HDFS:edit log & fsimage
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS:edit log & fsimage相关的知识,希望对你有一定的参考价值。
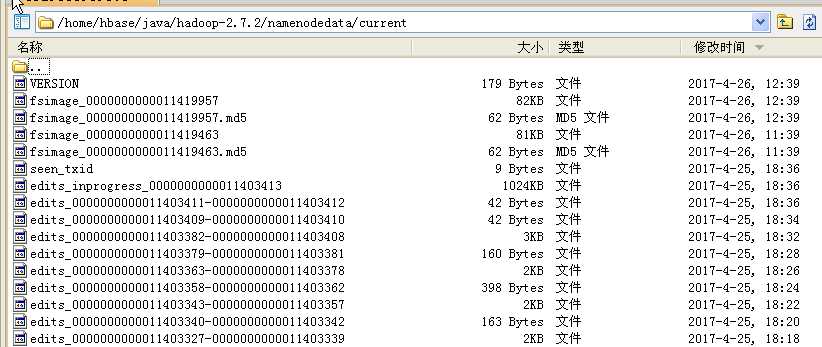
在NameNode的${dfs.namenode.name.dir}/current目录下,有这样几个文件:
在数据库系统中,log是用于记录写操作的日志的,并使用该Log进行备份、恢复数据等工作。有关写的操作的记录的,目前见过了两种:关系型数据库的log,HBase的WALs等等都是这样的写操作的日志。
HDFS也采用了类似的机制。在HDFS中,会将第一次的文件操作,看作一个事务。譬如说一个文件的创建、文件内容追加、文件移动等等写操作。从这个角度来看呢,fsimage文件就相当于HDFS 的元数据的数据库文件了,而edit log就相当于是操作日志文件了。
Fsimage:
每个fsimage文件都会包括整个文件系统中所有的目录和文件inodes信息。每个inode是HDFS内部的一个代表文件、或者目录的元数据,如果inode代表一个文件,它包括:文件的备份级别、修改时间、访问时间、访问权限、block的size、所有blocks的构成等信息。如果inode代表一个目录,它包括:修改时间、权限、其它相关元数据等。
Edit log:
它在逻辑上,是一个实例(也就是说可以理解为一个对象),实际上是由多个文件组成的。每个文件都被称为一个segment,并以 edits_作为前缀,文件名后面的是事务id。
譬如上面的:edits_0000000000011403382-0000000000011403408 就代表该文件中放的是
事务Id为0000000000011403382到0000000000011403408之间的那些事务的信息。当客户端完成了一个写操作,并收到namenode的success的响应码时,Namenode才会将该事务信息写到editlog文件中。
为什么将事务信息处理后不直接写到fsimage中?
如果这样做的话,也就是每个write操作完毕时,都去更新fsimage文件,在一个大的文件系统中,文件就会变得很大,上GB都是有可能的,那么将是一个缓慢的过程。
先写到edit log中,怎么合并到fsimage中呢?
解决方案是启动一个Secondary namenode。它的存在就是在内存中生成Primary NameNode的fsimage文件。它的处理过程是这样的:
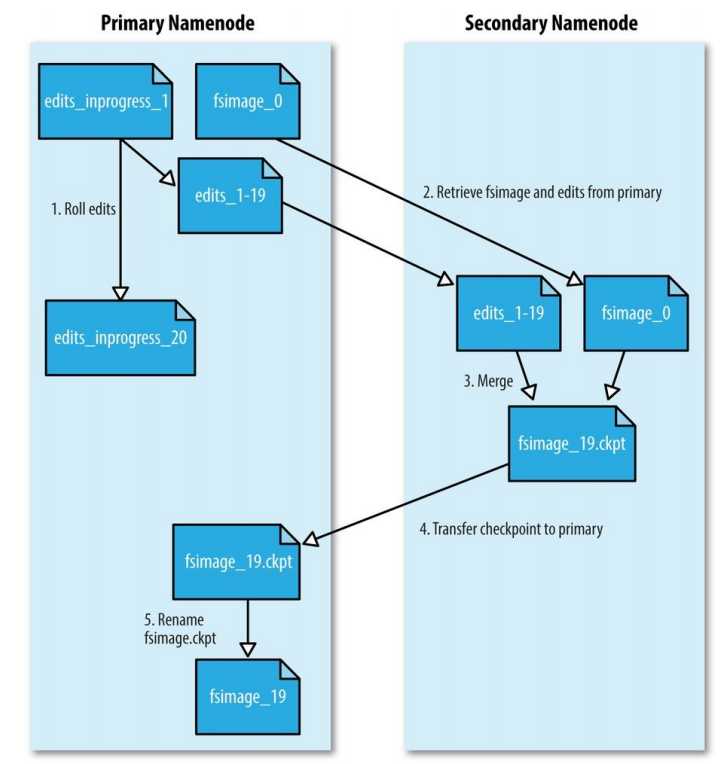
1、Secondary 告诉Primary去滚动它的in-progress edits文件,这样新来的write操作就会放到一个新的edit 文件中。同时Primary也会更新seen_txid文件。
2、Secondary 通过HTTP GET方式从Primary获取到最新的fsimage和edits文件
3、Secondary 将fsimage加载到内存中,并从edits文件中取出每一次事务,应用到fsimage上,如此就产生了一个合并的新的fsimage文件。
4、Secondary将这个新合并的fsimage文件通过HTTP PUT发到Primary,Primary把它保存到临时.ckpt文件中。
5、Primary再把临时文件重命名,并使它可用。
同时,这也是为啥Secondary需要与Primary类似的内存配置,并且需要部署在一个单独的机器。
以上是关于HDFS:edit log & fsimage的主要内容,如果未能解决你的问题,请参考以下文章
关于oracle的缓冲区机制与HDFS中的edit logs的某些关联性的思考