高级文件处理(XML)
Posted 未定_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高级文件处理(XML)相关的知识,希望对你有一定的参考价值。
XML
第一章 XML基本概念
一、XML简介
1.XML是可扩展标记语言:意义+数据
标签可自行定义,具有自我描述性。
纯文本表示,跨平台/平台/语言。
2.XML结构:
声明信息,用于描述xml的版本和编码方式。
<?xml version="1.0" encoding="UTF-8"?>
常规语法:
a.任何的起始标签都必须有一个结束标签。
b.简化写法,例如,<name> </name>可以写为<name/>
c.大小写敏感。
d.每个文件都要有一个根元素。
e.标签必须按合适的顺序进行嵌套,不可错位。
f.所有的特性都必须有值,且在值的周围加上引号。
g.需要转义字符,如“<”需要用<;代替。
h.注释:<!--注释内容-->
3.XML解析方法
树结构: DOM,文档对象模型,擅长(小规模)读/写。
流结构: SAX,流机制解释器(推模式),擅长读;Stax,流机制解释器(拉模式),擅长读。
xml简介
二、XML规范化
1.DTD
1.DTD简介
- 文档定义类型
- 用于约束xml的文档格式,保证xml有效
- DTD可以分为两种,内部DTD,外部DT
DTD简介
2.使用DTD
内部DTD:
定义:
<!DOCTYPE 根元素 [元素声明]>
元素声明:–>戳
<!ELEMENT 元素名(子元素[,子元素...])>
例如:
<!ELEMENT scores (student*)>//可以有任意个student
<!ELEMENT student (name, course, score)>
可表示成:
<scores>
<student>
<name> </name>
<course> </course>
<score> </score>
</student>
…
</scores>
若元素标签中不允许再嵌套元素标签,只能写文本,可加 #PCDATA 限制,例如:
<!ELEMENT name (#PCDATA)>
数量词:
+:出现1次或多次,至少1次
?:出现0次或1次
*:出现任意次
属性声明:–>戳
<!ATTLIST 元素名称 属性名称 属性类型 默认值>
例如:
<!ATTLIST student id CDATA #REQUIRED>
//CDATA是属性类型,表示值为字符数据
//#REQUIRED是默认参数类型,表示属性值必须有
//#IMPLIED是默认参数类型,表示属性值不是必须有
可以表示为:
<student id="1">
带DTD的完整xml代码
<?xml version="1.0" encoding="UTF-8"?>
<!--声明内部DTD-->
<!DOCTYPE scores[
<!ELEMENT scores (student+)>
<!ELEMENT student (name, course, score)>
<!ATTLIST student id CDATA #REQUIRED>
<!ELEMENT name (#PCDATA)>
<!ELEMENT course (#PCDATA)>
<!ELEMENT score (#PCDATA)>
]>
<scores>
<student id="1">
<name>张三</name>
<course>java</course>
<score>89</score>
</student>
<student id="2">
<name>李四</name>
<course>c++</course>
<score>85</score>
</student>
</scores>
外部DTD
创建一个独立的DTD文件
<?xml version="1.0" encoding="UTF-8"?>
<!--声明内部DTD-->
<!ELEMENT scores (student+)>
<!ELEMENT student (name, course, score)>
<!ATTLIST student id CDATA #REQUIRED>
<!ELEMENT name (#PCDATA)>
<!ELEMENT course (#PCDATA)>
<!ELEMENT score (#PCDATA)>
<?xml version="1.0" encoding="UTF-8"?>
<!--外部引入DTD-->
<!DOCTYPE scores SYSTEM "scores.dtd">
<scores>
<student id="1">
<name>张三</name>
<course>java</course>
<score>89</score>
</student>
<student id="2">
<name>李四</name>
<course>c++</course>
<score>85</score>
</student>
</scores>
第二章 XML的解析方式
XML常用的解析方式:
- DOM解析:
是官方提供的解析方式,基于XML树解析的。
比较耗资源,适用于多次访问XML。 - SAX解析:
是民间的解析方式,基于事件的解析。
消耗资源小,适用于数据量较大的XML。 - JDOM解析:
第三方提供,开源免费的解析方式,比DOM解析快。
JDOM仅使用具体类而不使用接口。 - DOM4J解析:
第三方提供,开源免费,是JDOM的升级版。
使用接口而不是实现类。
一、DOM
