主分量分析PCA
Posted yuyaweibest
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了主分量分析PCA相关的知识,希望对你有一定的参考价值。
主分量分析PCA
摘要:本次实验分为两部分,第一部分:利用PCA,通过自定义函数PCA_two(MU,SIGMA,N)进行特征空间的规整化。第二部分:利用PCA,通过自定义函数PCA_three(MU,SIGMA,N)进行特征空间降维。PCA方法是一种处理数据过多维数的方法,它的目的是寻找在最小均方意义下最能代表原始数据的投影方法。经过本次实验,了解了PCA主分量分析的基本概念,学习和掌握了PCA主分量分析的方法。
一、 实验原理
1、统计分析方法中的降维思想
在模式识别的研究过程中,往往需要对反映事物的多个变量进行大量的观测,收集大量数据以便进行统计分析。多变量大样本为研究者提供了丰富的信息,但也在一定程度上增加了统计分析的运算量。而在多数情况下,变量与变量之间存在着相关性,因而又增加了问题分析的复杂性。如果分别对每个指标进行分析,分析往往是孤立的,而不是综合的。盲目减少数据会损失很多信息,容易产生错误的判决结果。
因此需要找到一个合理的方法,在减少需要分析的信息和保证分析质量两者中取得平衡。前面说到由于各变量间存在一定的相关关系,这使得这种思想成为可能。可以采用特征线性组合的方法减少特征空间中的特征维数。将高维数据投影到较低维空间上。主成分分析(Principal Component Analysis)和Fisher判别分析法是两类有效的线性组合变换方法。
