挑子学习笔记:两步聚类算法(TwoStep Cluster Algorithm)——改进的BIRCH算法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了挑子学习笔记:两步聚类算法(TwoStep Cluster Algorithm)——改进的BIRCH算法相关的知识,希望对你有一定的参考价值。
转载请标明出处:http://www.cnblogs.com/tiaozistudy/p/twostep_cluster_algorithm.html
两步聚类算法是在SPSS Modeler中使用的一种聚类算法,是BIRCH层次聚类算法的改进版本。可以应用于混合属性数据集的聚类,同时加入了自动确定最佳簇数量的机制,使得方法更加实用。本文在学习文献[1]和“IBM SPSS Modeler 15 Algorithms Guide”的基础上,融入了自己的理解,更详尽地叙述两步聚类算法的流程和细节。阅读本文之前需要先行学习BIRCH层次聚类算法和对数似然距离。
两步聚类算法,顾名思义分为两个阶段:
1)预聚类(pre-clustering)阶段。采用了BIRCH算法中CF树生长的思想,逐个读取数据集中数据点,在生成CF树的同时,预先聚类密集区域的数据点,形成诸多的小的子簇(sub-cluster)。
2)聚类(clustering)阶段。以预聚类阶段的结果——子簇为对象,利用凝聚法(agglomerative hierarchical clustering method),逐个地合并子簇,直到期望的簇数量。
两步聚类算法的关键技术如图所示:
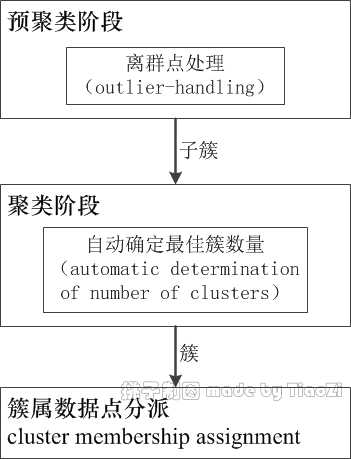
图 1:两步聚类算法的关键技术及流程
设数据集$\\mathfrak D $中有$N $个数据对象/数据点$\\{ \\vec x_n: n=1,...,N\\} $,每个数据对象由$D $个属性刻画,其中有$D_1 $个连续型属性(continuous attribute)和$D_2 $个分类型属性(categorical attribute),设$\\vec x_n = (\\tilde x_{n1}, ..., \\tilde x_{nD_1}, \\ddot x_{n1},..., \\ddot x_{nD_2}) $,其中$\\tilde x_{ns} $表示第$n $个数据对象在第$s $连续型属性下的属性值,$\\ddot x_{nt} $表示第$n $个数据对象在第$t $分类型属性下的属性值,已知第$t $个分类型属性有$\\epsilon_t $种可能取值。$\\mathbf C_J = \\{C_1,...,C_J\\} $表示对数据集$\\mathfrak D $的簇数为$J $的聚类,其中$C_j $表示聚类$\\mathbf C_J $中第$j $个簇,不失一般性,设簇$C_j $中有$N_j $个数据对象,$ \\{\\vec x_{jn}: n=1,...,N_j\\} $.
