Pascal GPU 架构详解
Posted 卜居
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pascal GPU 架构详解相关的知识,希望对你有一定的参考价值。
本文作于 2016/12/25,作者卜居。
写在前面:本文假定读者有一定 CUDA 基础。如果你对 GPU, sm_60/sm_61,CUDA 这些名词感到陌生,可以看我之前写的博客《CUDA 从入门到精通》。
1. 前言
Nvidia 在今年的 GTC( GPU Technology Conference ) 上高调宣布了 Pascal 架构——专门针对每瓦性能优化的新架构,采用 16nm 工艺。接着发布了该系列的扛鼎之作 P100 及其装进机箱后的产品 DGX-1:

Tesla P100 采用顶级大核心 GP100,面积 610 mm^2,位于下图中间位置

GP100 参数汇总如下:
- 芯片:GP100
- 架构:SM_60
- 工艺:16 nm FinFET
- 支持:双精度 FP64, 单精度 FP32, 半精度 FP16
- 功耗:250 W
- CUDA 核心数:3584(56 SMs, 64 SPs/SM)
- GPU 时钟(Base/Boost):1189 MHz/1328 MHz
- PCIe:Gen 3 x16
- 显存容量:12/16 GB HBM2
- 显存位宽:3072/4096 bits
- 显存时钟:715 MHz
- 显存带宽:539/732 GB/s
DGX-1 拥有 8 颗帕斯卡架构 GP100 核心的 Tesla P100 GPU,一共组成了 128 GB 的显存。
浮点运算(FP16) 达到了 170 TFlops(官方宣称相当于 250 个 x86服务器),内置 7 TB 的 SSD,两颗 16 核心的 Xeon E5-2698v3 以及 512 GB 的 DDR4 内存,整机功耗 3200W,售价为129000$。
看完上述配置,深刻感到这玩意是土豪套餐,不是人人都用得起。但是看看文档又不花钱,何乐而不为。
2. GP100 GPU 硬件架构
GP100 以最高性能并行计算处理器自居,面向 GPU 加速计算的市场。