2、主分量分析(PCA)
假设有n个d维的样本X1,X2,...,Xn,希望仅使用一个d维的向量X0来表示这n个样本,并希望这个代表向量X0与各个样本Xk(k=1,...,n)的距离的平方之和越小越好。定义平方误差准则函数J0(X0)如下:


在向量 分别为散布矩阵的d’个最大特征值所对应的特征向量时,平方误差准则函数取得最小值。因散布矩阵是实对称矩阵,因此这些特征向量都是相互正交的,构成了任一向量X的基向量。系数ai对应于基ei的系数,成为主分量。
从几何上说,样本点 在d维空间形成了一个d维椭球形状的云团,散布矩阵的特征向量就是这个云团的主轴。主成分分析通过提取云团散布最大的方向达到了对特征空间进行降维的目的。
二、 实验布骤及实验结果
1、 利用PCA进行特征空间的规整化
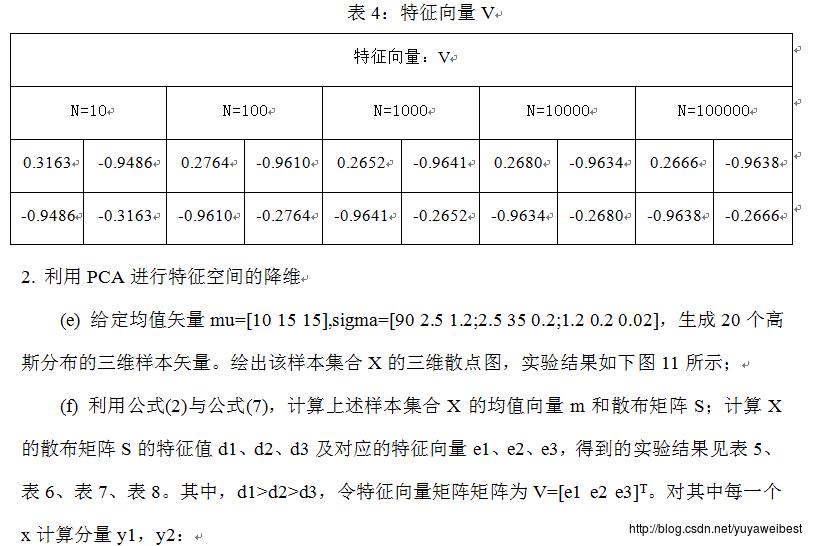
(a) 给定均值矢量mu=[5 7],sigma=[9 2.4;2.4 1],生成N=100个高斯分布的二维样本矢量。绘出样本集合X的二维散点图,如下图3所示;
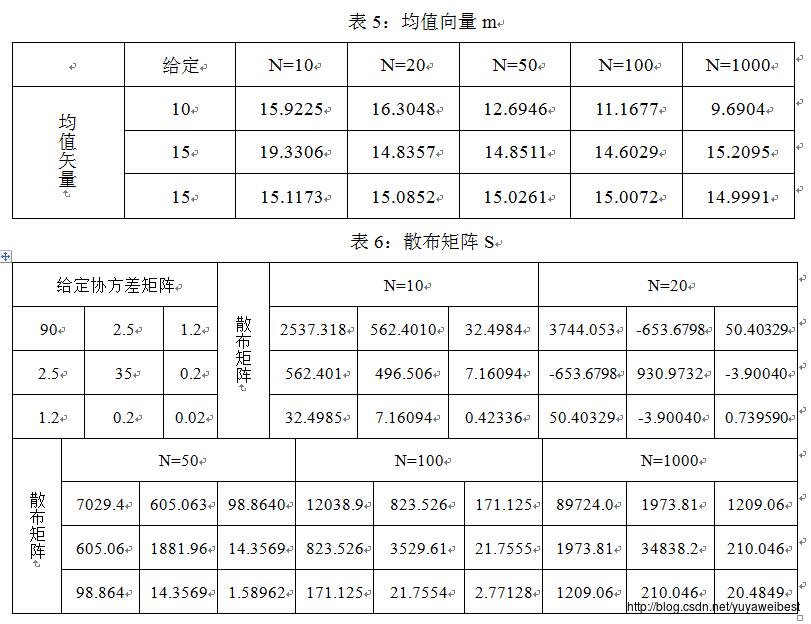
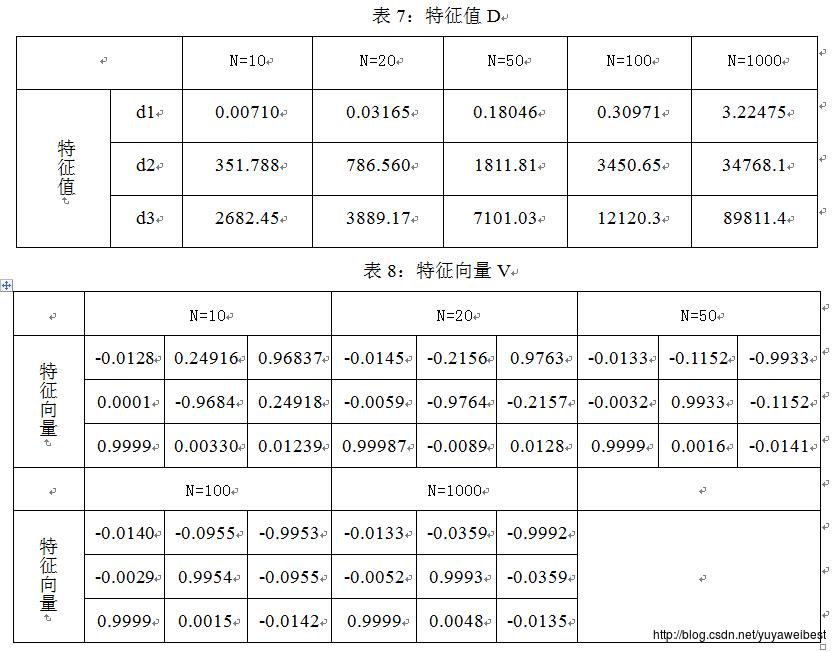
(b) 利用式(2)和式(7)计算上述样本集合X的均值向量m和散布矩阵S,使用Matlab中的eig()函数,计算X的散布矩阵S的特征值和特征向量,得到的实验结果见表1、表2、表3、表4;