1、预聚类阶段
在本阶段,首先逐个将数据集$\\mathfrak D $中数据点,插入到聚类特征树(CF树)中,实现CF树的生长;当CF树的体积超出设定尺寸时,先剔除当前CF树上的潜在离群点,而后增加空间阈值并对CF树进行瘦身(rebuilding),再将不增加瘦身后的CF树体积的离群点插入CF树中;当遍历所有数据点后,不能插入CF树中的潜在离群点即为真正离群点;最后将最终CF树叶元项(leaf entry)对应子簇的聚类特征输出至算法的下一阶段。本阶段的流程见下图:
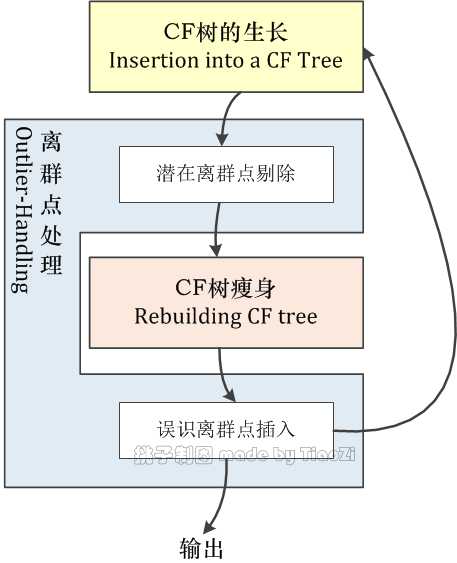
图 2:预聚类阶段流程
1.1 聚类特征
首先,与BIRCH算法相同,定义簇$\\mathfrak D $(也可以是任意的若干个数据点的集合)的聚类特征(cluster feature):
定义 1:簇$C_j $的聚类特征$\\vec {CF}_j $定义为四元组:$ \\vec {CF}_j = \\langle N_j, \\vec {\\tilde \\Lambda}_j, \\vec {\\tilde \\Sigma}_j, \\vec {\\ddot N}_j \\rangle $,其中,$$ \\begin{equation} \\vec {\\tilde \\Lambda}_j = (\\tilde \\Lambda_{j1}, ..., \\tilde \\Lambda_{jD_1})^T = \\left(\\sum_{n=1}^{N_j} \\tilde x_{jn1}, ..., \\sum_{n=1}^{N_j} \\tilde x_{jnD_1} \\right)^T \\end{equation} $$表示各连续型属性下簇$C_j $中数据点属性值的线性求和,$$ \\begin{equation} \\vec {\\tilde \\Sigma}_j = (\\tilde \\Sigma_{j1},..., \\tilde \\Sigma_{jD_1})^T = \\left ( \\sum_{n=1}^{N_j} \\tilde x_{jn1}^2,..., \\sum_{n=1}^{N_j} \\tilde x_{jnD_1}^2 \\right )^T \\end{equation} $$表示各连续型属性下簇$C_j $中数据点属性值的平方和,$$ \\begin{equation} \\vec {\\ddot N}_j = \\left ( (\\vec {\\ddot N}_{j1})^T, ..., (\\vec {\\ddot N}_{jD_2})^T \\right )^T \\end{equation} $$式中$\\vec {\\ddot N}_{jt} = (\\ddot N_{jt1}, ..., \\ddot N_{j,t,\\epsilon_t-1})^T $为簇$C_j $中在第$t $个分类型属性下各可能取值的数据点数量构成的向量,即$\\ddot N_{jtk} \\; (k=1,...,\\epsilon_t-1) $表示簇$C_j $中在第$t $个分类型属性下第$k $种取值的数据点数量,因为$\\ddot N_{jt\\epsilon_t} = N_j - \\sum_{k=1}^{\\epsilon_t -1} \\ddot N_{jtk} $,所以向量$\\vec {\\ddot N}_{jt} $的维度为$\\epsilon_t - 1 $,向量$\\vec {\\ddot N}_j $的维度为$\\sum_{t=1}^{D_2} (\\epsilon_t - 1) $.
