第三章——供机器读取的数据(XML)
Posted 韬小虾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第三章——供机器读取的数据(XML)相关的知识,希望对你有一定的参考价值。
本书使用的文件、代码:https://github.com/huangtao36/data_wrangling
机器可读(machine readable)文件格式:
1、逗号分隔值(Comma-Separated Values, CSV)
2、javascript对象符号(JavaScript Object Notation, JSON)
3、可扩展标记语言(eXtensible Markup Language, XML)
第三章使用的数据文件:
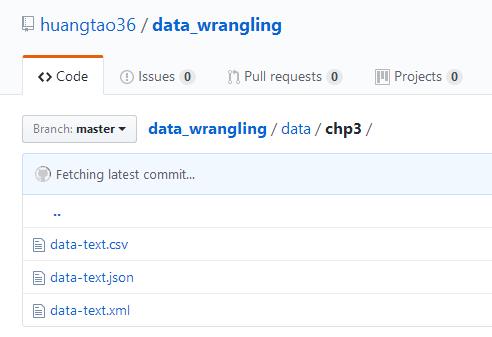
XML数据
XML是一种标记语言,它具有包含格式化数据的文档结构。本质是也只是格式特殊的数据文件。
要处理的数据样本(XML基本数据格式):
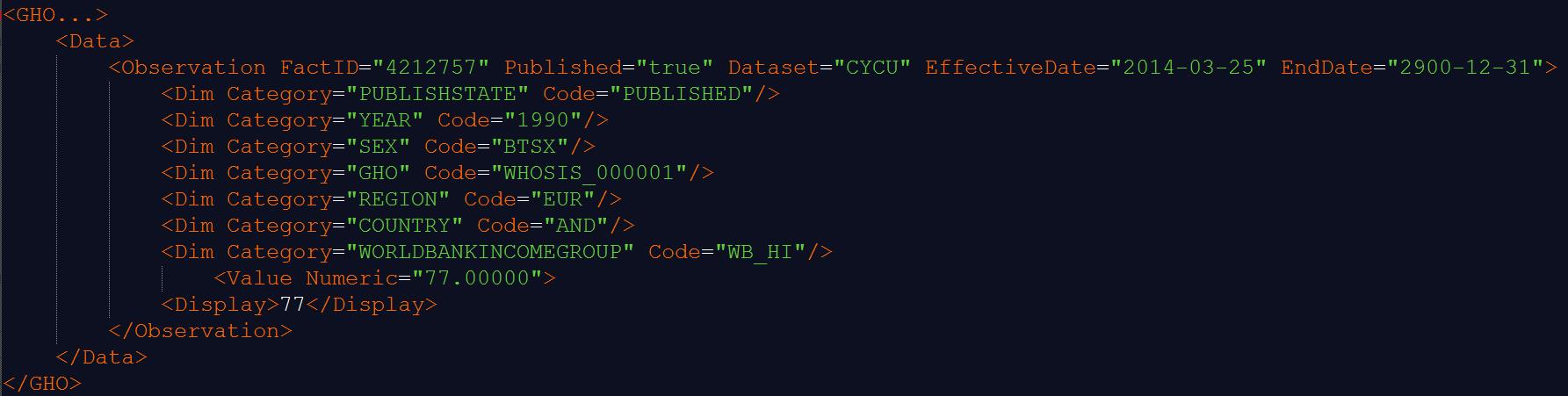
XML中有两个位置可以保存数据:
1、两个标签之间:<Display>71</Display>
2、标签的属性:<Dim Category="SEX" Code="BTSX"/>——其中Category的属性值是“SEX”,Code的属性值是"BTSX"。
XML的属性可以保存特定标签的额外信息,这些标签又嵌套在另一个标签中。
实现代码(基于Python3)
from xml.etree import ElementTree as ET
tree = ET.parse(\'data-text.xml\')
root = tree.getroot() #获取树的根元素
data = root.find(\'Data\')
all_data = []
for observation in data:
record = {}
for item in observation:
lookup_key_List = list(item.attrib.keys())
lookup_key = lookup_key_List[0]
if lookup_key == \'Numeric\':
rec_key = \'NUMERIC\'
rec_value = item.attrib[\'Numeric\']
else:
rec_key = item.attrib[lookup_key]
rec_value = item.attrib[\'Code\']
record[rec_key] = rec_value
all_data.append(record)
print (all_data)
输出(部分):
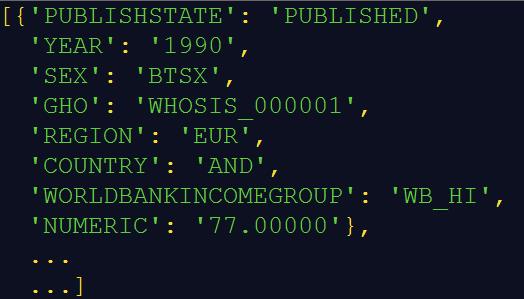
(输出的是单行数据,为了直观,这里进行了处理。)
代码解释
from xml.etree import ElementTree as ET
本例中使用的是ElementTree、还可以使用lxml、minidom这两种库来解析XML文件,在此不做说明
获取Observation元素中的内容
由上面的样本可知,我们使用的数据是包含在一个<Data>...</Data>中的,这里使用根元素的find方法可以利用标签名来搜索子元素。
from xml.etree import ElementTree as ET