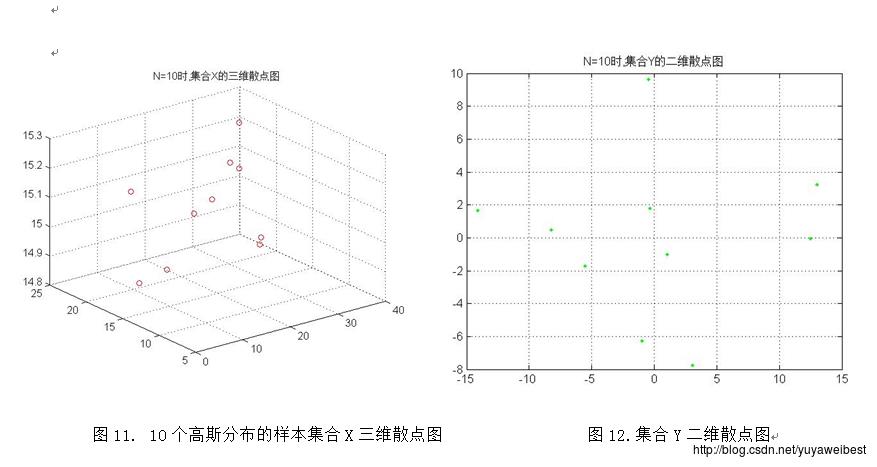
(c)假设数据集合X的均值向量为m,散布矩阵S的特征向量矩阵为V=[e1 e2]T,将集合X中的每一个向量x变换为向量y, y=V(x-m),生成集合Y, 。绘出集合Y的二维散点图,如下图3所示:
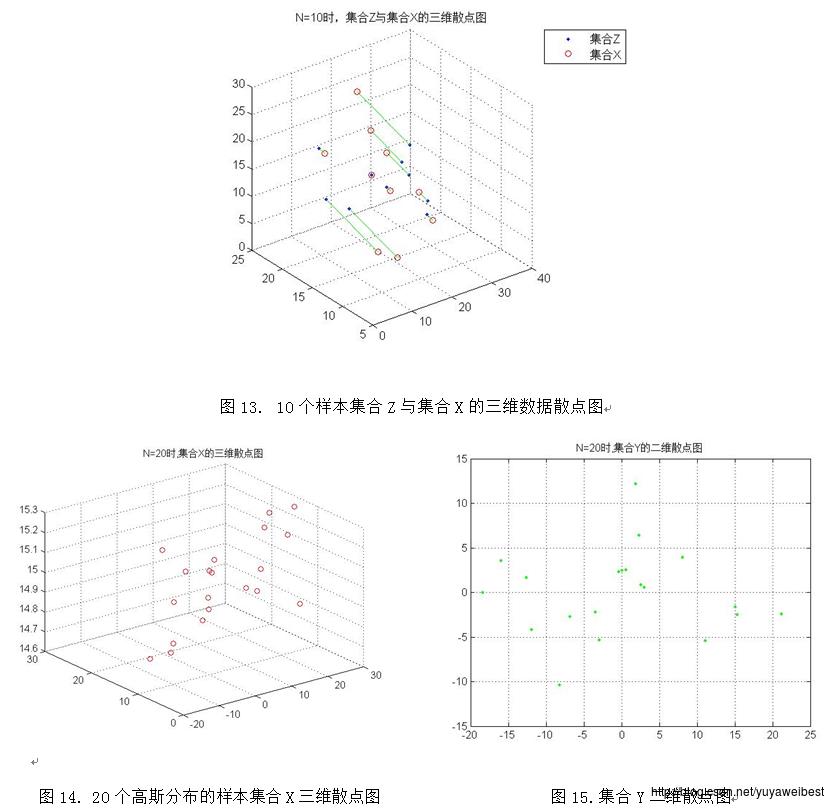
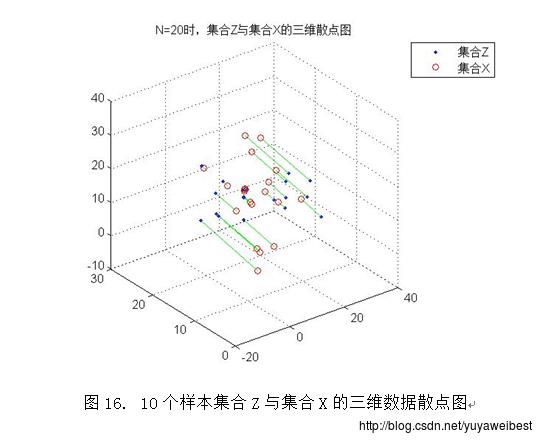
(d) 调用自定义函数PCA_two(MU,SIGMA,N),改变样本总数,分别令N=10、1000、10000、100000,重复上述实验(a) (b) (c),得到的均值向量m与散布矩阵S及S的特征值与特征向量见表1、表2、表3、表4,实验结果图如下图1~图10所示:
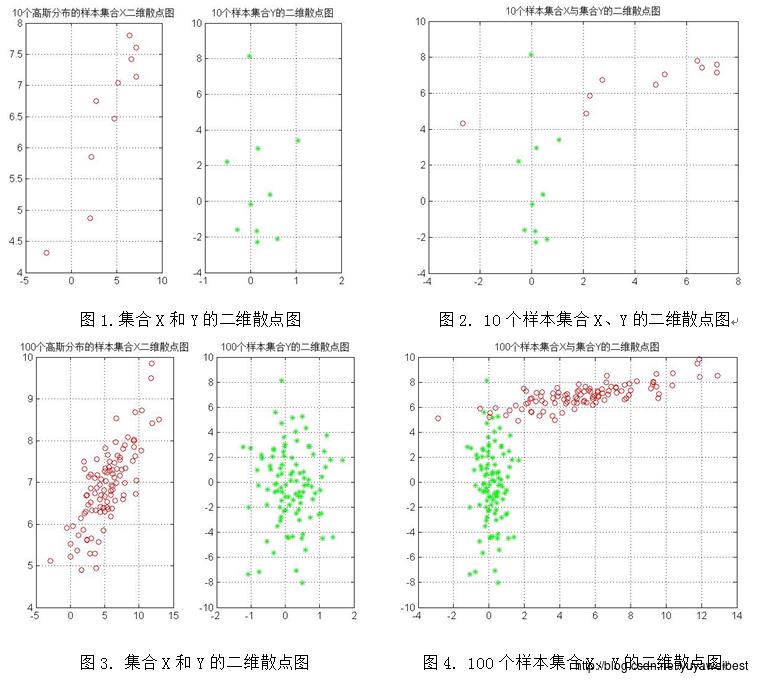
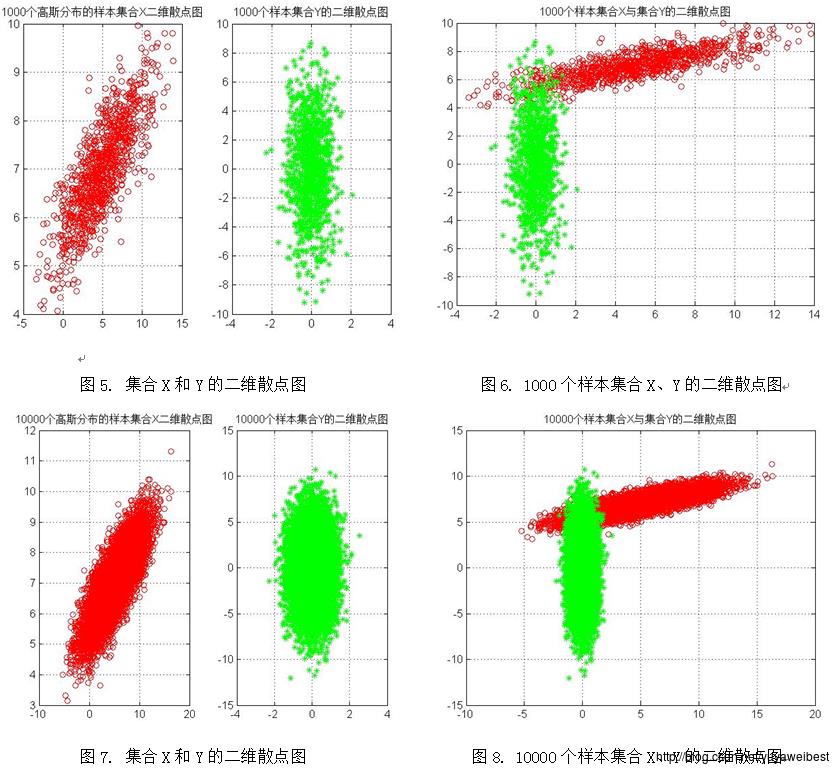
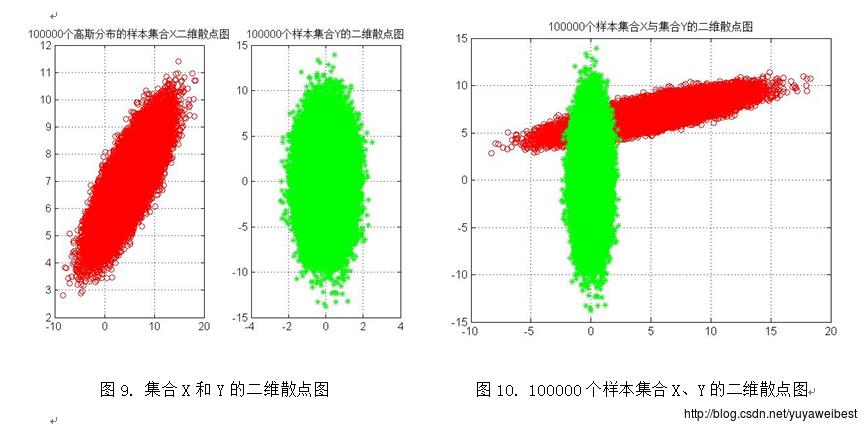
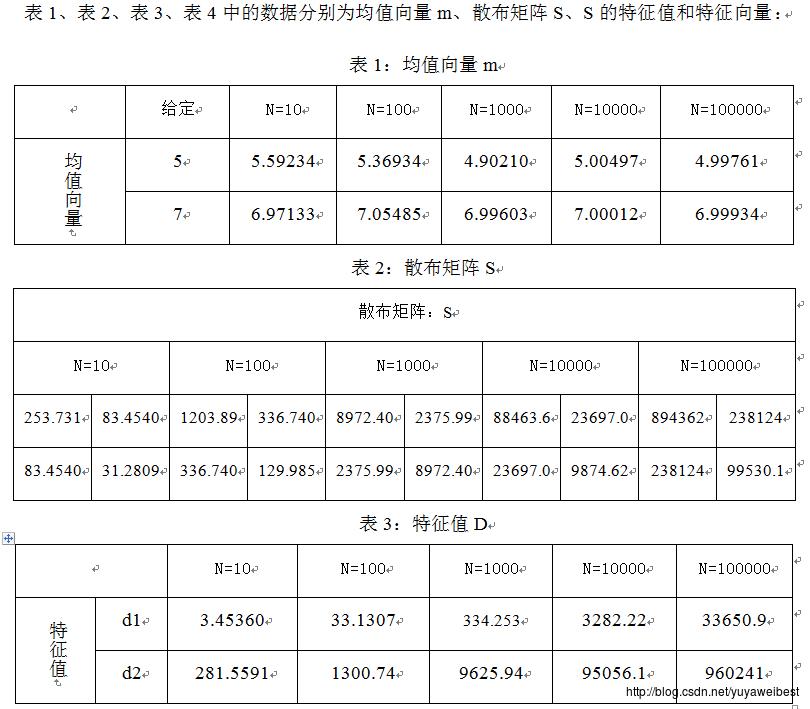

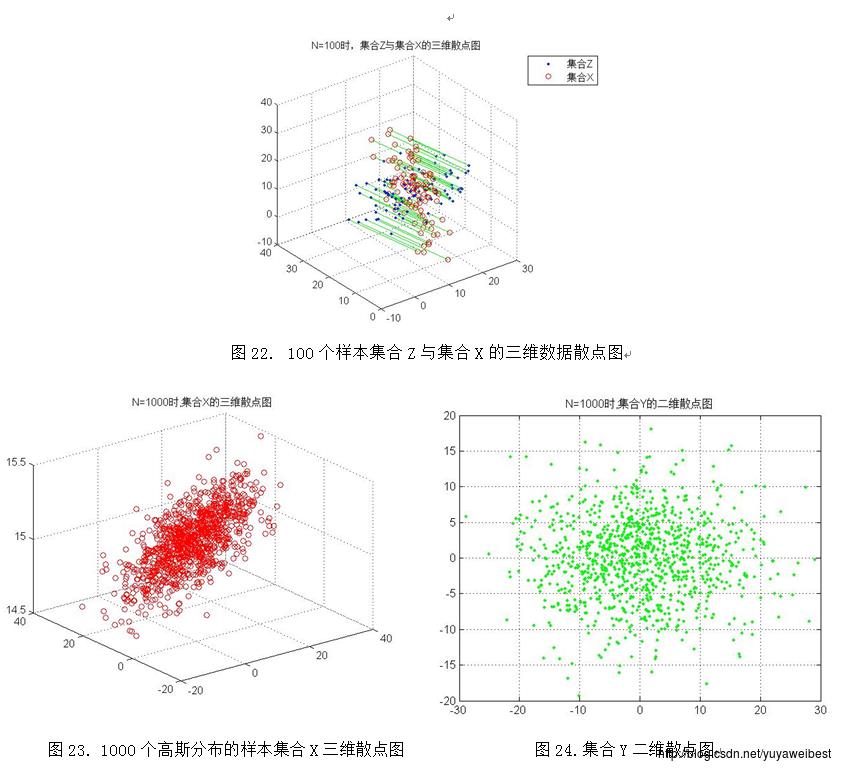
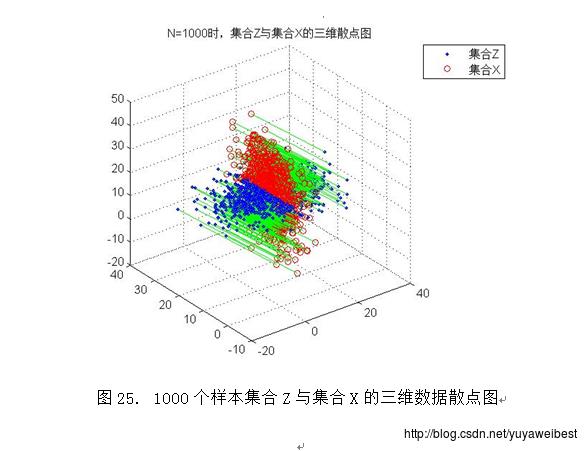
三、 讨论与分析