GP100 包含一组 GPC(图形处理簇,Graphics Processing Clusters)、TPC(纹理处理簇,Texture Processing Clusters)、SM(流多处理器,Stream Multiprocessors)以及内存控制器。其架构如下:
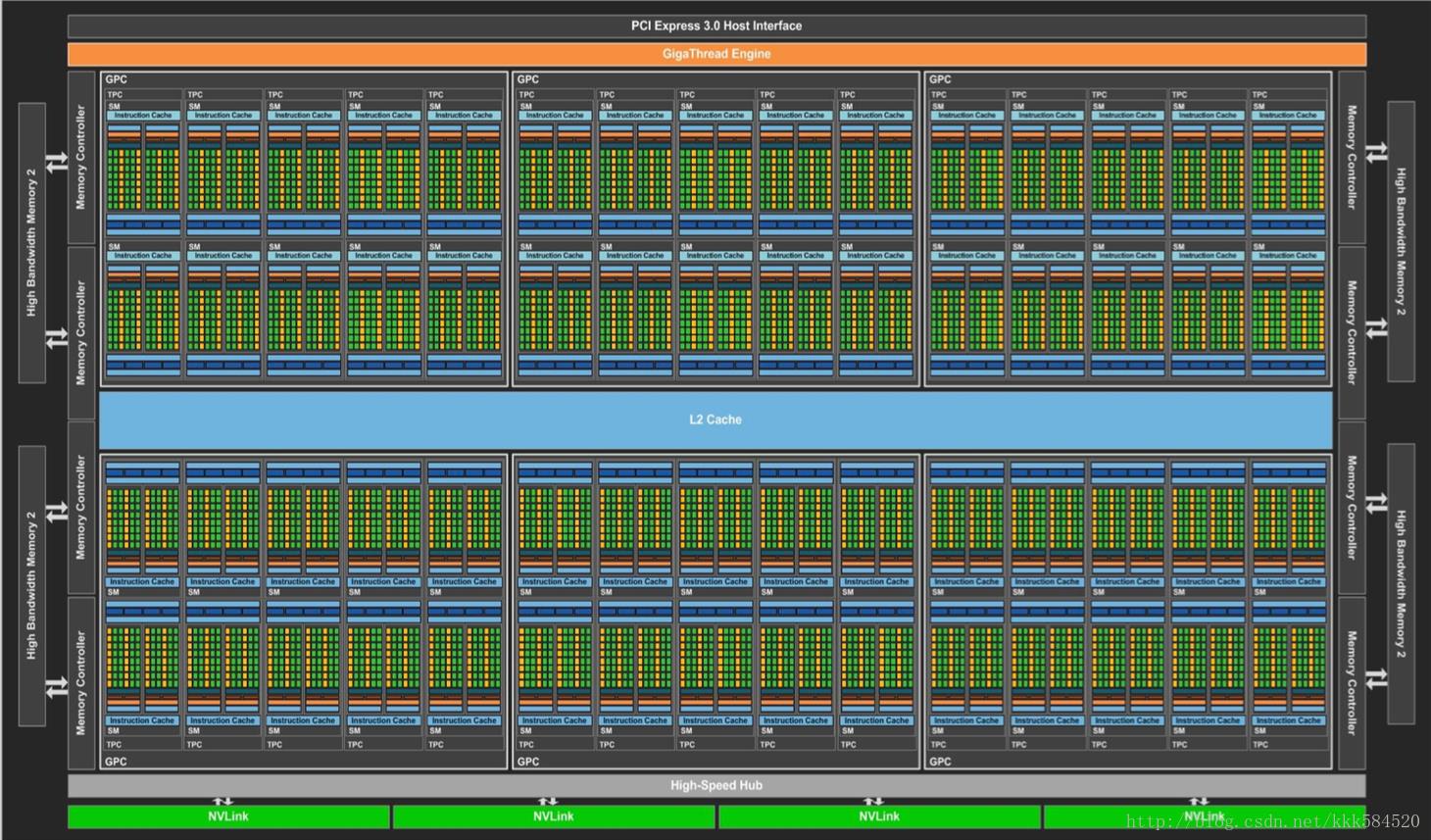
(如果图看不清,可以右键-另存为保存到本地打开,可以缩放到适合尺寸)
下面就是数字游戏了。
一颗完整的 GP100 芯片包括 6 个图形处理簇,60 个 Pascal 流多处理器,30 个纹理处理簇和 8 个 512 位内存控制器(总共 4096 位)。
每个图形处理簇内部包括 10 个 流多处理器。
每个流多处理器内部包括 64 个 CUDA 核心和 4 个纹理单元。
问题:Tesla P100 内共有多少 CUDA 核心?
回答 1:根据材料显示,GP100 内一共有 60 个 SM,每个 SM 有 64 个 CUDA 核心,那么 GP100 总共有 60 x 64 = 3840 CUDA 核心。
正确答案:回答 1 推断能力很强,但结果与实际不符。在 Tesla P100 上运行 deviceQuery 得到如下信息:
(56) Multiprocessors, ( 64) CUDA Cores/MP: 3584 CUDA Cores事实上,Tesla P100 只用了 GP100 上 60 个 SM 中的 56 个。
所以,一切还是要从实际出发。
进一步细看 GP100 SM 的架构。
GP100 的第六代 SM 架构提高了 CUDA 核心利用率和能效,核心频率更高,整体 GPU 性能有较大提升。
GP100 的 SM 包括 64 个单精度 CUDA 核心。而 Maxwell 和 Kepler 的 SM 分别有 128 和 192 个单精度 CUDA 核心。虽然 GP100 SM 只有 Maxwell SM 中 CUDA 核心数的一半,但总的 SM 数目增加了,每个 SM 保持与上一代相同的寄存器组,则总的寄存器数目增加了。这意味着 GP100 上的线程可以使用更多寄存器,也意味着 GP100 相比旧的架构支持更多线程、warp 和线程块数目。与此同时,GP100 总共享内存量也随 SM 数目增加而增加了,带宽显著提升不至两倍。