与BIRCH算法中的聚类特征相似,上述定义中的聚类特征也具有可加性:
定理 1:设簇$C_j $的聚类特征为$ \\vec {CF}_j = \\langle N_j, \\vec {\\tilde \\Lambda}_j, \\vec {\\tilde \\Sigma}_j, \\vec {\\ddot N}_j \\rangle $,另有簇$C_{j‘} $,其聚类特征为$ \\vec {CF}_{j‘} = \\langle N_{j‘}, \\vec {\\tilde \\Lambda}_{j‘}, \\vec {\\tilde \\Sigma}_{j‘}, \\vec {\\ddot N}_{j‘} \\rangle $,则将簇$C_j $和$C_{j‘} $合并成大簇$C_{\\langle j,j‘ \\rangle} $后,其聚类特征为$$ \\begin{equation} \\vec {CF}_{\\langle j,j‘ \\rangle} = \\langle N_j + N_{j‘}, \\vec {\\tilde \\Lambda}_j + \\vec {\\tilde \\Lambda}_{j‘}, \\vec {\\tilde \\Sigma}_j + \\vec {\\tilde \\Sigma}_{j‘}, \\vec {\\ddot N}_j + \\vec {\\ddot N}_{j‘} \\rangle \\end{equation} $$
从上述定义可知,两步聚类算法的聚类特征与BIRCH算法中定义的聚类特征有所区别,但功能是相同的:簇与簇之间的相异度/距离可以通过聚类特征中的统计量表示出来,因此可以在两步聚类算法的流程中使用聚类特征压缩数据,降低算法耗用的内存。不同的是,BIRCH算法中使用的是诸如欧基里德距离和曼哈顿距离等常见距离,而两步聚类算法为了达到处理混合属性的要求,使用了对数似然距离。对于簇$C_j $,定义参数$$ \\begin{equation} \\zeta_j = -N_j \\left ( \\frac12 \\sum_{s=1}^{D_1} \\ln (\\hat \\sigma^2_{js} + \\hat \\sigma_s^2) + \\sum_{t=1}^{D_2} \\hat E_{jt} \\right ) \\end{equation} $$其中,$ \\hat \\sigma^2_{js} = 1/{N_j} \\sum_{n=1}^{N_j} (\\tilde x_{jns} - \\bar {\\tilde x}_{js})^2 $表示根据簇$C_j $中的数据点估计出的第$s $个连续型属性下的方差($\\bar{\\tilde x}_{js} = 1/N_j \\sum_{n=1}^{N_j} \\tilde x_{jns} $),$\\hat \\sigma_s^2 = 1/N \\sum_{n=1}^N (\\tilde x_{ns} - \\bar{\\tilde x}_s)^2 $表示根据数据集$\\mathfrak D $中所有数据点估计出的第$s $个连续型属性下的方差,在整个算法流程中一次计算即可,可视为常量,$\\hat E_{jt} = -\\sum_{k=1}^{\\epsilon_t} \\ddot N_{jtk}/N_j \\ln (\\ddot N_{jtk}/N_j) $表示簇$C_j $中第$t $上分类型属性下的信息熵。
易知,$$ \\begin{equation} \\begin{split} \\hat \\sigma^2_{js} & = \\frac 1{N_j} \\sum_{n=1}^{N_j} (\\tilde x_{jns} - \\bar{\\tilde x}_{js})^2 \\\\ & = \\frac 1{N_j} \\left [ \\sum_{n=1}^{N_j} \\tilde x_{jns}^2 - \\frac 1{N_j} \\left ( \\sum_{n=1}^{N_j} \\tilde x_{jns} \\right )^2 \\right ] \\\\ & = \\frac {\\tilde \\Sigma_{js}}{N_j} - \\left ( \\frac {\\tilde \\Lambda_{js}}{N_j} \\right )^2 \\end{split} \\end{equation} $$$$\\begin {equation} \\begin{split} \\hat E_{jt} & = -\\sum_{k=1}^{\\epsilon_t} \\left ( \\frac {\\ddot N_{jtk}}{N_j} \\ln {\\frac {\\ddot N_{jtk}}{N_j}} \\right ) \\\\ & = -\\sum_{k=1}^{\\epsilon_t-1} \\left ( \\frac {\\ddot N_{jtk}}{N_j} \\ln {\\frac {\\ddot N_{jtk}}{N_j}} \\right ) - \\frac {\\ddot N_{jt\\epsilon_t}}{N_j} \\ln {\\frac {\\ddot N_{jt\\epsilon_t}}{N_j}} \\\\ & = - \\frac{\\vec {\\ddot N}_{jt}^T}{N_j} \\cdot \\ln{\\frac{\\vec {\\ddot N}_{jt}^T}{N_j}} - \\left ( 1 - \\frac{\\vec 1^T \\vec {\\ddot N}_{jt}^T}{N_j} \\right ) \\cdot \\ln {\\left ( 1 - \\frac{\\vec 1^T \\vec {\\ddot N}_{jt}^T}{N_j} \\right )} \\end{split} \\end{equation} $$其中$\\vec 1 = (1,1,...,1)^T $为全1向量。因此式(5)中的参数$\\zeta_j $完全可以由簇$C_j $的聚类特征$ \\vec {CF}_j = \\langle N_j, \\vec {\\tilde \\Lambda}_j, \\vec {\\tilde \\Sigma}_j, \\vec {\\ddot N}_j \\rangle $计算得到。
因为簇$C_j $与簇$C_{j‘} $之间的对数似然距离如下定义:$$ \\begin{equation} d(C_j, C_{j‘}) = \\zeta_j + \\zeta_{j‘} - \\zeta_{\\langle j,j‘ \\rangle} \\end{equation} $$所以当知道任意两个簇的聚类特征后,其对数似然距离可直接根据聚类特征计算得到。
1.2 聚类特征树(CF树)
两步聚类算法中的CF树与BIRCH算法中的CF树几乎完全一样,生长和瘦身流程也可以完全参照BIRCH算法进行,本节主要叙述两步聚类算法中区别于BIRCH算法的独特之处,建议先对BIRCH层次聚类算法的相关知识点进行必要的学习。
1)两步聚类算法的CF树上各节点元项的聚类特征为本文定义 1中的聚类特征,与BIRCH算法不同;
2)两步聚类算法的CF树的三个参数分别为:枝平衡因子$\\beta $、叶平衡因子$\\lambda $和阈值$\\tau $;前两个参数与BIRCH算法无异,由于混合属性的原因,难以定义簇的散布程度(在BIRCH算法中有半径和直径的度量),因此两步聚类算法换了一个思路:既然BIRCH算法中的散布程度和空间阈值只是用于作为判断一个簇或者一个数据点能否被CF树上某个叶元项吸收的依据,可通过簇$C_{j‘} $(该簇可能是单数据点的簇)与簇$C_j $之间的距离来判断$C_{j‘} $能否被$C_j $吸收,如果$d(C_{j}, C_{j‘}) \\le \\tau $,则$C_{j‘} $可以被$C_j $吸收。
1.3 离群点处理(outlier-handling)
离群点处理非两步聚类算法的必选项。一旦确认需要在CF树生长的过程中实施离群点处理,将逐步筛选出潜在离群点,并重新插入误识离群点到CF树中。
1)潜在离群点的筛选。在CF树实施瘦身(rebuilding)之前,依据叶元项中包含数据点的多寡筛选出潜在离群点,叶元项包含的数据点数目即为对应聚类特征中的第一个量($N_j $);具体来说,首先从当前CF树中的所有叶元项中找出包含最多数据点的元项,记录该元项包含的数据点数目($N_{\\max} $),根据事先确定的比例参数$\\alpha \\in [0,1] $;如果某叶元项包含的数据点数目小于$\\alpha N_{\\max} $,则该叶元项置为潜在离群点,从当前CF树中移除。
2)误识离群点的插入。在CF树瘦身(rebuilding)完毕后,逐个处理潜在离群点,如果能够在不增加当前CF树体积的条件下吸收到CF树中,则认为该潜在离群点为误识离群点,将插入至当前CF树上。
在完成数据集$\\mathfrak D $中所有数据点到CF树上的插入后,仍为潜在离群点的元项,视为最终离群点。
2、聚类阶段
该阶段的输入为预聚类阶段输出的最终CF树的叶元项的子簇(sub-cluster),记为$C_1,...,C_{J_0} $,事实上,并非包含具体数据点的子簇,只是各子簇的聚类特征:$\\vec {CF}_1,..., \\vec {CF}_{J_0} $.因此本阶段的工作是根据输入数据$\\vec {CF}_1,..., \\vec {CF}_{J_0} $,对子簇$C_1,...,C_{J_0} $进行二度聚类,最终实现期望簇数的聚类结果。
