经验分享谈谈 GPU 利用率
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了经验分享谈谈 GPU 利用率相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],回复001获取Google编程规范
大家好,我是极智视界,本文主要谈谈 GPU 利用率,以 Nvidia GPU 为例。
GPU 的硬件架构不完全相同,有如下发展轨迹:Turing (图灵) > Volta (沃尔特) > Pascal (帕斯卡) > Maxwell (麦克斯韦) > Kepler (开普勒) > Fermi (费米) > Tesla (特斯拉)。以 NVIDIA T4 为例,其是基于 Turing 框架,Turing 架构中 SM 的硬件抽象如图所示:
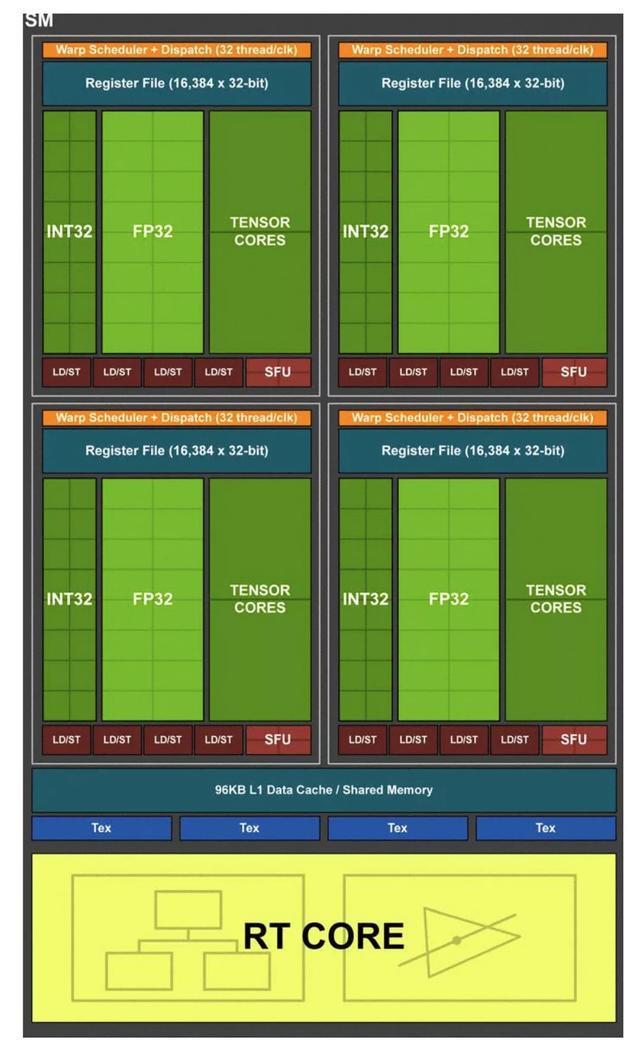
从官方关于图灵架构的介绍可知,最大的改进有三个:
(1) 增加了区别于浮点运算的整型运算通路 (也就是其中的INT32运算通路);
(2) 增加了专门针对深度网络的 Turing TENSOR CORES 进行矩阵运算的加速;
(3) 增加了 RT CORE 进行光追特效的渲染;
其中我们能够使用到的特性就是前面两个。
RTX2060 也是图灵框架,从带有 RTX2060 的 Windows 的资源管理器中可以看到多个利用率指标,如下:
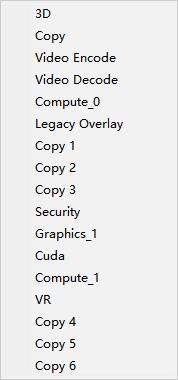
其中用于深度学习训练推理相关的主要是 Cuda 利用率,接下来主要解释 Cuda 利用率定义。
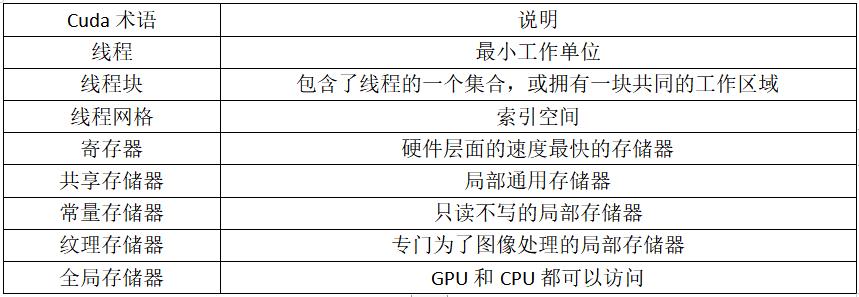
对存储器的访问速度进行排序,总共有三类存储器,大致遵循以下的排序方式:寄存器 > 局部存储器 > 全局存储器,速度差距是呈数量级的。
关于 Cuda 利用率的定义,这里使用 《并行编程方法与优化实践》 中的占用率进行解释。不同硬件拥有不同数目的 Cuda 核心数,而不同硬件的 Cuda 能力又不相同,不同的计算任务划分成块后,涉及到 Cuda 核心层面跟局部存储器大小和寄存器个数又会相关联。Cuda 利用率的定义是:在一个时刻,所有 Cuda 上的总线程数和最大允许数目的比例。 假设有一个计算任务,因为内核寄存器数目和局部存储器大小限制,该计算任务不可能根据最大允许数目来进行划分,必须考虑到每个 Cuda 的寄存器数目和划分成块后需要的局部数据的大小,而这就用 Cuda 利用率指标来表现出来。
以上分享了 GPU 利用率相关,希望我的分享能对你的学习有一点帮助。
【公众号传送】

扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于经验分享谈谈 GPU 利用率的主要内容,如果未能解决你的问题,请参考以下文章