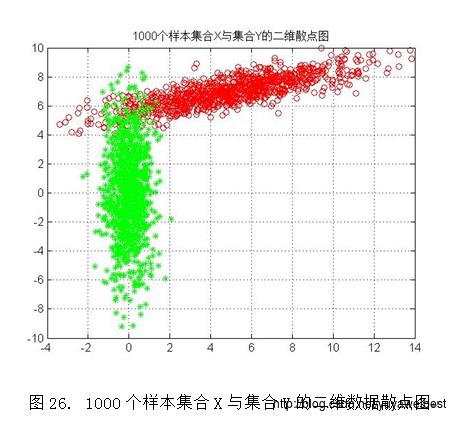
1、 将集合X与集合Y画在同一个图中(以N=1000为例),如下图26所示,经观察可以发现,集合Y是集合X经过平移旋转后得到的散点图,集合Y的分布与集合X正交。该试验中PCA方法的意义是:利用PCA可以对数据集合在特征空间中进行平移和旋转,进行规整化。
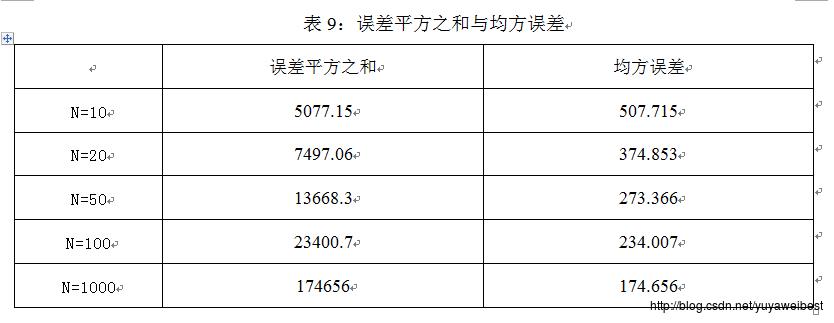
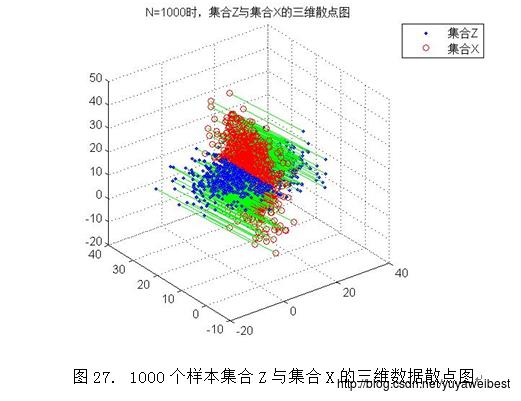
2.PCA降维的基本思想是采取特征线性组合的方式减少特征空间中的维数,将高维数据投影到低维空间中,减少问题分析的复杂度。将样本集合Z与集合X的三维数据散点图(以N=1000为例)进行适度的旋转得到图27,经观察可知集合Z是集合X在某方向上的垂直投影,该方向是由集合X在其散布矩阵S的最大特征值d1与次大特征值d2所对应的特征向量e1、e2构成的基向量形成的平面。
3、观察表1、表2,表5、表6可知,样本的数量越大,估计得到的样本均值向量m越接近给定的均值矢量,散布矩阵S也越接近给定的协方差矩阵的(N-1)倍,信息损失越小。
附录:MATLAB代码
(1)利用PCA进行特征空间的规整化
PCA_two([5,7],[9,2.4;2.4,1],10)
PCA_two([5,7],[9,2.4;2.4,1],100)
PCA_two([5,7],[9,2.4;2.4,1],1000)
PCA_two([5,7],[9,2.4;2.4,1],10000)