图中为一个 SM 的架构。其中绿色的“Core” 为单精度 CUDA 核心,共有 64 个,同时支持 32 位单精度浮点计算和 16 位半精度浮点计算,其中 16 位计算吞吐是 32 位计算吞吐的两倍。图中橘黄色的 “DP Unit” 为双精度计算单元,支持 64 位双精度浮点计算,数量为 32 个。每个 GP100 SM 双精度计算吞吐为单精度的一半。下面这张处理性能表证实了这一点。

Pascal SM 架构图中可以看到,一个 GP100 SM 分成两个处理块,每块有【 32768 个 32 位寄存器 + 32 个单精度 CUDA 核心 + 16 个双精度 CUDA 核心 + 8 个特殊功能单元(SFU) + 8 个存取单元 + 一个指令缓冲区 + 一个 warp 调度器 + 两个分发单元】。
Pascal SM 架构相比 Kepler 架构简化了数据通路,占用面积更小,功耗更低。
Pascal SM 架构提供更高级的调度和重叠载入/存储指令来提高浮点利用率。
GP100 中新的 SM 调度器架构相比 Maxwell 更智能,具备高性能、低功耗特性。
一个 warp 调度器(每个处理块共享一个)在一个时钟周期内可以分发两个 warp 指令。
双精度算法是很多 HPC 应用(如线性代数,数值模拟,量子化学等)的核心。GP100 的一个关键设计目标就是显著提升这些案例的性能。
GP100 中每个 SM 都有 32 个双精度(FP64)CUDA 核心,即单精度(FP32)CUDA 核心数目的一半。GP100 和以前架构相同,支持 IEEE 754-2008 标准,支持 FMA 运算,支持异常值处理。
注意:在 Kepler GK110 中单精度核心数目:双精度核心数目为 3:1。
半精度算法提升深度学习性能。深度学习是增长最快的计算领域之一,它是很多重要应用(实时语言翻译,高准确率图像识别,自动图片标题,自动驾驶中的目标识别、最优路径计算、防碰撞系统等)的构成部分。
深度学习是个两步过程:(1) 神经网络训练;(2) 使用训练好的结果,将网络部署到现场,对未知输入进行预测(分类,识别)。
深度神经网络天然对错误不敏感。使用 FP16 存储数据可以有效减少神经网络内存占用,允许训练、部署更大的网络。
使用 FP16 计算相比 FP32 可以带来 2 倍性能提升,数据传输时间也可以大大降低。
注意:GP100 上,两个 FP16 运算可以使用一个双路指令完成。
相比上一代产品和上上代产品情况如下表所示
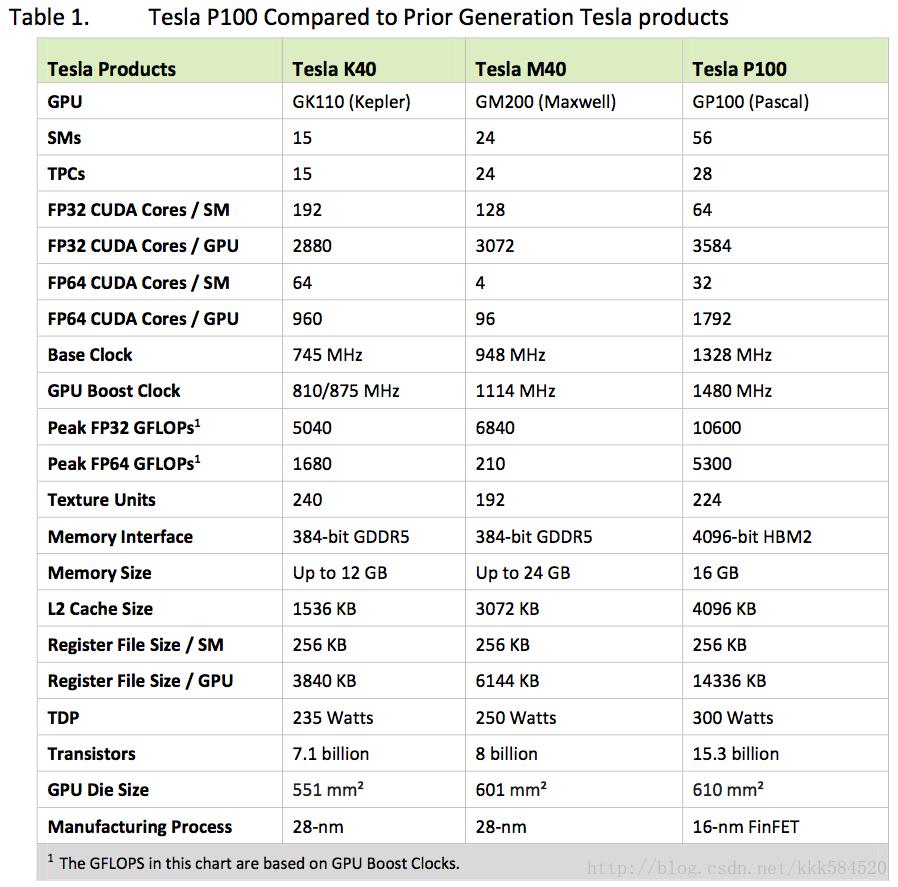