tree = ET.parse(\'data-text.xml\')
root = tree.getroot() #获取树的根元素
data = root.find(\'Data\')
for observation in data:
for item in observation:
print(item.attrib)
输出(部分):

输出的是<Observation> ........</Observation>标签里面的内容
我们的数据文件只有一个Data标签,如果有多个Data标签,可以将find函数改为findall函数来遍历。
attrib:可以返回每一个节点的属性
提取重要内容
获得键的代码:
from xml.etree import ElementTree as ET
tree = ET.parse(\'data-text.xml\')
root = tree.getroot() #获取树的根元素
data = root.find(\'Data\')
all_data = []
for observation in data:
record = {}
for item in observation:
lookup_key_List = list(item.attrib.keys())
lookup_key = lookup_key_List[0]
rec_key = item.attrib[lookup_key]
print(rec_key)
输出:
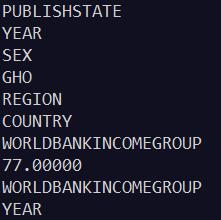
上面代码得到了数据的键,但还没有取得相应的值。
lookup_key_List = list(item.attrib.keys()) lookup_key = lookup_key_List[0]
这两句得到了每个属性键的名字,既是Category、code、Numeric这些,还没有得到键的值,加入rec_key = item.attrib[lookup_key]就获得了键的值。
上面两句是Python3的写法,Python2中可以直接合并成一句:lookup_key = item.attrib.keys()[0]
获得值的代码:
from xml.etree import ElementTree as ET
tree = ET.parse(\'data-text.xml\')
root = tree.getroot() #获取树的根元素
data = root.find(\'Data\')
all_data = []
for observation in data:
record = {}
for item in observation:
lookup_key_List = list(item.attrib.keys())
lookup_key = lookup_key_List[0]
if lookup_key == \'Numeric\':
rec_key = \'NUMERIC\'
rec_value = item.attrib[\'Numeric\']
else:
rec_key = item.attrib[lookup_key]
rec_value = item.attrib[\'Code\']
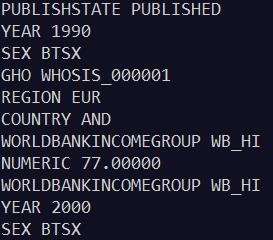
print(rec_key,rec_value)
输出:
以上是关于第三章——供机器读取的数据(XML)的主要内容,如果未能解决你的问题,请参考以下文章