散列表
Posted AlanTu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了散列表相关的知识,希望对你有一定的参考价值。
摘要:
本章介绍了散列表(hash table)的概念、散列函数的设计及散列冲突的处理。散列表类似与字典的目录,查找的元素都有一个key与之对应,在实践当中,散列技术的效率是很高的,合理的设计散函数和冲突处理方法,可以使得在散列表中查找一个元素的期望时间为O(1)。散列表是普通数组概念的推广,在散列表中,不是直接把关键字用作数组下标,而是根据关键字通过散列函数计算出来的。书中介绍散列表非常注重推理和证明,看的时候迷迷糊糊的,再次证明了数学真的很重要。在STL中map容器的功能就是散列表的功能,但是map采用的是红黑树实现的,后面接着学习,关于map的操作可以参考:http://www.cplusplus.com/reference/map/。
1、直接寻址表
当关键字的的全域(范围)U比较小的时,直接寻址是简单有效的技术,一般可以采用数组实现直接寻址表,数组下标对应的就是关键字的值,即具有关键字k的元素被放在直接寻址表的槽k中。直接寻址表的字典操作实现比较简单,直接操作数组即可以,只需O(1)的时间。
2、散列表
直接寻址表的不足之处在于当关键字的范围U很大时,在计算机内存容量的限制下,构造一个存储|U|大小的表不太实际。当存储在字典中的关键字集合K比所有可能的关键字域U要小的多时,散列表需要的存储空间要比直接寻址表少的很多。散列表通过散列函数h计算出关键字k在槽的位置。散列函数h将关键字域U映射到散列表T[0....m-1]的槽位上。即h:U->{0,1...,m-1}。采用散列函数的目的在于缩小需要处理的小标范围,从而降低了空间的开销。
散列表存在的问题:两个关键字可能映射到同一个槽上,即碰撞(collision)。需要找到有效的办法来解决碰撞。
3、散列函数
好的散列函数的特点是每个关键字都等可能的散列到m个槽位上的任何一个中去,并与其他的关键字已被散列到哪一个槽位无关。多数散列函数都是假定关键字域为自然数N={0,1,2,....},如果给的关键字不是自然数,则必须有一种方法将它们解释为自然数。例如对关键字为字符串时,可以通过将字符串中每个字符的ASCII码相加,转换为自然数。书中介绍了三种设计方案:除法散列法、乘法散法和全域散列法。
(1)除法散列法
通过取k除以m的余数,将关键字k映射到m个槽的某一个中去。散列函数为:h(k)=k mod m 。m不应是2的幂,通常m的值是与2的整数幂不太接近的质数。
(2)乘法散列法
乘法散列法构造散列函数需要两个步骤。第一步,用关键字k乘上常数A(0<A<1),并抽取kA的小数部分。然后,用m乘以这个值的小数部分,再取结果的底。散列函数如下:h(k) = m(kA mod 1)。其中“kA mod 1”是取kA的小数部分。
(3)全域散列
给定一组散列函数H,每次进行散列时候从H中随机的选择一个散列函数h,使得h独立于要存储的关键字。全域散列函数类的平均性能是比较好的。
4、碰撞处理
通常有两类方法处理碰撞:开放寻址(Open Addressing)法和链接(Chaining)法。前者是将所有结点均存放在散列表T[0..m-1]中;后者通常是把散列到同一槽中的所有元素放在一个链表中,而将此链表的头指针放在散列表T[0..m-1]中。
(1)开放寻址法
所有的元素都在散列表中,每一个表项或包含动态集合的一个元素,或包含NIL。这种方法中散列表可能被填满,以致于不能插入任何新的元素。在开放寻址法中,当要插入一个元素时,可以连续地检查或探测散列表的各项,直到有一个空槽来放置待插入的关键字为止。有三种技术用于开放寻址法:线性探测、二次探测以及双重探测。
