外,我们还有这些连接。你可以将很多的信息打包进一个小的容器里。
工作方式:
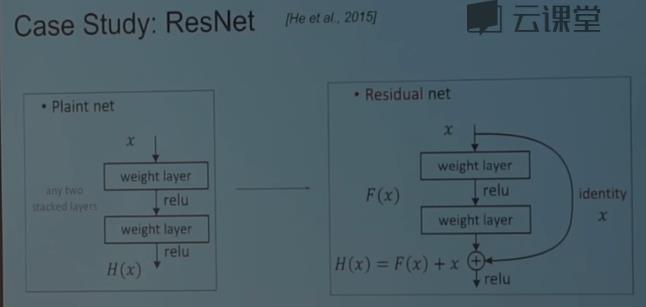
在一个普通的神经网络中,你有一些函数H(x),想做一些计算,你要转换映射后的值,所以你有一个权重层,你有神经元映射后的值,你要将其转换,等等。在残差网络中,你的输入不是去计算你的变换F(x),而是计算过程中需要加上输入的残差。这个2层的神经网络需要计算的是顶部输入的原始表示,而不是一种与之前x完全没关系的表示,这个就是resent模型。
这一层基本上是由默认的恒等运算,这些建立在顶部的恒等上,他只是让他更好的优化
训练残差网络过程

gpu计算空间是这个的瓶颈
以上是关于斯坦福CS231n—深度学习与计算机视觉----学习笔记 课时14&&15的主要内容,如果未能解决你的问题,请参考以下文章
斯坦福CS231n—深度学习与计算机视觉----学习笔记 课时14&&15
全球名校课程作业分享系列--斯坦福计算机视觉与深度学习CS231n之KNN
斯坦福CS231n—深度学习与计算机视觉----学习笔记 课时26&&27
斯坦福CS231n—深度学习与计算机视觉----学习笔记 课时12&&13