机器学习分类算法评价指标
Posted 苍老流年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习分类算法评价指标相关的知识,希望对你有一定的参考价值。
一. 分类评价指标
对机器学习算法的性能进行评估时,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价指标,这就是算法评价指标。分类算法的评价指标一般有准确率,精确率,召回率,F1-score,PR曲线,ROC,AUC。
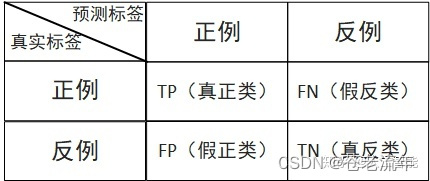
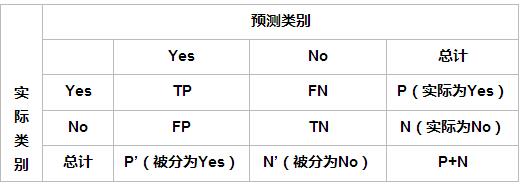
在介绍具体的评价指标前,需要先以二分类为例引入混淆矩阵。
混淆矩阵
针对一个二分类问题,即将实例分成正类(positive)或反类(negative),在实际分类中会出现以下四种情况:
(1)若一个样本是正类,并且被预测为正类,即为真正类TP(True Positive )
(2)若一个样本是正类,但是被预测为反类,即为假反类FN(False Negative )
(3)若一个样本是反类,但是被预测为正类,即为假正类FP(False Positive )
(4)若一个样本是反类,并且被预测为反类,即为真反类TN(True Negative )
混淆矩阵的每一行是样本的预测分类,每一列是样本的真实分类,如下图所示。
二. 准确率(accuracy),精确率(precision),召回率(recall),F1-score
1. 准确率(accuracy)
精确率是预测正确的样本占所有样本的百分比。
a
c
c
u
r
a
c
y
=
T
P
+
T
N
T
P
+
F
P
+
T
N
+
F
N
accuracy = \\fracTP + TNTP + FP +TN + FN
accuracy=TP+FP+TN+FNTP+TN
局限:当数据的正负样本不均衡,仅仅使用这个指标来评价模型的性能优劣是不合适的。
假如一个测试集有正样本99个,负样本1个。模型把所有的样本都预测为正样本,那么模型的Accuracy为99%,看评价指标,模型的效果很好,但实际上模型没有任何预测能力。
2. 精确率(precision)
又叫查准率,它是模型预测为正样本的结果中,真正为正样本的比例。
p
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
precision=\\fracTPTP + FP
precision=TP+FPTP
3. 召回率(recall)
又叫查全率,它是实际为正的样本中,被预测为正样本的比例。
r
e
c
a
l
l
=
T
P
T
P
+
F
N
recall=\\fracTPTP + FN
recall=TP+FNTP
4. F1-score
F1-score是precision和recall的调和平均值。
F
1
=
2
∗
P
r
e
c
i
s
i
o
n
∗
R
e
c
a
l
l
P
r
e
c
i
s
i
o
n
+
R
e
c
a
l
l
F1 =\\frac2 * Precision * Recall Precision + Recall
F1=Precision+Recall2∗Precision∗Recall
5. 编码实现
import numpy as np
from sklearn import datasets
import warnings
warnings.filterwarnings("ignore")
digits = datasets.load_digits()
x = digits.data
y = digits.target.copy()
y[digits.target == 9] = 1
y[digits.target != 9] = 0
x.shape
(1797, 64)
y.shape
(1797,)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(x_train, y_train)