表现出了优异的高性能和高能效。
Maxwell 架构相对 Kepler 做了改进,提升了效率。
Pascal 基于 Maxwell 架构,利用 TSMC 16 nm FinFET 工艺进一步降低了能耗。
【卜居注:半导体行业在 Intel 带领下都学会了 tick-tock 策略】
计算能力
GP100 GPU 支持最新 6.0 计算能力。

3. GP104 GPU 硬件架构
Pascal 架构的消费级显卡 GTX 1080 是面向普通消费者的图形加速卡,先来张靓照:

GTX1080 参数汇总如下:
- 芯片:GP104, sm_61
- 工艺:16 nm FinFET
- 支持:单精度 FP32, 整数 INT8
- 功耗:180 W
- Nvidia CUDA 核心数:2560(20 SMs, 128 SPs/SM)
- GPU 时钟:Base = 1607 MHz, Maximum Boost = 1733 MHz
- PCIe:Gen 3 x16
- 显存容量:8 GB GDDR5X
- 显存位宽:256 bits
- 显存时钟:1251 MHz
- 显存带宽:320 GB/s
其中 GTX1080 的 GPU 芯片使用 GP104,与 Tesla P100 中的 GPU 芯片 GP100 相比有如下不同:
(1) GP100 具有 6.0 计算能力,GP104 则具有 6.1 计算能力;
(2) GP100 支持双精度,GP104 双精度支持较弱;
(3) GP100 支持半精度,GP104 半精度支持较弱;
(4) GP100 不支持 INT8,GP104 支持 INT8;
(5) GP100 使用 HBM2 作为显存,GP104 使用 GDDR5X;
(6) GP100 每个 SM 上有 64 个 CUDA core,而 GP104 上每个 SM 有 128 个 CUDA core;
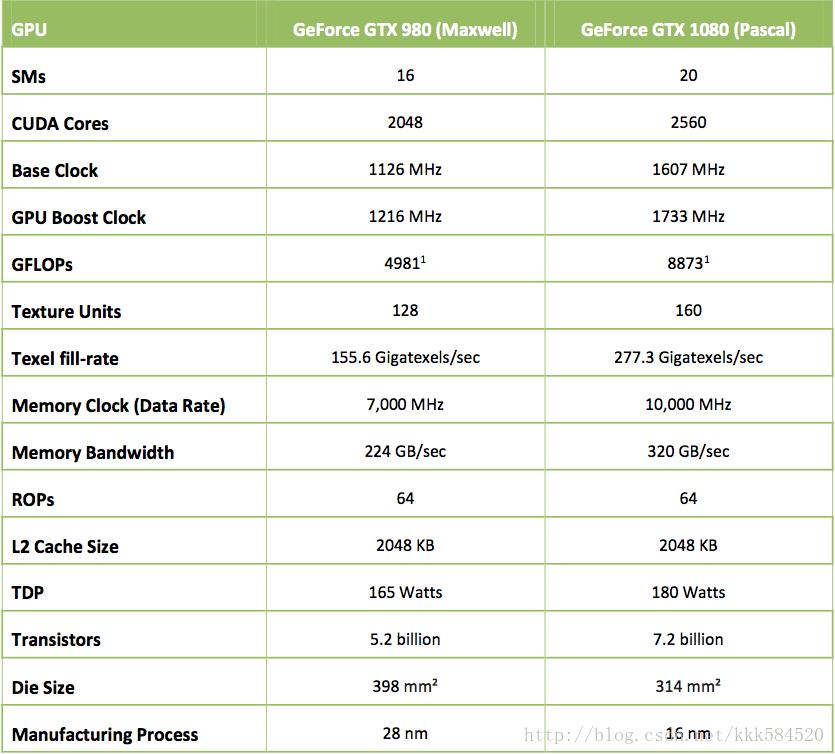
得益于新的 Pascal 架构、16 nm 工艺、GDDR5X 显存等,GTX1080 比上一代 GTX980 性能提升超过 70%,是目前最快的游戏卡。
我们深入 GP104 芯片内部一探究竟。
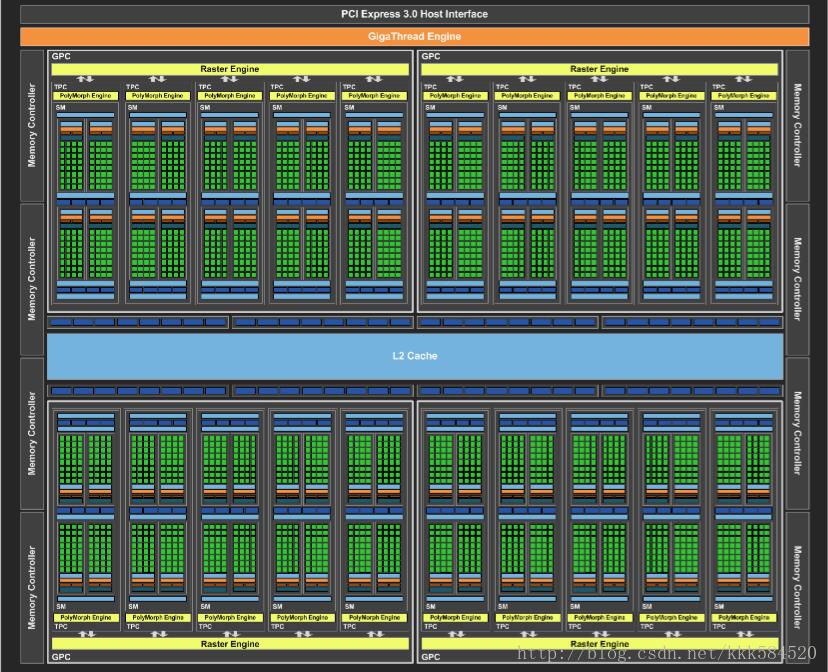
