机器学习算法分类及其评估指标
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习算法分类及其评估指标相关的知识,希望对你有一定的参考价值。
机器学习的入门,我们需要的一些基本概念:
机器学习的定义
M.Mitchell《机器学习》中的定义是:
对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么我们称这个计算机程序从经验E中学习。
算法分类
两张图片很好的总结了(机器学习)的算法分类:
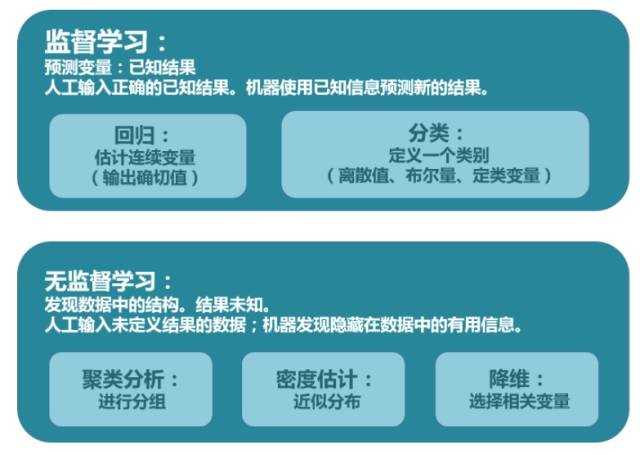

评估指标
分类(Classification)算法指标:
- Accuracy准确率
- Precision精确率
- Recall召回率
- F1 score
对于分类问题的结果可以用下表表示(说明:True或者False代表预测结果是否正确,Positive和Negative代表被程序找出的结果):

Accuracy准确率
准确率的定义是对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。公式为:
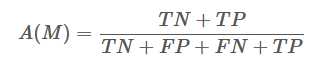
准确率存在准确率悖论的缺陷,参考这里的具体说明。
Precision精确率
精确率计算的是: 预测结果中符合实际值的比例,可以理解为没有“误报”的情形,公式为:
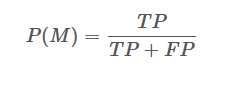
Recall 召回率
召回率计算的是:正确分类的数量与所有“应该”被正确分类(符合目标标签)的数量的比例,可以理解为精确率对应的没有“漏报”的情形。公式为:
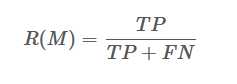
F1 score
F1 值是精确率和召回率的调和均值,定义为:
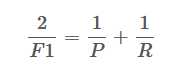 即,
即, 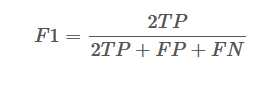
应用场景:
准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了。当精确率和召回率都高时,F1的值也会高。在两者都要求高的情况下,可以用F1来衡量。
- 地震的预测
对于地震的预测,我们希望的是RECALL非常高,也就是说每次地震我们都希望预测出来。这个时候我们可以牺牲PRECISION。情愿发出1000次警报,把10次地震都预测正确了;也不要预测100次对了8次漏了两次。 - 嫌疑人定罪
基于不错怪一个好人的原则,对于嫌疑人的定罪我们希望是非常准确的。及时有时候放过了一些罪犯(recall低),但也是值得的。
回归(Regression)算法指标:
- Mean Absolute Error平均绝对偏差
- Mean Squared Error均方误差
- R2 score
- Explained Variance Score
平均绝对误差
公式: 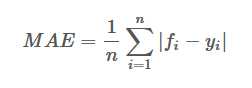
均方误差
公式: 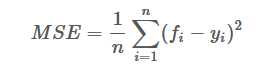
R2 score
即“Coefficient of determination"决定系数,判断的是预测模型和真实数据的拟合程度,最佳值为1,可为负值。
y

Explained Variance Score

Reference
【2】:机器学习概念参考:http://underthehood.blog.51cto.com/2531780/577854
【3】:机器学习总结: 链接
以上是关于机器学习算法分类及其评估指标的主要内容,如果未能解决你的问题,请参考以下文章