y_log_predict = log_reg.predict(x_test)
log_reg.score(x_test, y_test)
0.9755555555555555
#### 手动计算混淆矩阵
def TN(y_true, y_predict):
assert len(y_true) == len(y_predict)
return np.sum((y_true ==0) & (y_predict == 0))
TN(y_test, y_log_predict)
403
def FP(y_true, y_predict):
assert len(y_true) == len(y_predict)
return np.sum((y_true ==0) & (y_predict == 1))
FP(y_test, y_log_predict)
2
def FN(y_true, y_predict):
assert len(y_true) == len(y_predict)
return np.sum((y_true ==1) & (y_predict == 0))
FN(y_test, y_log_predict)
9
def TP(y_true, y_predict):
assert len(y_true) == len(y_predict)
return np.sum((y_true ==1) & (y_predict == 1))
TP(y_test, y_log_predict)
36
def my_confusion_matrix(y_true, y_predict):
return np.array([
[TN(y_true, y_predict),FP(y_true, y_predict)],
[FN(y_true, y_predict),TP(y_true, y_predict)]
])
my_confusion_matrix(y_test, y_log_predict)
array([[403, 2],
[ 9, 36]])
# 使用sklearn 提供的api计算混淆矩阵
from sklearn.metrics import confusion_matrix
confusion_matrix(y_test, y_log_predict)
array([[403, 2],
[ 9, 36]])
#手动计算precision
def my_precision_score(y_true, y_predict):
return TP(y_true, y_predict) / (TP(y_true, y_predict) + FP(y_true, y_predict))
my_precision_score(y_test, y_log_predict)
0.9473684210526315
# 使用sklearn提供的api计算precision
from sklearn.metrics import precision_score
precision_score(y_test, y_log_predict)
0.9473684210526315
#手动计算recall
def my_recall_score(y_true, y_predict):
return TP(y_true, y_predict) / (TP(y_true, y_predict) + FN(y_true, y_predict))
my_recall_score(y_test,y_log_predict)
0.8
#使用sklearn 提供的api计算recall
from sklearn.metrics import recall_score
recall_score(y_test, y_log_predict)
0.8
# 手动计算F1-score
def my_f1_score(precision, recall):
try:
return 2 * precision * recall / (precision + recall)
except:
return 0.0