整个 GP104 芯片内置 4 个 GPC(图形处理簇),共计 20 个 SM(流多处理器),以及 8 个内存控制器。
细看每个 SM 架构如下图:

每个 GP104 SM 包括 128 CUDA core,没有 DPUnit。每个 CUDA core 支持 dp2a(双路 16 bit 整数乘累加指令)、dp4a(四路 8 bit 整数乘累加指令)。因此, GP104 十分适合做定点乘加计算,这在深度学习的模型定点化实现压缩方面有用途。
每个 GP104 SM 还内置 96 KB 共享内存、48 KB L1 缓存、256 KB 寄存器、8 个纹理单元。
4. Pascal GPU 选型
很多深度学习爱好者可能都想自己攒一台机器用于模型训练、调参,而 Nvidia 今年推出的 Pascal 架构消费级 GPU 也十分吸引眼球。这里我们做一个简单的选型对比,希望能帮到那些仍然犹豫买哪一款的朋友。
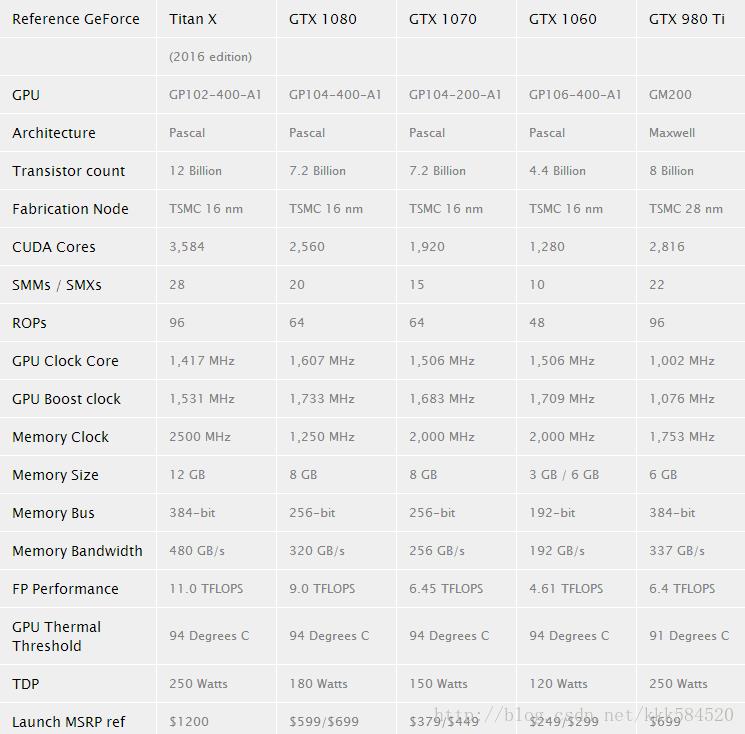
从上表对比来看,GTX1080 应该是个不错的选择,差不多人民币 5000 元左右就能买到 9.0 TFLOPS 计算能力。而更高端的 Titan X(Pascal) 则需要付出多一倍的价格,仅换得额外 2.0 TFLOPS 计算能力,其实还不如买两块 GTX1080 划算。
GTX1070 和 GTX1080 的 GPU 芯片均为 GP104。但 GTX1070 使用 GDDR5,而 GTX1080 使用 GDDR5X。
对于 GP102、GP106 架构,从目前还没看到公布的架构资料,但根据一些指标来看和 GP104 差别不大。如果官方公布架构细节,本文也会随时更新。
5. 使用 Pascal 架构 GPU 时的注意事项
Pascal 架构是全新的,所以需要使用全新的开发环境。安装 CUDA 至少要 8.0,cuDNN 则至少要 v5.1.5。
在编译 Caffe 时,应当在 Makefile.config 时找到如下语句:
CUDA_ARCH := -gencode arch=compute_20,code=sm_20 \\
-gencode arch=compute_20,code=sm_21 \\
-gencode arch=compute_30,code=sm_30 \\
-gencode arch=compute_35,code=sm_35 \\
