散列表
Posted 莫水千流
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了散列表相关的知识,希望对你有一定的参考价值。
散列表(hash table)
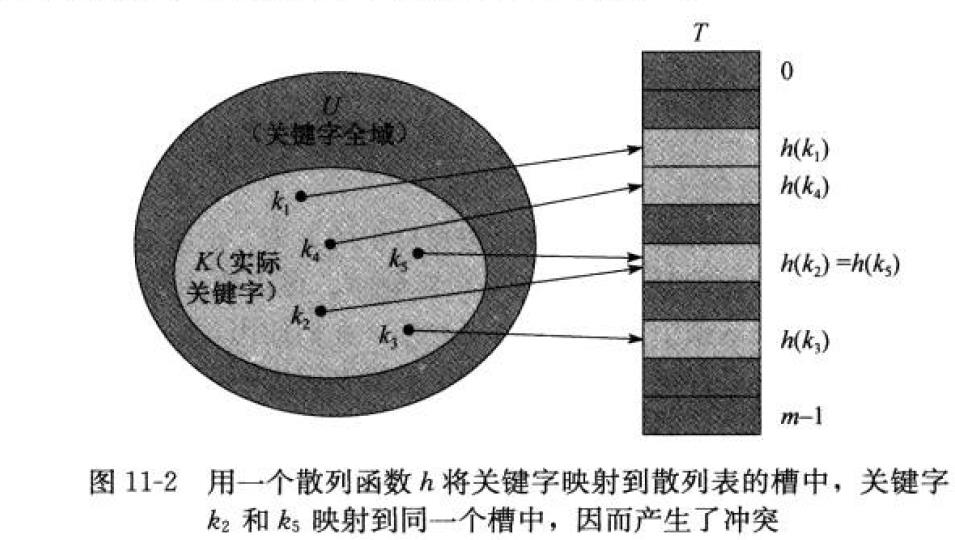
在直接寻址的方式下,具有关键字k的元素被放到槽k中。在散列方式下,该元素放在槽h(k)中;
即利用散列函数hash funciton h , 由关键字k计算出槽的位置。这里,函数h将关键字的全域U映射到
散列表hash table T[0....m-1]的槽位上
h:U -> {0,1,....,m-1}
这里存在一个问题,两个关键字可能映射到同一槽中。我们称这种情形为冲突。
散列的含义是随机混杂和拼凑。
解决冲突的办法,链接法,开发寻址法
通过链接伐解决冲突
把散列到同一槽中的所有元素都放在一个链表中。
CHAINED-HASH-INSERT(T,x)
insert x at the head of list T
CHAINED-HASH-SEAARCH(T,x)
CHAINED-HASH-DELEETE(T,x)
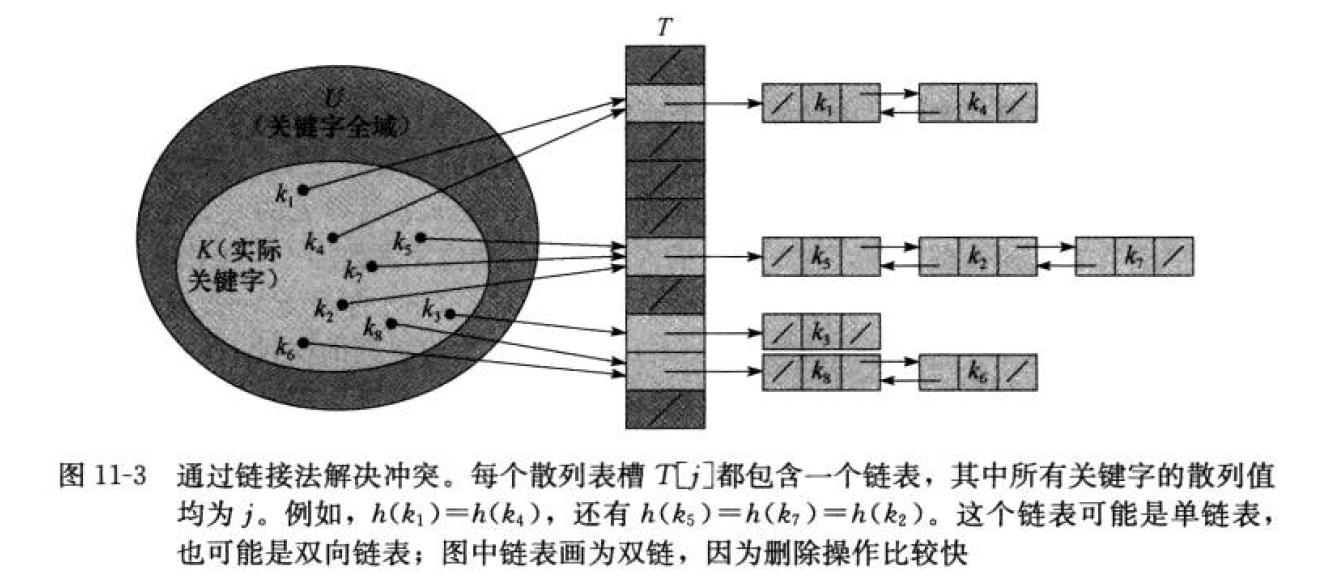
期望查找时间@(1 + a) a = n/m n个元素,m个槽位的散列表T
散列函数 启发式,随机技术
1)将关键字转化为自然数
多数散列函数都假定关键字的全域为自然是N={0,1,2....}
