第三章XML简介
Posted -相勖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第三章XML简介相关的知识,希望对你有一定的参考价值。
概念:
XML:提供数据交换、系统配置、内容管理等的功能,可跨平台、跨网络、跨程序的数据描述方式。
XSL:依靠XPath定位,提供显示模板,且专门为了显示XML文件信息的语言。
CSS(层叠样式表):在网页中进行样式显示的语言。(若需要XML文件显示是否独立运行需要CSS/XSL。通过浏览器XML一般显示是包括注释可能<也可能包括前导区我不确定>,但如果想要和html最终显示一样就需要编写CSS文件。)
前导区:规定出XML页面的一些属性。(所有的XML文件都是由前导区和数据区两部分组成,比如<name>/<tel>)
数据区:每个数据区必须有一个根元素,每个根元素都可以存多个子元素,但要求每个子元素必须完结,且区分大小写。(比如说班级学生信息excel表格中,姓名一列就是一个数据区,“姓名”就是根元素,“姓名”下所有的姓名是子元素,但是要求有这个姓名的学生就必须有他的电话宿舍号等这就是元素必须完结</...>。)
CDATA标记语言:XML语言中提供CDATA来标记文件数据,当XML解析器遇到CDATA标记时,不会解析标记以内的任何数据,会原封不动的传递该段数据。
DTD/Schema:在XML文件中,用DTD/Schema技术对经常出现的元素或属性进行严格的定义。(就像C++数学函数库,进行严格的定义就可以方便使用)。
JDOM:使用Java语言编写的用于读、写、操作XML的一套组件。JDOM=DOM修改文件的优点+SAX读取快速的优点。下载JDOM开发包地址:http://www.jdom.org/
DOM4J:也是一组XML操作的组件包,主要用于读写XML文件。书上说最出色,到底出不出色DOM4J开发包下载http://sourceforge.net/projects/dom4j/files/
3.1认识XML
数据保存
与HTML(主要网页静态显示),javascript(主要网页动态操作)不同,XML是以数据保存为主。
元素自定义
且在元素定义方面,HTML是固定的规定的元素,而在XML中我们可以自定义。比如,在填写个人表格时,HTML就属于已经有了规定格式和问题的一类,而XML属于一张白纸任由我们写,“姓名”可以写成“大名”/“小名”都行。
虽然我们可以自定义很多元素,但是在前导区有三个必须按照顺序才能使用的属性,version+encoding+standalone。具体:
 使用:
使用:![]()
显示
如果想要XML如HTML一样显示就必须编写CSS文件,并在XML中引入此文件。具体:
 1.对各个的显示方式进行定义
1.对各个的显示方式进行定义 ![]() 引入CSS
引入CSS
描述元素的属性,与HTML,Javascript一样需要""括起来,属性之间也是用空格隔起来。
在Java和C++中我们知道某些关键字使我们不能拿来命名的因为在系统中他们已经有了自己的含义,同样道理在XML中一些特定字符也是有特殊的含义。如单纯想使用&也得使用替代物&,方法有:
1.特殊字符必须通过这些实体参照进行转换显示,在HTML中也有体会,如&nasp表示空格。
2.通过CDATA标记。语法与定义如:

jsp(java服务器页面)的配置文件都是以XML文件格式定义的,必须掌握格式定义要求。
3.2XML解析
大致过程:应用程序不是直接访问XML文档,而是XML文档通过分析器分析并有分析器提供的接口对分析结果操作间接访问。

举个例子,有人给你发了一份PDF格式文档,你会从记事本/暴风等多种打开方式中挑一个能行的打开这个文件。那么这样,你就如同应用程序,选择的打开方式就是接口,你寻求可行的打开方式就是分析器,这个PDF文档就如同XML文档。
W3C(非盈利组织)定义两种解析方式,DOM/SAX解析方式。差异:
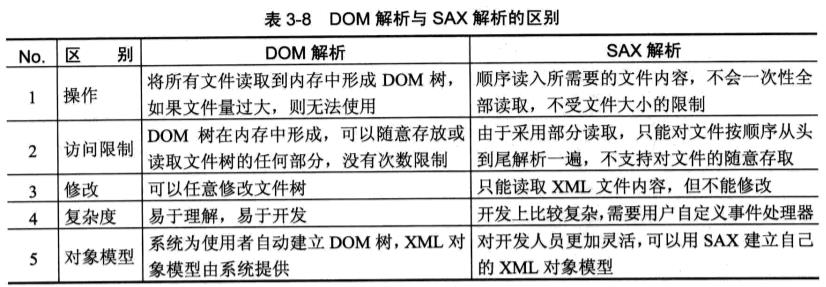
两者相比,在操作方面,DOM如同数组可以实现随机访问,SAX如同链表只能顺序访问。
3.2.1DOM解析方式
在解析时,DOM将所有XML文件变成DOM树(对象模型集合),如:
 处理为
处理为 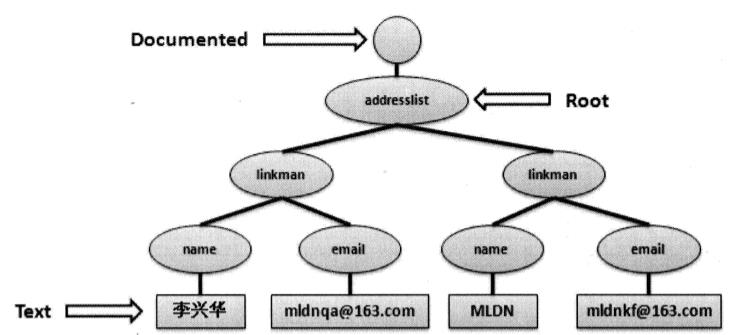
DOM解析中有很多接口,不同接口也有不同方法,用Java DOC文档查阅DOM解析中的操作。
解析步骤:

举例说明:

来理解一下,比如我要走去买桃子且知道xxx水果店有卖桃子的。DocumentBuilderFactory就是我能走到xxx水果店,DocumentBuilder就是我买得起,Document就是开始找桃子放在哪儿了,NodeList就是开始挑选桃子,读取就买到了的桃子。
这样看来,其实DocumentBuilderFactory,与DocumentBuilder是获取文件内容的铺路石,Document是获取指定路径的文件,NodeList是查找需要节点内容,读取就是将查找到的东西显示出来。
需要指出的是,每个节点中的内容都是一个节点,所以查找节点时也有:

除读取之外,DOM还可以进行XML文件输出,wow需要我们做什么呢?需要我们使用接口(如Element接口),设置节点设置节点内容,并手动设置节点之间的关系,并在创建Document对象时使用newDocument()创建Doc树(没看懂)。
举例:


和读取前两步步骤都一样,第三步时创建Document对象时使用newDocument()创建Doc树,之后设置节点(这里是我们说的Element)->设置节点内容->设置节点关系(因为是树,所以就是父与子的关系)->然后就是 输出文档到文件了。输出过程:

3.2.2SAX解析方式
![]()
如:


如:

这样看来SAX解析方法比DOM方法简单,但各有优点缺点。DOM适用于部分内容进行修改和随机存取的操作,但不适用于对大型文件操作。而SAX适用于对文件部分读取,核对大型文件的读取。
3.2.3JDOM好帮手
JDOM=DOM修改文件的优点+SAX读取快速的优点。
通过JDOM生成文件:

解释一番:
Document是我们整个XML文档,所以在建立Document对象时将根节点的Element对象保存在Document中。然后需要我们节点,设置节点设置节点内容,设置节点之间的父子关系。XMLOutputer类是进行用于输出,而输出内容中有中文,所以使用setFormat()将中文编码设置成GBK。
举个例子:我们要准备由礼物盒大小依次准备礼物,礼物盒是我们的节点,礼物盒里的礼物是节点内容,礼物盒的大小关系就是父子关系,最大的就是根节点,所有的礼物盒和礼物就是Document。
能生成文件当然也能读写文件:

哦?

看到这里,JDOM是集合了DOM修改文件的优点(生成文件也算是修改)+SAX读取快速的优点(读取文件)。
另外,JDOM中,所有节点都是以集合的形式返回的,集合的每一个对象都是Element实例,通过Element实例获得全部XML文件中的元素内容和属性内容。
3.2.4DOM4J最出彩
3.3使用Javascript操作DOM
DOM能做什么呢?能读取文档也能生成文档。记得上一次的课后作业要求在输入编号的时候只能是数字,上午搜方法的时候发现document.getElementById("id名称")读取文本框中的内容的方法,为什么会这样呢?
原来,HTML文档其实也是可以变成一棵DOM树:
 还记得书上说过,每个节点中的内容也是节点。所以读取相当于也是对HTML文件的从根节点层层选择。
还记得书上说过,每个节点中的内容也是节点。所以读取相当于也是对HTML文件的从根节点层层选择。
再比如,在HTML文档中,使用Javascript使用DOM解析:
 所以之后调用此函数时,就会生成www.MLDNJAVA.cn这句话。
所以之后调用此函数时,就会生成www.MLDNJAVA.cn这句话。
另外,DOM解析器也能动态进行表格操作,动态生成表格内容,如下拉列表框...crazy!方法参照Java Doc中DOM解析部分。
总结:

惊叹它的强大,也对它的困难感到深深无语和畏惧。
以上是关于第三章XML简介的主要内容,如果未能解决你的问题,请参考以下文章