两步聚类算法使用凝聚法(agglomerative hierarchical clustering method)的思想递归地合并距离最近的簇达到上述目的。首先从$J_0 $个子簇$C_1,...,C_{J_0} $中找出距离最近的两个子簇,将它们合并成一个簇后,完成第一步,此时新的聚类中簇个数为$J_0-1 $;然后合并剩下的簇中距离最近的一对簇,重复地实施此操作,直到把所有子簇合并成一个大簇,得到簇数为1的聚类,因此可以得到的聚类有$\\mathbf C_{J_0}, ..., \\mathbf C_2, \\mathbf C_1 $;最后从这$J_0 $个聚类中输出期望簇数的聚类,例如期望的簇数为5时,输出结果为$\\mathbf C_5 $。
因为上述思想仅涉及簇间距离,完全可以基于聚类特征和对数似然距离达成目标。
2.1 自动确定最佳簇数(Automatic Determination of Number of Clusters)
自动确定聚类的最佳簇数是两步聚类算法的特点之一。两步聚类算法使用两招:粗估和精定,达到了准确确定聚类最佳簇数的效果。
1)粗估主要借助贝叶斯信息准则(BIC, Bayesian information ciriterion)以找到最佳簇数的大致范围。
贝叶斯信息准则又称为Schwarz’s information criterion,是由G. Schwarz[2]提出的用于模型评估的准则。
假设有$r $个模型$M_1,...,M_r $,模型$M_i $由概率函数$f_i(x; \\theta_i) $画,其中$\\theta_i $的参数空间为$k_i $维,即$\\theta_i \\in \\Theta_i \\subset \\mathbb R^{k_i} $,现有$n $个观测值$x_1,...,x_n $,如何为已有的观测值,选择出最优的模型,是Schwarz提出BIC的目的。BIC的计算公式如下:$$ \\begin{equation} \\mathrm{BIC}(M_i) = -2 \\ln f_i(x; \\hat \\theta_i) + k_i \\ln n \\end{equation} $$式中$\\hat \\theta_i $为$f_i(x;\\theta) $的极大似然估计。对于上述$r $上模型,由公式计算得到的BIC值最小,则是符合上述$n $个观测值的最优模型。
按照(9)式,可如下式计算聚类$\\mathbf C_J = \\{C_1,...,C_J\\} $:$$ \\begin{equation} \\mathrm {BIC}(\\mathbf C_J) = -2 L_{\\mathbf C_J} + K \\ln N \\end{equation} $$根据“对数似然距离”一文中(16)式,$L_{\\mathbf C_J} $为簇划分对数似然值,且有$$ L_{\\mathbf C_J} = \\sum_{j=1}^J L_{C_j} = \\sum_{j=1}^J \\zeta_j $$ $\\zeta_j $见上文(5)式;因为每个连续型属性都有期望和方差2个参数,每个分类型属性都有取值个数$\\epsilon_t - 1 $个参数,所以上式中$$ K = J \\left ( 2 D_1 + \\sum_{t=1}^{D_2} (\\epsilon_t - 1) \\right ) $$ $N $表示$\\mathbf C_J $中包含的数据点的总数。
将由凝聚法得到的所有聚类$\\mathbf C_{J_0}, ..., \\mathbf C_2, \\mathbf C_1 $,代入到(10)式中,得到所有聚类的BIC值,$\\mathrm {BIC}(\\mathbf C_1), ..., \\mathrm {BIC}(\\mathbf C_{J_0}) $,然后根据相邻聚类BIC值的差值:$$ \\begin{equation} \\Delta_{\\mathrm {BIC}}(J) = \\mathrm{BIC} (\\mathbf C_J) - \\mathrm{BIC} (\\mathbf C_{J+1}), \\quad J=1,...,J_0 \\end{equation} $$计算出BIC值的变化率:$$ \\begin{equation} r_1(J) = \\frac{\\Delta_{\\mathrm{BIC}}(J)}{\\Delta_{\\mathrm{BIC}}(1)} \\end{equation} $$根据(12)式对最佳簇数作初步估计:如果$\\Delta_{\\mathrm{BIC}}(1) < 0 $,最佳簇数设为1,略去后续“精定”步骤;否则,找出所有$r_1(J) < 0.04 $的$J $,置最小的$J $为最佳簇数的初步估计,即$ J_I = \\min \\{ J \\in \\{ 1,...,J_0 \\}: r_1(J) < 0.04 \\} $.