字符串转化为基数符号表的整数。
例如 P=112, t=116, 以128为基数,pt=(112*128) + 116 = 14452
2) 除法散列法
取k除以m的余数,将关键字k映射到m个槽中的某一个上,即为散列函数
h(k) = k mod m
除法散列法时,避免选择m的某些值, m不应该是2的幂。 如果m=2^p h(k) 就是 k的p个最低位数字
一个不太接近2的整数幂的素数,常常是一个较好的选择。
质数(prime number)又称素数,有无限个。质数定义为在大于1的自然数中,除了1和它本身以外不再有其他因数的数称为质数。
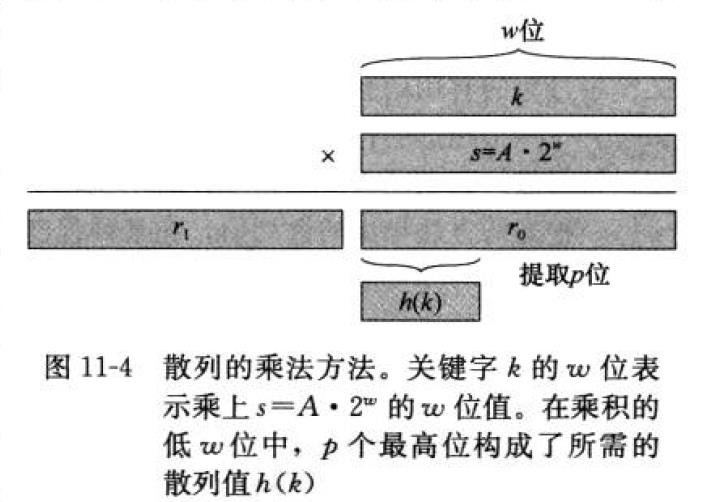
3)乘法散列法
构造散列函数的乘法散列法包含2个步骤,
1,用关键字k乘以常数A(0<A<1),并提取kA的小数部分
2,用m乘以这个值,再向下取整
h(k) = L m*(kA mod 1) j kA mod 1 即kA的小数部分,即kA - LkAj
乘法散列法对m的选择不是特别关键。一般选择它为2的某个幂
假设计算机的字长为w位,而k正好可以用一个单字表示。限制A为形如s/2^w的一个分数,其中s是一个取自0<s<2^w 的整数
先用w位整数s=A*2^w 乘以k, 其结果是一个2w的值 r1*2^w + r0, 这里r1为乘积的高位字,r0为乘积的低位字。
所求的p位散列值中,包含了r0的p个最高有效位。
最佳散列值
A = (sqrt(5) - 1)/2 = 0.6180339887...