-gencode arch=compute_50,code=sm_50 \\
-gencode arch=compute_50,code=compute_50
改为:
CUDA_ARCH := -gencode arch=compute_20,code=sm_20 \\
-gencode arch=compute_20,code=sm_21 \\
-gencode arch=compute_30,code=sm_30 \\
-gencode arch=compute_35,code=sm_35 \\
-gencode arch=compute_50,code=sm_50 \\
-gencode arch=compute_50,code=compute_50 \\
-gencode arch=compute_60,code=sm_60 \\
-gencode arch=compute_61,code=sm_61
为了编译速度更快,可以删掉旧的计算架构,例如你编译用于 GTX1080 的代码时,可以改为:
CUDA_ARCH := -gencode arch=compute_61,code=sm_61
只是一旦这么做,你的代码就只能运行在 6.1 及以上架构,而不能直接运行在更低版本架构(如 Maxwell、Kepler、Fermi 等)。
6. 参考文献
【1】 Whitepaper NVIDIA Tesla P100:The Most Advanced Datacenter Accelerator Ever Built Featuring Pascal GP100, the World’s Fastest GPU
【2】 Whitepaper NVIDIA GeForce GTX 1080:Gaming Perfected
【3】 https://devblogs.nvidia.com/parallelforall/cuda-8-features-revealed/
【4】 https://developer.nvidia.com/rdp/cudnn-download
以上是关于Pascal GPU 架构详解的主要内容,如果未能解决你的问题,请参考以下文章
GPU结构与CUDA系列2GPU硬件结构及架构分析:流多处理器SM,流处理器SP,示例架构分析
嵌入式人工智慧大跃进, NVIDIA 推出具 Pascal 架构的 Jetson TX2 单板电脑