PCA_two([5,7],[9,2.4;2.4,1],100000)
%格式:如PCA_two([5,7],[9,2.4;2.4,1],100000),输入参数可变
% MU;样本的均值矢量,本次程序中取[5,7]
% SIGMA;样本的协方差矩阵,本次程序中取[9,2.4;2.4,1]
% N;样本数量,本次程序中取可变值
function PCA_two(MU,SIGMA,N)
X=mvnrnd(MU,SIGMA,N);%产生N个高斯分布的二维样本矢量
figure(1);
subplot(121)
plot(X(:,1),X(:,2),'ro');%画出集合X的二维散点图
grid on
title([num2str(N),'个高斯分布的样本集合X二维散点图']);
X_aver=sum(X)./N;%求样本数据的均值矢量
S=zeros(2);
% 第一种方法注求散布矩阵S
% for i=1:N
% S=S+((X(i,:)-X_aver)'*(X(i,:)-X_aver));
% end
% 第二种方法注求散布矩阵S
for i=1:2
for j=1:2
S(i,j)=sum((X(:,i)-X_aver(:,i)).*(X(:,j)-X_aver(:,j)));
end
end
[V,D]=eig(S);%计算X的散布矩阵S的特征值和特征向量
for m=1:N
Y(m,:)=(V*(X(m,:)-MU)')';
end
subplot(122)