作为一个例子,假设k=123456, p=14, m=2^14=16384, 且w=32
取A为形如s/2^32的分数,它与(sqrt(5)-1)最接近,于是A=2654435769/2^32. 那么,k*s = 327706022297664
= (76300*2^32) + 17612864, 从而有r1=76300 和 r0=17612864. r0的14个最高有效位产生了散列值h(k) = 67
全域散列法
设H为一组有限的散列函数,它将给定的关键字全域U映射到{0,1,...,m-1}中。这样的一组函数族称为全域的,如果
对每一对不同的关键字k,l 属于U,满足h(k)=h(l)的散列函数h 属于H的个数至多为H/m, 换句话说,如果从H中随机地选择一个
散列函数,当关键字k!=l时,两者发生冲突的概率不大于1/m, 这也正好是从集合{0,1,..m-1}中独立地随机选择h(k)和h(l)时
发生的概率。
定理,如果h选自一组全域散列函数,将n个关键字散列到一个大小为m的表T中,并用链接法解决冲突。如果关键字k不在表中,
则k被散至链表的期望长度至多为a=n/m, 如果关键字k在表中,则包含关键字k的链表期望长度至多为1+a
设计一个全域散列函数类
选择一个足够大的素数p, 使得每一个可能的关键字k都落在0到p-1的范围内(包括0和P-1)
设Zp表示集合{0,1,....,p-1} Zp* 表示集合{1,2,....p-1} 由于p是一个素数,故可以利用第31章给出的方法来求解模p
的方程。因为我们家的关键字的全域大小大于散列表中的槽数,故有p>m
现在,对于任何a属于Zp* 和任何b属于Zp,定义散列函数hab, 利用一次线性变换,在进行模p 和 模m的规约,有
hab(k) = ((ak+b)modp)modm
例如如果有 p=17, m=6, 则 h3,4(8) = 5
这样得到到散列函数构成的函数簇为 H ={hab :aE Zp*, b E Zp}
开发寻址法
在开放寻址法中,所有的元素都存放在散列表里。也就是说,每个表项或包含动态集合中的一个元素,或包含NIL
装载因子a绝对不会超过1
h:Ux {0,1,...m-1} ->{0,1,...,m-1}
对于每一个关键字k, 使用开放寻址的探索序列 probe sequence
< h(k,0),h(k,1),...h(k,m-1)>
HASH-INSERT(T,k)
i=0
repeat
j = h(k,i)
if (T[j] == NIL)
T[j] = k
return j
else i = i+1
until i==m
error "hash table overflow"
HASH-SEARCH(T,k)
i = 0
repeat
j = h(k,j)
if T[j] == k
return j
i = i + 1
until T[j]==NIL or i == m
return NIL
均匀散列,每个关键字的探索序列尽可能的为<0,1,...m-1> 的 m!种排列的任一种。均匀散列难以实现
三种近似方法,用来计算开放寻址中的探索序列,线性探索,二次探索,双重探索。
线性探索:
给定一个普通的散列函数h\': U ->{0,1,...m-1},称之为辅助散列函数(auxiliary hash function),
线性探查(linear probing)方法采用的散列函数为
h(k,i) = (h\'(k)+ i)mod m, i=0,1,...m-1
给定一个关键字k, 搜寻探查槽T[h\'(k)],即由辅助散列函数所给出的槽位。 再探查槽T[h\'(k) +1],依次类推,直至槽
T[m-1]. 然后又绕到槽T[0],T[1],...直到最后探查到槽T[h\'(k)-1].在线性探查方法中,初始探查位置决定了整个序列,故
有m中不同探查序列。
存在的问题,一次群集(primary clustering) ,随着连续被占槽的不断增加,评价查找时间随之不断增加。
二次探查
h(k,i)=(h\'(k) + c1i + c2i^2) mod m h\'是辅助散列函数,c1和c2是辅助常数,i=0,1,...m-1
容易出现二次群集问题。
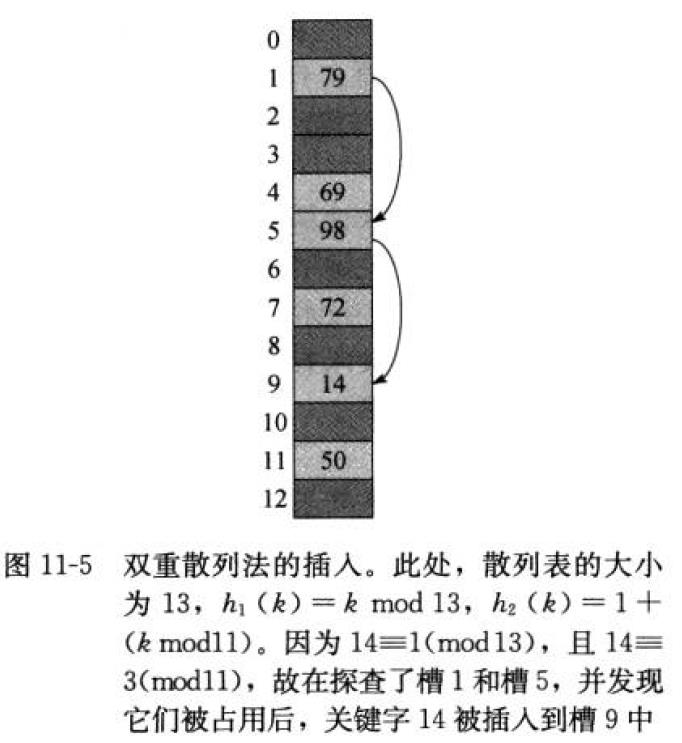
双重散列
h(k,i)=(h1(k)+i*h2(k))modm h1,h2均为辅助散列函数。
初始探查位置是T[h1(k)],后续的探查位置是前一个位置加上偏移量h2(k)模m.
