贝叶斯分类器
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了贝叶斯分类器相关的知识,希望对你有一定的参考价值。
贝叶斯分类是统计学的一个分类方法,基于贝叶斯定理。首先贝叶斯分类的一个核心如果是一个属性值对给定类的影响独立于其它属性的值(类条件独立)。
先来看下条件概率:
设A、B是两个事件,且P(B)>0,则称 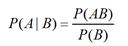 为在事件B发生的条件下,事件A的条件概率。
为在事件B发生的条件下,事件A的条件概率。
再来看一下贝叶斯定理: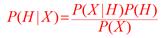 。
。
当中:
X 是类标识未知的数据样本(或数据元组)
如:35岁收入$4000的顾客
H 是数据样本X属于某特定类C的某种假定。
如:如果顾客将购买计算机
P(H/X):条件X下H的后验概率
如:知道顾客年龄与收入时,顾客将购买计算机的概率
P(H):H的先验概率,即在我们观察不论什么样本前的初始概率,它反应了背景知识。
如:随意给定的顾客将购买计算机的概率。
P(X):被观察的样本数据的概率
如:顾客中年龄35岁收入$4000的概率
P(X|H) :条件H下。X的后验概率
如:已知顾客购买计算机。该顾客为35岁收入$4000的概率
朴素贝叶斯分类器
因为P(X)对于不论什么一个类别H而言,其值都是固定的,因此在计算P(H|X)时不须要考虑。
上面已经提到了朴素贝叶斯分类的核心如果是X向量中的每个參数xi与xj之间都是相互独立的(类条件独立)。因此有以下计算P(X|H)的公式:
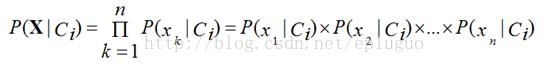
可将Ci看成为H。
对未知样本X分类,也就是对每一个类Ci。计算p(X|Ci)*p(Ci)。
样本X被指派到类Ci,当且仅当p(Ci|X) > p(Cj|X), 1≤j≤m , j≠i,换言之,X被指派到p(X|Ci) *p(Ci)最大的类。
有了上面的知识,朴素贝叶斯分类器就变成了简单的概率计算了。基于训练集的数据。事先计算出每一个类别的概率P(Ci),再计算出每一个类别下每一个參数的概率P(xi|Ci)。当面临一个新样本时,利用上面简化的贝叶斯公式计算出P(Ci|X),值最大的Ci记为分类结果。为了防止出现零概率现象,能够在保存的每一个概率的分子分母都+1。
以下看一个样例:
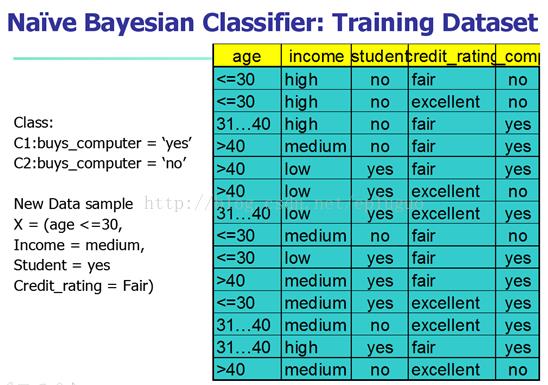

以上是关于贝叶斯分类器的主要内容,如果未能解决你的问题,请参考以下文章