my_f1_score(precision_score(y_test, y_log_predict), recall_score(y_test, y_log_predict))
0.8674698795180723
# 使用sklearn 提供的api计算F1-score
from sklearn.metrics import f1_score
f1_score(y_test, y_log_predict)
0.8674698795180723
三. PR曲线
1. PR曲线
P-R曲线是描述精确率和召回率变化的曲线。对于所有的正样本,设置不同的阈值,模型预测所有的正样本,再根据对应的精准率和召回率绘制相应的曲线。
一般情况下一个分类模型不可能同时获得高的精准率与召回率,当精准率较高时,召回率会降低;当召回率较高时,精准率会降低。

模型与坐标轴围成的面积越大,则模型的性能越好。但一般来说,曲线下的面积是很难进行估算的,所以衍生出了“平衡点”(Break-Event Point,简称BEP),即当P=R时的取值,平衡点的取值越高,性能更优。
2. 编码实现
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
digits = datasets.load_digits()
x = digits.data
y = digits.target.copy()
y[digits.target == 9] = 1
y[digits.target != 9] = 0
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(x_train, y_train)
y_log_predict = log_reg.predict(x_test)
log_reg.score(x_test, y_test)
0.9755555555555555
# 获取分类算法的分类阈值
decision_scores = log_reg.decision_function(x_test)
手动绘制PR曲线
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
precisions = []
recalls = []
thresholds = np.arange(np.min(decision_scores), np.max(decision_scores), 0.1)
for threshold in thresholds:
y_predict = np.array(decision_scores >= threshold, dtype = 'int')
precisions.append(precision_score(y_test, y_predict))
recalls.append(recall_score(y_test, y_predict))
plt.plot(precisions, recalls)
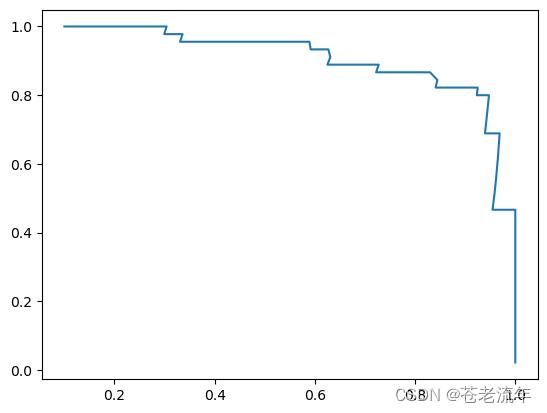
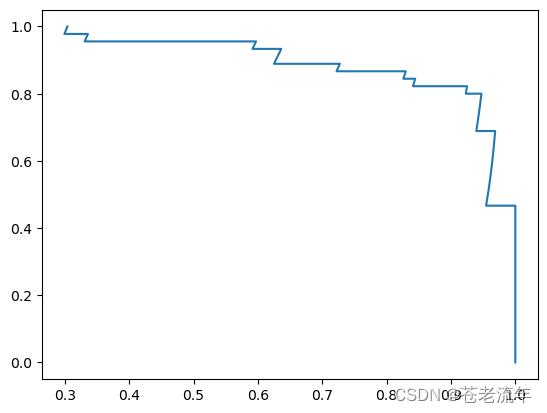
使用sklearn API绘制PR曲线
from sklearn.metrics import precision_recall_curve
precisions1, recalls1, thresholds1 = precision_recall_curve(y_test, decision_scores)
plt.plot(precisions1, recalls1)
四. ROC和AUC
1. ROC曲线
ROC(Receiver Operating Characteristic)曲线,又称接受者操作特征曲线。曲线对应的纵坐标是TPR,横坐标是FPR。下面先介绍下TPR和FPR。
-
TPR(true positive rate):真正类率,也称为灵敏度(sensitivity),等同于召回率。表示被正确分类的正实例占所有正实例的比例。
T P R = T P T P + F N TPR=\\fracTPTP + FN TPR=TP+FNTP -
