P1-概率论基础(Primer on Probability Theory)
Posted 郭润
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了P1-概率论基础(Primer on Probability Theory)相关的知识,希望对你有一定的参考价值。
2.1概率密度函数
2.1.1定义
设p(x)为随机变量x在区间[a,b]的概率密度函数,p(x)是一个非负函数,且满足

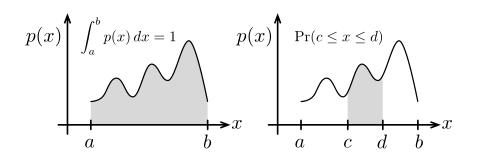
注意概率与概率密度函数的区别。
概率是在概率密度函数下对应区域的面积,如上图右所示,其公式如下
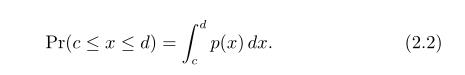
我们用概率密度函数来表示在区间[a,b]中所有可能的状态x的可能性。
条件概率密度函数,设p(x|y)是在条件y属于[r,s]下x(x属于[a,b])的概率密度函数,有
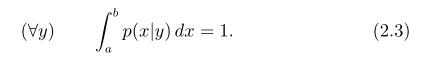
N维连续随机变量的联合概率密度函数记为p(X),其中X=(x1,...,xn),xi属于[ai,bi],有时我们也用符号
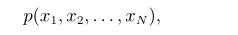 来替代p(X).
来替代p(X).
有时,甚至会混合搭配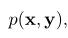 作为X和Y的联合概率密度函数。在N维例子中,有
作为X和Y的联合概率密度函数。在N维例子中,有
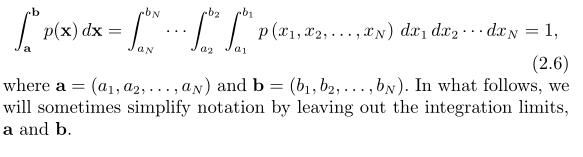
2.1.2贝叶斯规则和推导
首先,把一个联合概率密度函数进行因式分解,有
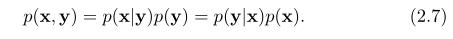
重新整理后得到贝叶斯原理:
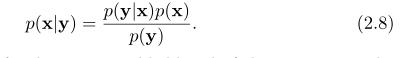
我们可以通过这个公式来推导在给定测量条件下状态的后验概率-p(x|y)。如果我们有一个对状态的先验概率密度函数p(x),以及对传感器模型的先验概率密度函数p(y|x)。通过扩大分母,有如下,
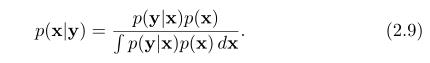
分母的由来通过边缘化,如下
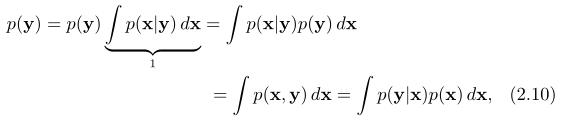 ,这在一般的非线性情况下去这么解释非常耗时的。
,这在一般的非线性情况下去这么解释非常耗时的。
注意,在贝叶斯推论中,p(x)称为先验概率密度函数,而p(x|y)称为后验概率密度函数。这样,所有的先验信息都集中于p(x)而所有的后验信息都集中于p(x|y)。
2.1.3概率密度函数的矩
第0阶概率矩总是为1,第一阶概率矩称为均值μ,有如下
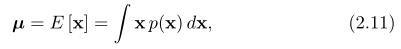
对于一般的矩阵函数F(X),其期望写成
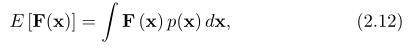
但是我们把上面写成
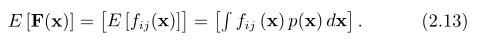
第二阶概率矩称为协方差矩阵Σ:
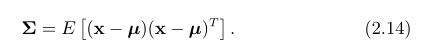
那么下两个矩称为skewness and kurtosis(偏态和峰态)。
!!!!!!!!!向量的概率相关信息以及随机变量的概率相关信息的区别
2.14 样本均值和协方差
假设我们有随机变量x,以及它的概率密度函数p(x),我们可以从这个概率密度函数中得到样本,可以表示为

一个样本有时也称为随机变量的一个实现,我们直观地把它想成一次测量。
如果我们想要得到N个那样的样本,且想要估计随机变量x的均值和协方差,我们可以运用样本均值和样本协方差来这么做:
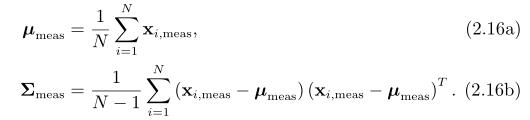
很明显,在样本协方差中的分母运用N-1而非N来作为归一化,这称为贝塞尔的校正。
2.1.5统计独立,以及不相关
两个随机变量x和y,我们说他们统计独立的话,则他们的联合概率密度因式分解为如下:

如果有以下等式成立
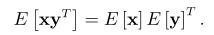 ,则称变量不相关。
,则称变量不相关。
独立一定不相关,反之,则不然。我们将通常假设变量是统计独立的来简化计算。
2.1.6香农和互信息
通常我们对一些随机变量估计其概率密度函数,然后想要去量化我们是有多么的确定,例如,概率密度函数的均值。
一种方法就是查看负熵或者香农信息,H,它由如下给出
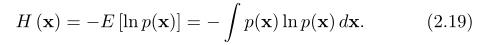
我们将在下面用高斯概率密度函数具体来表达。
另一个有用的量是互信息,I(X,Y),它在随机变量x和y之间,形式给出如下

互信息(Mutual Information)是信息论里一种有用的信息度量,它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性。
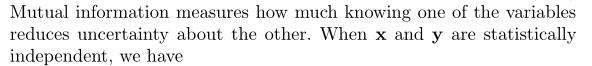
当x和y都统计独立,则有

当x和y是依赖的,我们有 我们还有有用的关系,如下
我们还有有用的关系,如下
2.17Cramer-Rao下界和费舍尔信息
假设有一个确定性的参数 θ,它影响随机变量x的结果。这可以通过把x的概率密度函数写成依赖于 θ来获得,如下

进一步假设我们得到一个从p(x| θ)的样本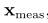 ,
,

那么, the Cramér-Rao lower bound (CRLB)说的是确定性参数θ的然和无偏估计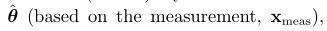 的协方差由费舍尔信息矩阵定下界,
的协方差由费舍尔信息矩阵定下界,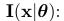
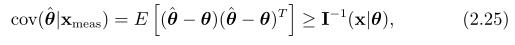
无偏估计意味着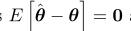 ,下界意味着
,下界意味着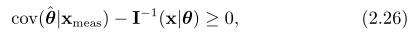

因此CRLB就设置了一个基本的下限在给出我们测量之后,对一个参数的估计有多确定。
2.2高斯概率密度函数
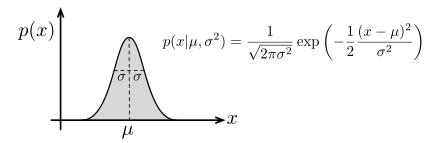
一维高斯概率密度函数,由如下形式给出

μ是均值,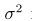 是协方差,σ表示标准差,下图表示了一维高斯密度函数,
是协方差,σ表示标准差,下图表示了一维高斯密度函数,
多维高斯密度函数,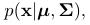 ,其中随机变量x是n维的,
,其中随机变量x是n维的,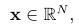 表达如下,
表达如下,
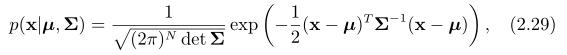
 是一个对称正定的协方差矩阵
是一个对称正定的协方差矩阵

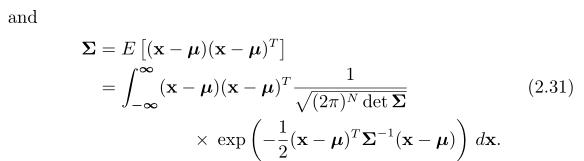

2.2.2 Isserlis定理
多维高斯密度函数的矩去计算均值以及协方差以外的量会比较麻烦,但是有一些具体的例子稍后我们会利用,这值得讨论。我们可以运用Isserlis定理来计算更高阶的高斯随机变量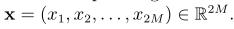
定理如下
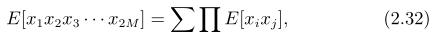
设有四个变量,表示如下
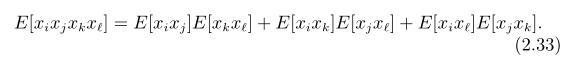
我们可以把这个理论应用到计算矩阵表示的有用结果。
假设有,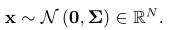 ,要去计算表达式
,要去计算表达式
p为非负整数,当p=0时,有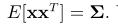 ,当p=1时,有
,当p=1时,有

在标量中,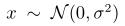 ,因此由上面得出,
,因此由上面得出,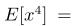
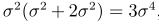 ,对于p大于1,也用同样的方法。
,对于p大于1,也用同样的方法。
我们也考虑如下例子,
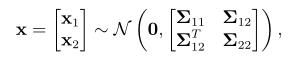
x1的维数为N1,x2的维数为N2,计算如下表达式