plot(Y(:,1),Y(:,2),'g*');%%画出集合Y的二维散点图
grid on
title([num2str(N),'个样本集合Y的二维散点图']);
figure(2)
plot(X(:,1),X(:,2),'ro',Y(:,1),Y(:,2),'g*');
grid on
title([num2str(N),'个样本集合X与集合Y的二维散点图'])
(2)利用PCA进行特征空间降维
PCA_three([10,15,15],[90,2.5,1.2;2.5,35,0.2;1.2,0.2,0.02],10)
PCA_three([10,15,15],[90,2.5,1.2;2.5,35,0.2;1.2,0.2,0.02],20)
PCA_three([10,15,15],[90,2.5,1.2;2.5,35,0.2;1.2,0.2,0.02],50)
PCA_three([10,15,15],[90,2.5,1.2;2.5,35,0.2;1.2,0.2,0.02],100)
PCA_three([10,15,15],[90,2.5,1.2;2.5,35,0.2;1.2,0.2,0.02],1000)
%格式:PCA_three([10,15,15],[90,2.5,1.2;2.5,35,0.2;1.2,0.2,0.02],100),参数可变
% MU;样本的均值矢量,本次程序中取[10,15,15]
% SIGMA;样本的协方差矩阵,本次程序中取[90,2.5,1.2;2.5,35,0.2;1.2,0.2,0.02]
