Machine Learning——Unsupervised Learning(机器学习之非监督学习)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Machine Learning——Unsupervised Learning(机器学习之非监督学习)相关的知识,希望对你有一定的参考价值。
前面,我们提到了监督学习,在机器学习中,与之对应的是非监督学习。无监督学习的问题是,在未加标签的数据中,试图找到隐藏的结构。因为提供给学习者的实例是未标记的,因此没有错误或报酬信号来评估潜在的解决方案。这区别于监督学习和强化学习无监督学习。
无监督学习是密切相关的统计数据密度估计的问题。然而无监督学习还包括寻求,总结和解释数据的主要特点等诸多技术。在无监督学习使用的许多方法是基于用于处理数据的数据挖掘方法。
我们来看两张图片:
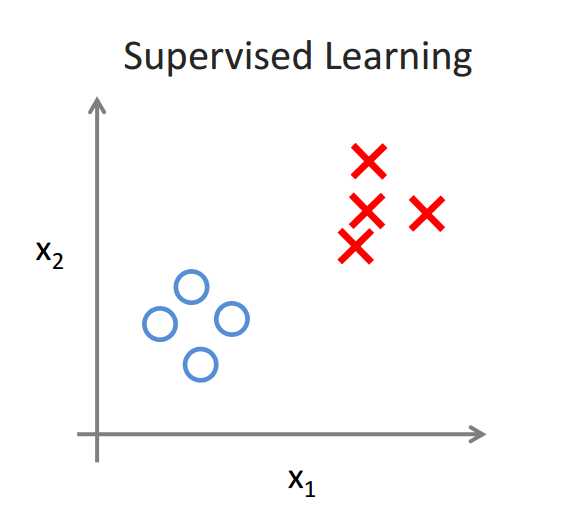
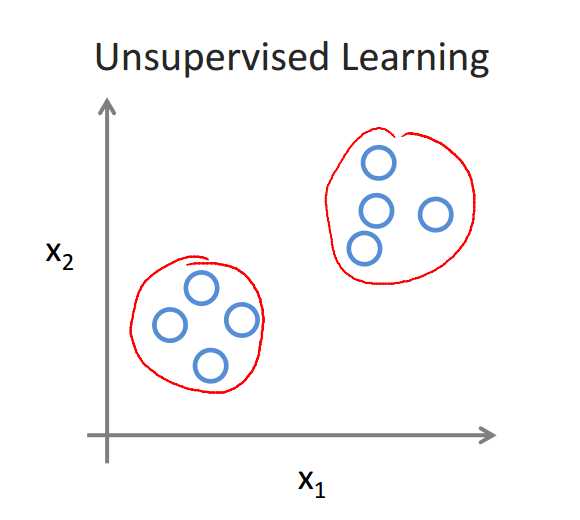
从图中我们可以看到:非监督学习中没有任何的标签或者是有相同的标签或者就是没标签。所以我们已知数据集,却不知如何处理,也未告知每个数据点是什么。别的都不知道,就是一个数据集。针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。 这是一个,那是另一个,二者不同。无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法。事实证明,它能被用在很多地方。
聚类应用的一个例子就是在百度新闻中。如果你以前从来没见过它,你可以到这个 URL 网址http://news.baidu.com/去看看。百度新闻每天都在,收集非常多,非常多的网络的新闻内容。 它再将这些新闻分组,组成有关联的新闻。所以百度新闻做的就是搜索非常多的新闻事件, 自动地把它们聚类到一起。所以,这些新闻事件全是同一主题的,所以显示到一起。
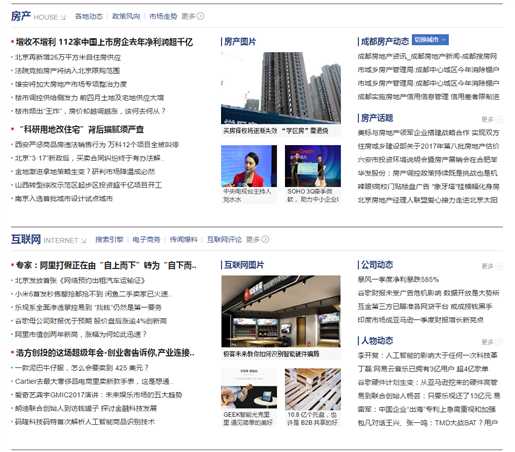
从这张网页截图中可以看到,百度新闻收集了大量的新闻,然后把他们聚成不同的类,例如:房产,互联网......在每个大类(大标签)下,又聚成了不同的小类。
我们再看一个例子:一个 DNA 微观数据的例子。
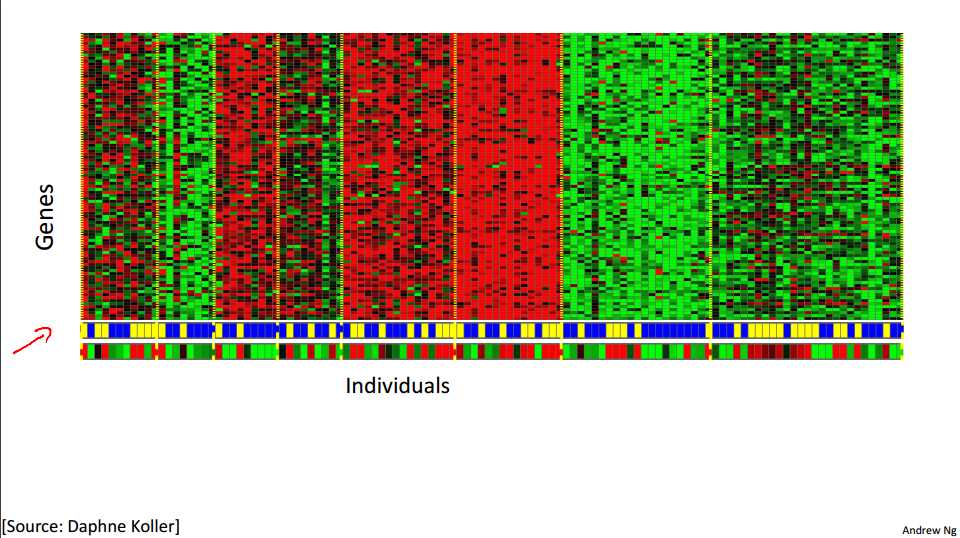
其基本思想是输入一组不同个体,对其中的每个个体,你要分析出它们是否有一个特定的基因。技术上,你要分析多少特定基因已经表达。所以这些颜色,红,绿,灰等等颜色,这些颜色展示了相应的程度,即不同的个体是否有着一个特定的基因。你能做的就是运行一个聚类算法,把个体聚类到不同的 类或不同类型的组(人)……
所以这个就是无监督学习,因为我们没有提前告知算法一些信息,比如,这是第一类的人,那些是第二类的人,还有第三类,等等。我们只是说,这是有一堆数据。我不知道数据里面有什么,我不知道谁是什么类型,我甚至不知道人们有哪些不同的类型,这些类型又是什么。但你能自动地找到数据中的结构吗?就是说你要自动地聚类那些个体到各个类,我没法提前知道哪些是哪些。因为我们没有给算法正确答案来回应数据集中的数据,这就是无监督学习。
以上是关于Machine Learning——Unsupervised Learning(机器学习之非监督学习)的主要内容,如果未能解决你的问题,请参考以下文章
COMPSCI 361 Machine Learning 重点解析