为了能查找整个散列表,h2(k)必须要与表的大小m互素
取m为2的幂,并设计一个总产奇数的h2.另一种方法是取m为素数,并设计一个总是返回较m小的正整数的函数h2
例如取m为素数,
h1(k) = k mod m, h2(k)= 1+ (kmodm\')
其中m\'略小于m,比如m-1, 如果K=123456, m=701, m\'=700 h1(k) = 80, h2(k) = 257
我们知道第一个探索位置是80, 然后查每第257个槽模m,直到找到关键字,或者遍历了所有的槽。
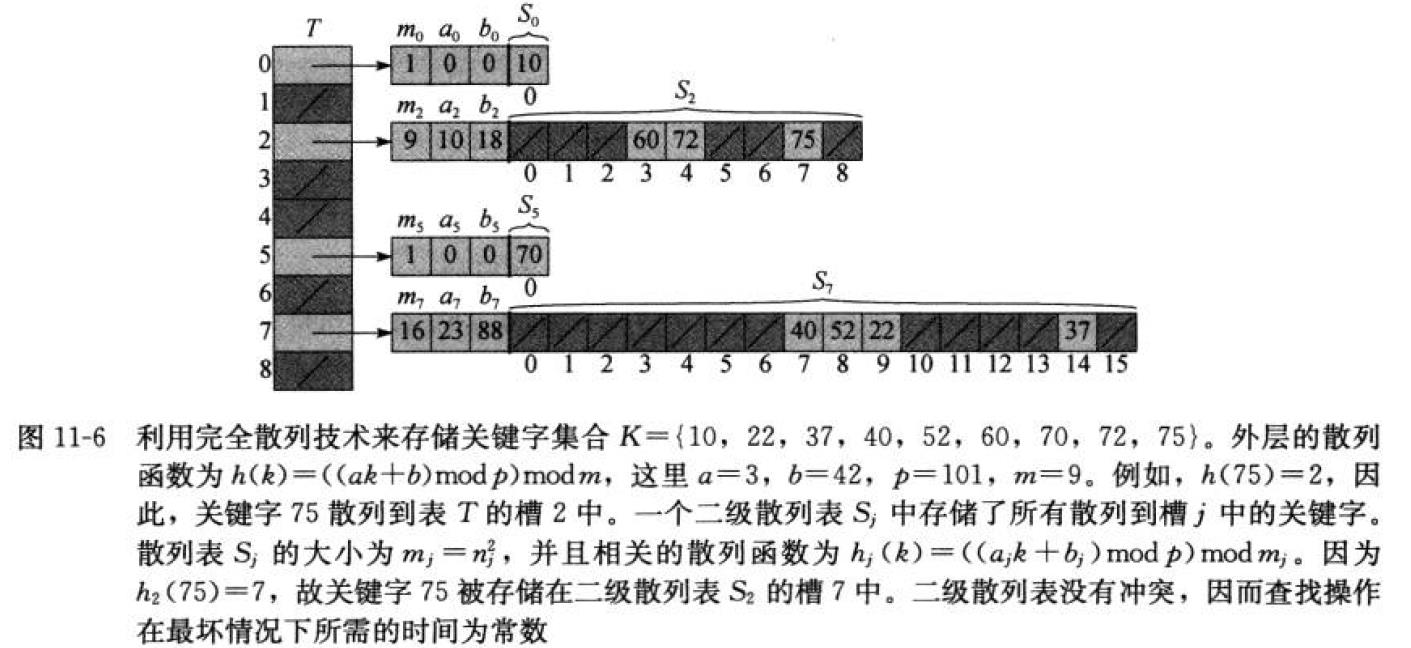
完全散列
使用散列技术通常是个好的选择,不仅它有优异的平均性能,而且当关键字集合是静态的时,散列技术也能提供出色的最坏
情况的性能。所谓静态,就是指一旦各关键字存入表中,关键字集合就不再变化了。一些应用存在着天然的静态关键字集合
如程序设计中的保留字,或者CD-ROM上的文件集合。完全散列 perfect-hashing
采用两级散列的方法来设计完全散列方案。
第一级与带链接的散列表基本上是一样的:利用从某一全域散列函数簇中仔细选出一个散列函数h, 将n个关键字散列到m个槽
中。然而,我们采用一个较小的二次散列表(secondary hash table)Sj,及相关的散列函数hj,而不是将散列到槽j的所有关键字
建立一个链表。利用精心选择的散列函数hj,可以确保在二级散列上不出现冲突。
为了确保二级上不冲突,需要让散列表Sj的大小mj,为散列到槽j中的关键字数nj的平方。
以上是关于散列表的主要内容,如果未能解决你的问题,请参考以下文章