同理,p是非负整数,当p=0时,有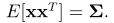 ,当p=1时,有
,当p=1时,有
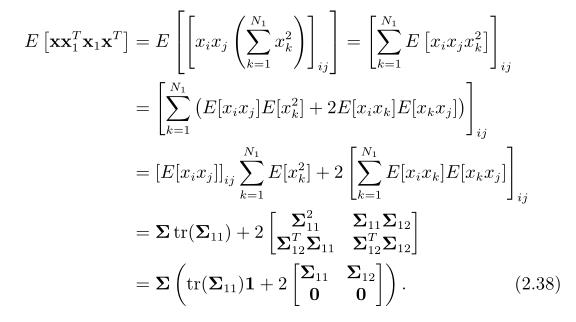
类似的,有

最后来核查一下,有

进一步,我们有
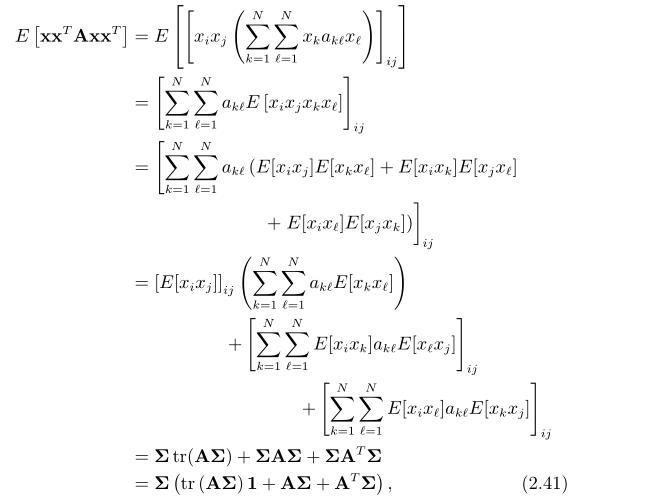
A是一个与上面兼容的方阵。
2.2.3联合高斯概率密度函数,他们的因式分解,以及推断
对一对变量(x,y)的联合高斯,可写为
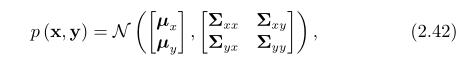
它也有同样的概率表示形式,这里的
我们可以用舒尔补码来求解联合高斯
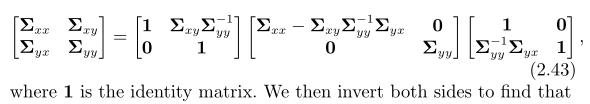
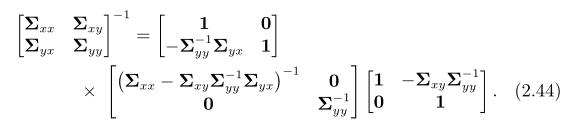
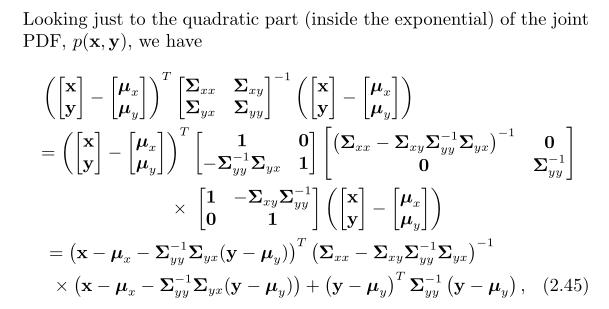
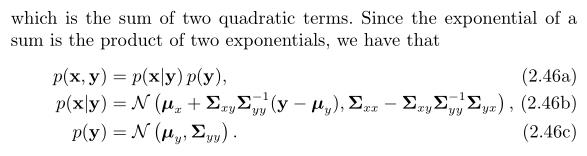
很重要的是p(x|y)和p(y)是高斯密度函数,如果正好我们知道y的值(比如经过测量得到的),我们就可以计算出x在y条件下的可能性通过p(x|y)来计算。
这是高斯推断的一个基础:我们以关于我们的先验状态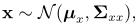 开始,然后通过一些测量
开始,然后通过一些测量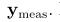 来缩小先验状态x的范围,在 (2.46b)中,我们看到了对均值
来缩小先验状态x的范围,在 (2.46b)中,我们看到了对均值 和协方差
和协方差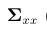 的一个调整,使之变得更小了。
的一个调整,使之变得更小了。
以上是关于P1-概率论基础(Primer on Probability Theory)的主要内容,如果未能解决你的问题,请参考以下文章
概率论与数理统计p1-4 前言随机试验样本空间事件间的关系事件的运算及运算法则