FPR(false positive rate):负正类率,表示被错误分类的负实例占所有负实例的比例。
F P R = F P F P + T N FPR=\\fracFPFP + TN FPR=FP+TNFP
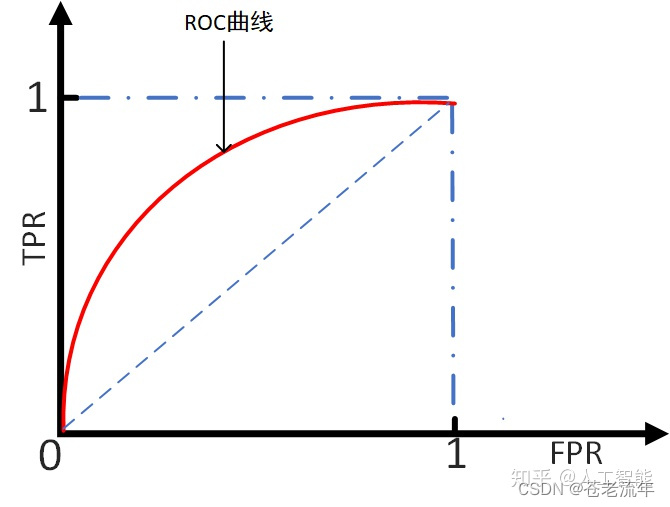
设置不同的阈值,会得到不同的TPR和FPR,而随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着负类,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。理想目标: TPR=1, FPR=0,即图中(0,1)点。故ROC曲线越靠拢(0,1)点,即,越偏离45度对角线越好。对应的就是TPR越大越好,FPR越小越好。
2. AUC
AUC(Area Under Curve)是处于ROC曲线下方的那部分面积的大小。AUC越大,代表模型的性能越好。
一个分类模型的AUC值越大,则认为算法表现的越好。
3. 编码实现
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
digits = datasets.load_digits()
x = digits.data
y = digits.target.copy()
y[digits.target == 9] = 1
y[digits.target != 9] = 0
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=666)
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(x_train, y_train)
y_log_predict = log_reg.predict(x_test)
log_reg.score(x_test, y_test)
0.9755555555555555
# 获取分类算法的分类阈值
decision_scores = log_reg.decision_function(x_test)
使用sklearn API绘制ROC曲线
from sklearn.metrics import roc_curve
fprs1, tprs1, thresholds = roc_curve(y_test, decision_scores)
plt.plot(fprs1, tprs1)
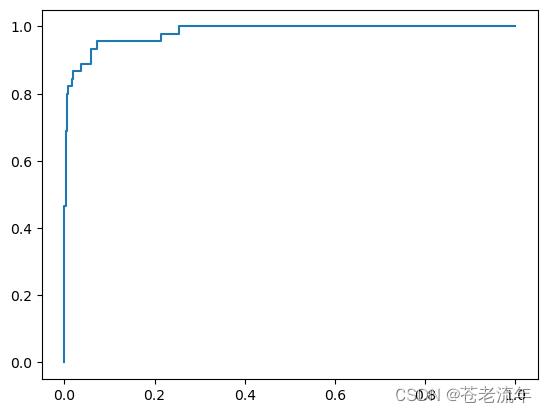
使用sklearn API计算auc的值
from sklearn.metrics import roc_auc_score
roc_auc_score(y_test, decision_scores)
0.9824417009602195
机器学习算法中的评价指标(准确率召回率F值ROCAUC等)
参考链接:https://www.cnblogs.com/Zhi-Z/p/8728168.html
具体更详细的可以查阅周志华的西瓜书第二章,写的非常详细~
一、机器学习性能评估指标
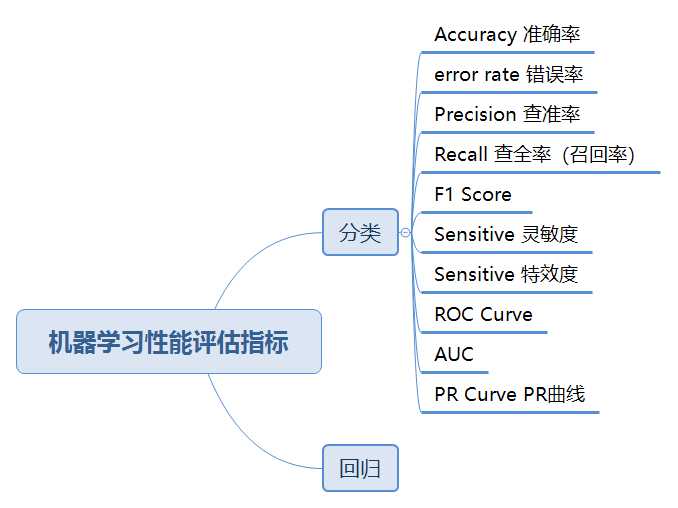
1.准确率(Accurary)
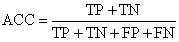
准确率是我们最常见的评价指标,而且很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。
准确率确实是一个很好很直观的评价指标,但是有时候准确率高并不能代表一个算法就好。比如某个地区某天地震的预测,假设我们有一堆的特征作为地震分类的属性,类别只有两个:0:不发生地震、1:发生地震。一个不加思考的分类器,对每一个测试用例都将类别划分为0,那那么它就可能达到99%的准确率,但真的地震来临时,这个分类器毫无察觉,这个分类带来的损失是巨大的。为什么99%的准确率的分类器却不是我们想要的,因为这里数据分布不均衡,类别1的数据太少,完全错分类别1依然可以达到很高的准确率却忽视了我们关注的东西。再举个例子说明下。在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc也有 99% 以上,没有意义。因此,单纯靠准确率来评价一个算法模型是远远不够科学全面的。