1.DOM 是 W3C 处理 XML 的标准 API
- 直观易用。
- 其处理方式是将 XML 整个 作为类似 树结构 的方式读入内存中以便操作及解析,方便修改。
- 基于XML树结构,比较耗费资源,适用于 多次 访问 XML。
- 解析 大数据量 的 XML 文件,会遇到内存泄露及程序崩溃的风险(需要用SAX解析方式)。
2.DOM类
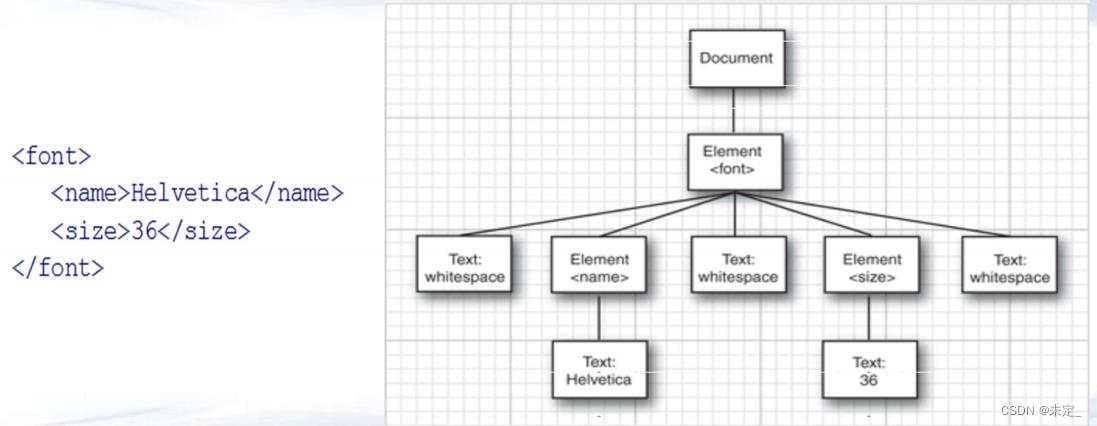
• DocumentBuilder 解析类,parse方法
• Node 节点主接口,getChildNodes返回一个NodeList
• NodeList 节点列表,每个元素是一个Node
• Document 文档根节点
• Element 标签节点元素 (每一个标签都是标签节点)
• Text节点 (包含在XML元素内的,都算Text节点)
• Attr节点(每个属性节点)
• 查看相关例子
3.实例
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user id="0">
<name>Mary</name>
<age>23</age>
<sex>Female</sex>
</user>
<user id="1">
<name>Mike</name>
<age>24</age>
<sex>Male</sex>
</user>
<user id="2">
<name>Alice</name>
<age>23</age>
<sex>Female</sex>
</user>
<user id="3">
<name>Tom</name>
<age>24</age>
<sex>Male</sex>
</user>
</users>
package XML.DOM;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class DomReader
public static void main(String[] a) throws Exception
recursiveTraverse();
System.out.println("=======华丽的分割线=======");
traverseBySearch();
public static void recursiveTraverse() throws Exception
//采用Dom解析xml文件
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
DocumentBuilder db=dbf.newDocumentBuilder();
Document document=db.parse("users.xml");
//获取所有的一级子结点
NodeList usersList=document.getChildNodes();
System.out.println(usersList.getLength());//1
for(int i=0;i<usersList.getLength();i++)
Node users=(Node) usersList.item(i);//1 users
NodeList userList=users.getChildNodes();//获取二级子结点users的列表
System.out.println("=="+userList.getLength());//9
for(int j=0;j<userList.getLength();j++)
Node user=(Node) userList.item(j);
if(user.getNodeType()==Node.ELEMENT_NODE)
NodeList metaList=user.getChildNodes();
System.out.println("==="+metaList.getLength());//7
for(int k=0;k<metaList.getLength();k++)
Node meta=(Node) metaList.item(k);
if(meta.getNodeType()==Node.ELEMENT_NODE)
System.out.println(metaList.item(k).getNodeName()+":"+metaList.item(k).getTextContent());
System.out.println();
public static void traverseBySearch() throws Exception
//采用Dom解析xml文件
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
DocumentBuilder db=dbf.newDocumentBuilder();
Document document=db.parse("users.xml");
Element rootElement=document.getDocumentElement();
NodeList nodeList=rootElement.getElementsByTagName("name");
if(nodeList!=null)
for(int i=0;i<nodeList.getLength();i++)
Element element=(Element) nodeList.item(i);
System.out.println(element.getNodeName()+"="+element.getTextContent());