<1>线性探测
给定一个普通的散列函数h\':U —>{0,1,.....,m-1},线性探测方法采用的散列函数为:h(k,i) = (h\'(k)+i)mod m,i=0,1,....,m-1
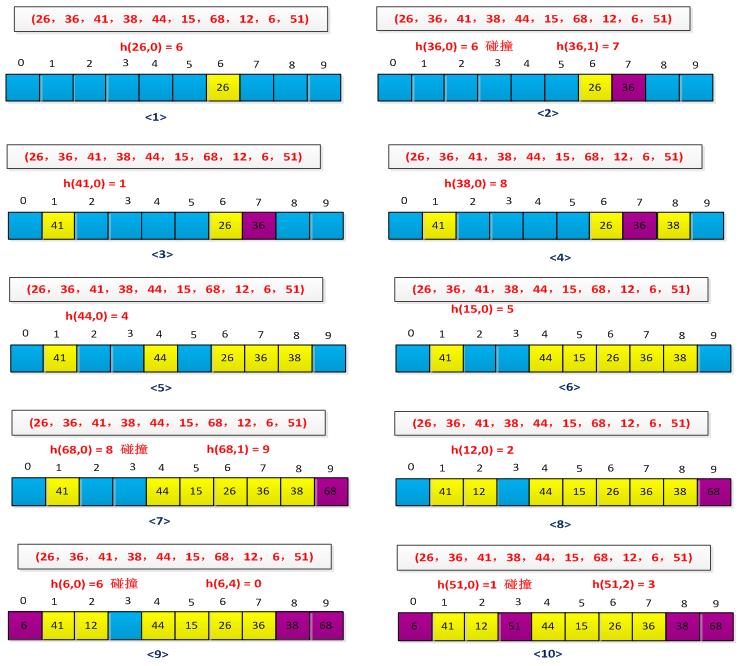
探测时从i=0开始,首先探查T[h\'(k)],然后依次探测T[h\'(k)+1],…,直到T[h\'(k)+m-1],此后又循环到T[0],T[1],…,直到探测到T[h\'(k)-1]为止。探测过程终止于三种情况:
(1)若当前探测的单元为空,则表示查找失败(若是插入则将key写入其中);
(2)若当前探测的单元中含有key,则查找成功,但对于插入意味着失败;
(3)若探测到T[h\'(k)-1]时仍未发现空单元也未找到key,则无论是查找还是插入均意味着失败(此时表满)。
线性探测方法较容易实现,但是存在一次群集问题,即连续被占用的槽的序列变的越来越长。采用例子进行说明线性探测过程,已知一组关键字为(26,36,41,38,44,15,68,12,6,51),用除余法构造散列函数,初始情况如下图所示:
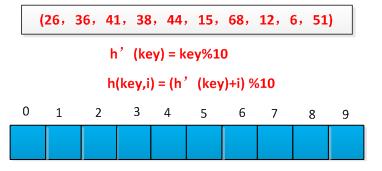
散列过程如下图所示:
<2>二次探测
二次探测法的探查序列是:h(k,i) =(h\'(k)+i*i)%m ,0≤i≤m-1 。初次的探测位置为T[h\'(k)],后序的探测位置在次基础上加一个偏移量,该偏移量以二次的方式依赖于i。该方法的缺陷是不易探查到整个散列空间。
<3>双重散列
该方法是开放寻址的最好方法之一,因为其产生的排列具有随机选择的排列的许多特性。采用的散列函数为:h(k,i)=(h1(k)+ih2(k)) mod m。其中h1和h2为辅助散列函数。初始探测位置为T[h1(k)],后续的探测位置在此基础上加上偏移量h2(k)模m。
(2)链接法
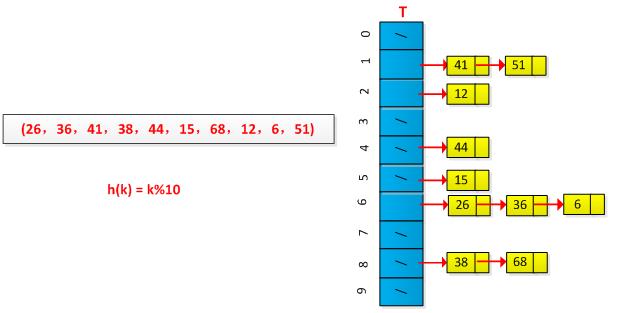
将所有关键字为同义词的结点链接在同一个链表中。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于1,但一般均取α≤1。
举例说明链接法的执行过程,设有一组关键字为(26,36,41,38,44,15,68,12,6,51),用除余法构造散列函数,初始情况如下图所示: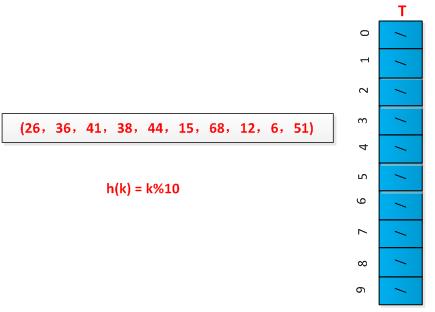
最终结果如下图所示:
5、字符串散列
通常都是将元素的key转换为数字进行散列,如果key本身就是整数,那么散列函数可以采用keymod tablesize(要保证tablesize是质数)。而在实际工作中经常用字符串作为关键字,例如身姓名、职位等等。这个时候需要设计一个好的散列函数进程处理关键字为字符串的元素。参考《数据结构与算法分析》第5章,有以下几种处理方法:
方法1:将字符串的所有的字符的ASCII码值进行相加,将所得和作为元素的关键字。设计的散列函数如下所示:

int hash(const string& key,int tablesize)
{
int hashVal = 0;
for(int i=0;i<key.length();i++)
hashVal += key[i];
return hashVal % tableSize;
}
