机器学习贝叶斯决策 实例
Posted kotete
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习贝叶斯决策 实例相关的知识,希望对你有一定的参考价值。
现在举一个例子说明怎么使用贝叶斯公式来做决策。
例子:
假设有100个人,每个人都有自己的生日。1年有12个月,假设这100个人的生日从1月到12月的人数的分布情况如下:
3 4 5 7 10 13 14 15 12 8 5 4
那么1月到12月生人所占的比率分别为:
0.0300 0.0400 0.0500 0.0700 0.1000 0.1300 0.1400 0.1500 0.1200 0.0800 0.0500 0.0400
把数据放入matlab中:

用matlab绘制看着更直观:
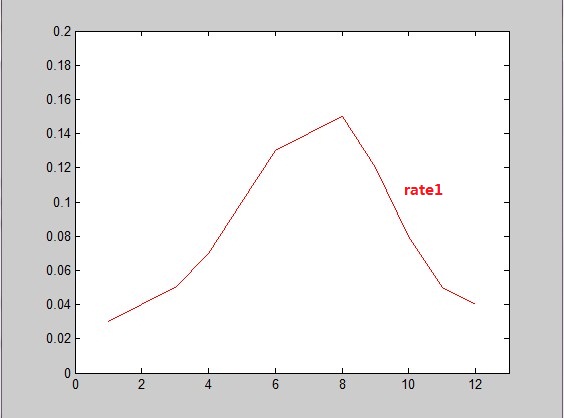
这个rate1数组就是概率密度函数了,它满足两个条件:大于0且积分为1(因为sum(rate1)=1,见matlab命令行截图)。
现在,假设刚才的那100个人是北半球的样本。现在再收集南半球的100个人的生日作为样本。
1到12月生人的分布情况为:
15 12 9 6 4 3 4 5 7 9 12 14
那么1月到12月生人所占的比率分别为:
0.1500 0.1200 0.0900 0.0600 0.0400 0.0300 0.0400 0.0500 0.0700 0.0900 0.1200 0.1400
计算总和

画出曲线如下:
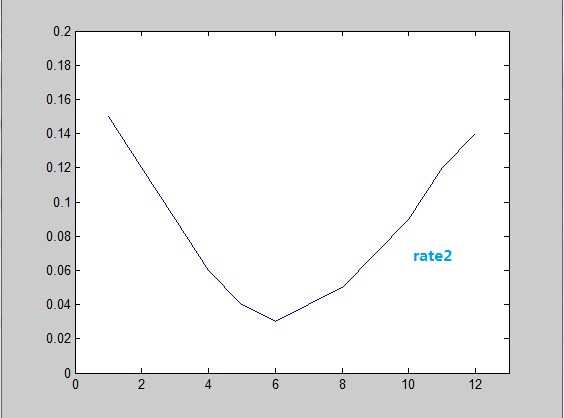
显然,rate2曲线可以作为南半球数据的概率密度函数,因为rate2(x)>0且sum(rate2)=1。
将南半球人民的生日概率密度曲线和北半球人民的概率密度分布曲线放到一起。
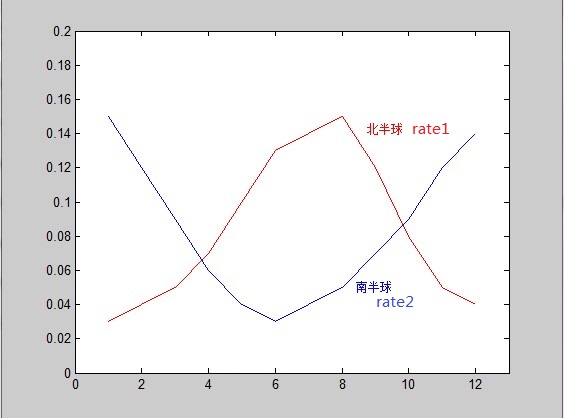
(这个例子整得有点极端了,说明问题就好……orz)
假设一个人为北半球人民这个事件为ω1,一个人为南半球人民这个事件为ω2,显然一个地球人要么是南半球的要么是北半球的,所以P(ω1)+P(ω2)=1
那现在再来查查看南半球人民和北半球人民的比例是多少呢?谷歌之

忽略掉那些不需要的信息,我们得出P(ω1)/P(ω2)=9:1
也就是说,P(ω1)=0.9,P(ω2)=0.1
所以,在我们的例子可以抽象为:
特征值为”生日“,及生日=x。
p(x|ω1)=rate1(红色的曲线), p(x|ω2)=rate2(蓝色的曲线)
(红色曲线和蓝色曲线的来历已经介绍了)
且先验概率P(ω1)=0.9,P(ω2)=0.1
那么现在要求贝叶斯公式的分母,即证据因子。
根据公式
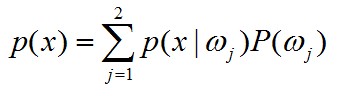
知 p(x)=p(x|ω1)P(ω1)+p(x|ω2)P(ω2)
现在,假如我们在google+上遇到一个好友,只知道他生日是6月,那怎么猜测这位好友是来自南半球还是北半球呢??
噔噔噔噔,贝叶斯公式上场了!!
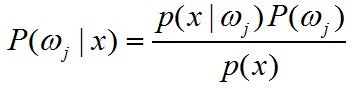
公式右侧的参数我们都已经知道了,现在就可以求左边的数了。
生日是6月也就是说x=6
所以以x为变量的p(ω1|x)、p(ω2|x)以及p(x)都可以求了,分别为
p(x|ω1)=rate1(6)=0.1300
p(x|ω2)=rate2(6)= 0.0300
p(x)=p(x|ω1)P(ω1)+p(x|ω2)P(ω2)=0.13*0.9+0.03*0.1=0.12
∴P(ω1|x)=p(x|ω1)P(ω1)/p(x)=0.13*0.9/0.12=0.975
P(ω2|x)=p(x|ω2)P(ω2)/p(x)=0.03*0.1/0.12= 0.0250
所以这位神秘的好友有97.5%的可能性是来自北半球的,只有2.5%的可能性是来自南半球。
我们可以设定这样的判决规则:
” 如果P(ω1|x)>P(ω2|x),则判决为ω1类,否则为ω2类 “
也就是说,如果我们”大胆假设“这位友人来自北半球,那么我们的猜测出错的概率就是
P(error|x) = MIN[P(ω1|x),P(ω2|x)] = 0.025
-----------------------------------------------------
后记:
从上述例子中可以看出,证据因子p(x)其实对做出某种判决并不重要,它仅仅是一个标量,用来表示一种比例,即表示我们实际测量的具有特征值x的模式的出现频率。如果把它去掉,也可以讲判决规则改为
” 如果p(x|ω1)P(ω1)>p(x|ω2)P(ω2),则判决为ω1类,否则为ω2类 “
用贝叶斯公式来帮助做决策的大概思路就是计算出某个特征值为x的待测样本属于各个不同类别的可能性,然后根据判决规则,选择概率最大(即可能性最大)的一个作为决策的结果。
以上是关于机器学习贝叶斯决策 实例的主要内容,如果未能解决你的问题,请参考以下文章