显示
1
==9
===7
name:Mary
age:23
sex:Female
===7
name:Mike
age:24
sex:Male
===7
name:Alice
age:23
sex:Female
===7
name:Tom
age:24
sex:Male
=======华丽的分割线=======
name=Mary
name=Mike
name=Alice
name=Tom
二、SAX
1.Simple API for XML
- 采用事件/流模型来解析XML文档,更快捷、更轻量。
- 有选择的解析和访问,不像DOM加载整个文档,内存要求较低。
- SAX对XML文档的解析为一次性读取,不创建/不存储文档对象,很难同时访问文档中的多处数据。
- 推模型。当它每发现一个节点就引发一个事件,而我们需要编写这些事件的处理程序。
2.实例
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<books>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</books>
</bookstore>
package XML.SAX;
import java.util.ArrayList;
import java.util.List;
import org.xml.sax.Attributes;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.XMLReaderFactory;
public class SAXReader
public static void main(String[] args) throws Exception
XMLReader parser = XMLReaderFactory.createXMLReader();
BookHandler bookHandler = new BookHandler();
parser.setContentHandler(bookHandler);
parser.parse("xml/books.xml");
System.out.println(bookHandler.getNameList());
class BookHandler extends DefaultHandler
private List<String> nameList;
private boolean title = false;
public List<String> getNameList()
return nameList;
//xml文档加载时
public void startDocument()
System.out.println("Start parsing document...");
nameList = new ArrayList<String>();
//文档解析结束
public void endDocument()
System.out.println("End");
//访问某一个元素
public void startElement(String uri,String localName,String qName,Attributes atts)
if(qName.equals("title"))
title = true;
//结束访问元素
public void endElement(String namespaceURI,String localName,String qName)
if(title)
title = false;
//访问元素正文
public void characters(char[] ch,int start,int length)
if(title)
String bookTitle = new String(ch,start,length);
System.out.println("Book title:"+bookTitle);
nameList.add(bookTitle);
显示结果
Start parsing document...
Book title:Everyday Italian
Book title:Harry Potter
Book title:Learning XML
End
[Everyday Italian, Harry Potter, Learning XML]
三、STAX
1.Stream API for XML
- 流模型中的拉模型
- 在遍历文档时,会把感兴趣的部分从读取器中拉出,不需要引发事件,允许我们选择性地处理节点。这大大提高了灵活性,以及整体效率。
- 两套处理API
基于指针的API,XMLStreamReader
基于迭代器的API,XMLEventReader
2.实例
package XML.STAX;
import java.io.FileReader;
import java.util.Iterator;
import javax.xml.stream.XMLEventReader;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLStreamConstants;
import javax.xml.stream.XMLStreamReader;
import javax.xml.stream.events.Attribute;
以上是关于高级文件处理(XML)的主要内容,如果未能解决你的问题,请参考以下文章