% N:样本数量,本次程序中取可变值
function PCA_three(MU,SIGMA,N)
X=mvnrnd(MU,SIGMA,N);
figure(1);
plot3(X(:,1),X(:,2),X(:,3),'ro','markersize',6);%画出集合X的三维散点图
grid on
title(['N=',num2str(N),'时,集合X的三维散点图']);
X_aver=sum(X)./N;%求样本数据的均值矢量
S=zeros(3);
% 第一种方法注求散布矩阵S
for i=1:N
S=S+((X(i,:)-X_aver)'*(X(i,:)-X_aver));
end
% 第二种方法注求散布矩阵S
% for i=1:3
% for j=1:3
% S(i,j)=sum((X(:,i)-X_aver(:,i)).*(X(:,j)-X_aver(:,j)));
% end
% end
[V,D]=eig(S);%计算X的散布矩阵S的特征值和特征向量
d=sum(D);
[c1,n1]=max(d);%c1为d的最大值,n1为最大值对应的列
n2=find(d==median(d));%求中间值所在的列
e1=V(:,n1);%最大特征值对应的特征向量
e2=V(:,n2);%次大特征值对应的特征向量
for i=1:N
y1(i,:)=(X(i,:)-X_aver)*e1;
y2(i,:)=(X(i,:)-X_aver)*e2;