2)精定是从最佳簇数的初步估计$J_I $开始,依据前后两个聚类中最近簇距离的比值,精确定位最佳簇数。
首先设有聚类$\\mathbf C_J = \\{ C_1,...,C_J\\} $,定义聚类$\\mathbf C_J $中最近簇的距离为:$d_{\\min}(\\mathbf C_J) = \\min \\{ d(C_j, C_{j‘}): C_j \\neq C_{j‘} \\in \\mathbf C_J \\} $,其中$d(C_j, C_{j‘}) $是由(8)式定义的对数似然距离。
聚类$\\mathbf C_J $和$\\mathbf C_{J+1} $的最近簇距离的比值定义为:$$ \\begin{equation} r_2(J) = \\frac{d_{\\min}(\\mathbf C_J)}{d_{\\min}(\\mathbf C_{J+1})}, \\quad J = J_I,...,2 \\end{equation} $$从$r_2(J) $的定义可知,根据凝聚法的聚类过程,从聚类$\\mathbf C_{J+1} $到$\\mathbf C_J $是通过将前者中距离最近的两个簇合并得到的,因此一般有$d_{\\min}(\\mathbf C_{J+1}) \\le d_{\\min}(\\mathbf C_J) $,或者说一般有$r_2(J) \\ge 1 $.
从所有最近簇距离的比值$\\{ r_2(J): J=2,...,J_I \\} $中找出最大的两个,记录对应簇数$J_1 = \\max_{J\\in \\{ 2,...,J_I\\}} \\{r_2(J)\\} $和$J_2 = \\max_{J\\in \\{ 2,...,J_I\\} \\setminus \\{J_1\\}} \\{r_2(J)\\} $,然后从$J_1 $和$J_2 $中筛选出最佳簇数:$$ \\begin{equation} J^* = \\begin{cases} J_1, & \\text{if } J_1 / J_2 > 1.15 \\\\ \\max \\{ J_1, J_2 \\}, & \\text{otherwise} \\end{cases} \\end{equation} $$至此,完成了最佳簇数$J^* $的确定,输出$\\mathbf C_{J^*} $作为最终的聚类结果。
3、簇属数据点分派(Cluster Membership Assignment)
经过上述计算,得到了最终的聚类$\\mathbf C_{J^*} = \\{ C_1, C_2,..., C_{J^*} \\} $,但是并不知道该聚类中的各簇都具体地包含了那些点,只知道各簇的聚类特征,因此需要通过此步骤完成数据集$\\mathfrak D $中各数据点到相应簇的分派。
如果整个算法过程中没有进行离群点处理操作,分派工作就十分简单,只需逐个将数据集$\\mathfrak D $中的数据点$\\vec x_i $视为单点的簇,通过计算数据点与聚类$\\mathbf C_{J^*} $中各簇的对数似然距离$d(\\{\\vec x_i\\}, C_j) $,将该数据点放入最近的簇中即可。
然而如果算法的实施过程中考虑了离群点,则设置阈值$$ \\begin{equation} \\tau_d = \\sum_{s=1}^{D_1} \\ln \\rho_s + \\sum_{t=1}^{D_2} \\ln \\epsilon_t \\end{equation} $$其中$\\rho_s $表示第$s $个连续型属性的取值范围,$\\epsilon_t $表示第$t $个分类型属性的取值数目。对于数据点$\\vec x_i $而言,如果$d(\\{\\vec x_i\\}, C_{j^*}) = \\min_{C_j \\in \\mathbf C_{J^*}} \\{ d(\\{\\vec x_i\\}, C_j) \\} $且$d(\\{\\vec x_i\\}, C_{j^*}) < \\tau_d $,将$\\vec x_i $分派至簇$ C_{j^*} $中;否则视数据点$\\vec x_i $为离群点。
参考文献
[1] Chiu T, Fang D P, Chen J, et al. A robust and scalable clustering algorithm for mixed type attributes in large database environment[C]// ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2001:263-268.
[2] Schwarz G. Estimating the Dimension of a Model[J]. Annals of Statistics, 1978, 6(2): pp. 15-18.
以上是关于挑子学习笔记:两步聚类算法(TwoStep Cluster Algorithm)——改进的BIRCH算法的主要内容,如果未能解决你的问题,请参考以下文章