2、错误率(Error rate)
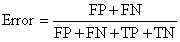
错误率则与准确率相反,描述被分类器错分的比例,对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate。
3、查准率(Precision)
查准率(precision)定义为: 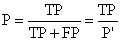
表示被分为正例的示例中实际为正例的比例。
4、查全率(召回率)(recall)

召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率与灵敏度是一样的。
5、综合评价指标(F-Measure)
P和R指标有时候会出现的矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure(又称为F-Score)。 F-Measure是Precision和Recall加权调和平均:
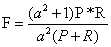
当参数α=1时,就是最常见的F1,也即 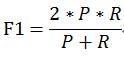
可知F1综合了P和R的结果,当F1较高时则能说明试验方法比较有效。
6、灵敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力。
7、特效度(sensitive)
specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力。
8、其他评价指标
8.1 ROC曲线
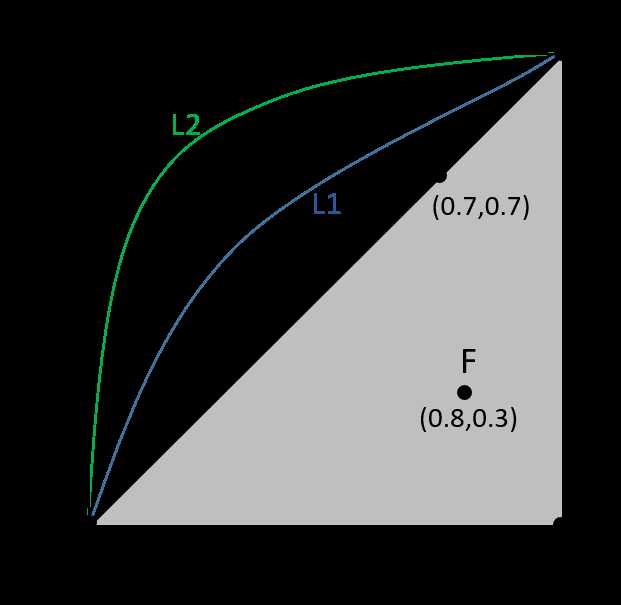
ROC(Receiver Operating Characteristic)曲线是以假正率(FP_rate)和真正率(TP_rate)为轴的曲线,ROC曲线下面的面积我们叫做AUC,如下图所示
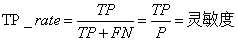 ,
,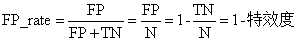
(1)曲线与FP_rate轴围成的面积(记作AUC)越大,说明性能越好,即图上L2曲线对应的性能优于曲线L1对应的性能。即:曲线越靠近A点(左上方)性能越好,曲线越靠近B点(右下方)曲线性能越差。
(2)A点是最完美的performance点,B处是性能最差点。
(3)位于C-D线上的点说明算法性能和random猜测是一样的,如C、D、E点;位于C-D之上(曲线位于白色的三角形内)说明算法性能优于随机猜测,如G点;位于C-D之下(曲线位于灰色的三角形内)说明算法性能差于随机猜测,如F点。
(4)虽然ROC曲线相比较于Precision和Recall等衡量指标更加合理,但是其在高不平衡数据条件下的的表现仍然不能够很好的展示实际情况。
8.2、PR曲线:
即,PR(Precision-Recall),以查全率为横坐标,以查准率为纵坐标的曲线。
举个例子(例子来自Paper:Learning from eImbalanced Data):
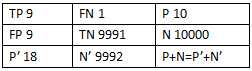
假设N>>P(即Negative的数量远远大于Positive的数量),就算有较多N的sample被预测为P,即FP较大为9,但是由于N很大,FP_rate的值仍然可以很小0.9%,TP_rate=90%(如果利用ROC曲线则会判断其性能很好,但是实际上其性能并不好),但是如果利用PR,P=50%,R=90%,因此在极度不平衡的数据下(Positive的样本较少),PR曲线可能比ROC曲线更实用。
以上是关于机器学习分类算法评价指标的主要内容,如果未能解决你的问题,请参考以下文章