end
Y=[y1 y2];%集合Y
figure(2);
plot(Y(:,1),Y(:,2),'g.');%集合Y的二维散点图
title(['N=',num2str(N),'时,集合Y的二维散点图']);
grid on
V_inv=inv(V);%特征向量矩阵V的逆矩阵
W=[V_inv(:,1) V_inv(:,2)];
for j=1:N
Z(j,:)=(W*(Y(j,:))')'+X_aver;
end
figure(3);%在一幅图上画出集合X和Z的三维散点图
plot3(X(:,1),X(:,2),X(:,3),'b.','markersize',6);
hold on
plot3(Z(:,1),Z(:,2),Z(:,3),'ro','markersize',6);
hold on
title(['N=',num2str(N),'时,集合Z与集合X的三维散点图']);
legend('集合Z','集合X');
grid on
for i=1:N
plot3([Z(i,1) X(i,1)],[Z(i,2) X(i,2)],[Z(i,3) X(i,3)],'color','g')
%找出X与Z的对应关系并用绿线连接起来
end
grid on
E=(Z-X).^2;
E_sum=sum(E(:,1)+E(:,2)+E(:,3));%误差平方之和
E_mean=E_sum/N;%均方误差
以上是关于主分量分析PCA的主要内容,如果未能解决你的问题,请参考以下文章