此方法的缺点是不能有效的分布元素,例如假设关键字是有8个字母构成的字符串,散列表的长度为10007。字母最大的ASCII码为127,按照方法1可得到关键字对应的最大数值为127×8=1016,也就是说通过散列函数映射时只能映射到散列表的槽0-1016之间,这样导致大部分槽没有用到,分布不均匀,从而效率低下。
方法2:假设关键字至少有三个字母构成,散列函数只是取前三个字母进行散列。设计的散列函数如下所示:
int hash(const string& key,int tablesize)
{
//27 represents the number of letters plus the blank
return (key[0]+27*key[1]+729*key[2])%tablesize;
}
该方法只是取字符串的前三个字符的ASCII码进行散列,最大的得到的数值是2851,如果散列的长度为10007,那么只有28%的空间被用到,大部分空间没有用到。因此如果散列表太大,就不太适用。
方法3:借助Horner\'s 规则,构造一个质数(通常是37)的多项式,(非常的巧妙,不知道为何是37)。计算公式为:key[keysize-i-1]37^i,0<=i<keysize求和。设计的散列函数如下所示:
int hash(const string & key,int tablesize)
{
int hashVal = 0;
for(int i =0;i<key.length();i++)
hashVal = 37*hashVal + key[i];
hashVal %= tableSize;
if(hashVal<0) //计算的hashVal溢出
hashVal += tableSize;
return hashVal;
}
该方法存在的问题是如果字符串关键字比较长,散列函数的计算过程就变长,有可能导致计算的hashVal溢出。针对这种情况可以采取字符串的部分字符进行计算,例如计算偶数或者奇数位的字符。
6、再散列(rehashing)
如果散列表满了,再往散列表中插入新的元素时候就会失败。这个时候可以通过创建另外一个散列表,使得新的散列表的长度是当前散列表的2倍多一些,重新计算各个元素的hash值,插入到新的散列表中。再散列的问题是在什么时候进行最好,有三种情况可以判断是否该进行再散列:
(1)当散列表将快要满了,给定一个范围,例如散列被中已经被用到了80%,这个时候进行再散列。
(2)当插入一个新元素失败时候,进行再散列。
(3)根据装载因子(存放n个元素的、具有m个槽位的散列表T,装载因子α=n/m,即每个链子中的平均存储的元素数目)进行判断,当装载因子达到一定的阈值时候,进行在散列。
在采用链接法处理碰撞问题时,采用第三种方法进行在散列效率最好。
7、实例练习
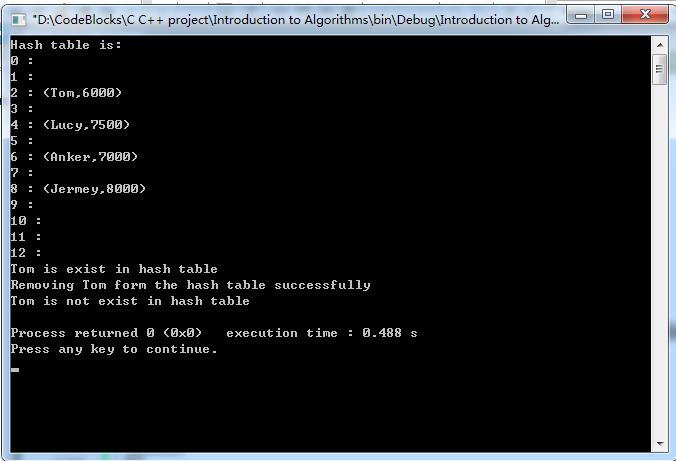
看完书后,有一股想把hash表实现的冲动。在此设计的散列表针对的是关键字为字符串的元素,采用字符串散列函数方法3进行设计散列函数,采用链接方法处理碰撞,然后采用根据装载因子(指定为1,同时将n个元素映射到一个链表上,即n==m时候)进行再散列。采用C++,借助vector和list,设计的hash表框架如下:
运行结果:
以上是关于散列表的主要内容,如果未能解决你的问题,请参考以下文章
下列代码的功能是利用散列函数hash将一个元素插入到散列表ht[]中。其中list类型的结点包含element类型的项item以及一个next指针。如果插入成功,则函数返回1,否则返回0。
下列代码的功能是利用散列函数hash将一个元素插入到散列表ht[]中。其中list类型的结点包含element类型的项item以及一个next指针。如果插入成功,则函数返回1,否则返回0。