挑子学习笔记:BIRCH层次聚类
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了挑子学习笔记:BIRCH层次聚类相关的知识,希望对你有一定的参考价值。
转载请标明出处:http://www.cnblogs.com/tiaozistudy/p/6129425.html
本文是“挑子”在学习BIRCH算法过程中的笔记摘录,文中不乏一些个人理解,不当之处望多加指正。本人邮箱:[email protected]
BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies,利用层次结构的平衡迭代归约和聚类)是由T. Zhang等人[1]于1996年为大量聚类设计的一种层次聚类方法。
1、聚类特征(Clustering Feature)
BIRCH使用聚类特征概括描述各簇的信息,其定义如下:
定义 1:设某簇中有$N$个$D$维的数据点,$\\{\\vec x_n \\} \\; (n=1,2,...,N) $,则该簇的聚类特征$\\vec {CF} $定义为三元组:$ \\vec {CF} = \\langle N, \\vec {\\Sigma}_l, {\\Sigma}_s \\rangle $,其中$N$为该簇中数据点的数量,矢量$$\\begin{equation} \\vec {\\Sigma}_l = \\sum_{n=1}^N \\vec x _n = \\left(\\sum_{n=1}^N x_{n1}, \\sum_{n=1}^N x_{n2}, ..., \\sum_{n=1}^N x_{nD} \\right)^T \\end{equation} $$为各数据点的线性求和,标量$$ \\begin{equation} {\\Sigma}_s = \\sum_{n=1}^N \\vec x _n^2 = \\sum_{n=1}^N \\vec x _n^T \\vec x_n = \\sum_{n=1}^N \\sum_{i=1}^D x_{ni}^2 \\end{equation} $$为各数据点的平方和[a]。
根据上述定义有如下定理:
定理 1(可加性定理):设$\\vec {CF}_1 = \\langle N_1, \\vec {\\Sigma}_{l1}, {\\Sigma}_{s1} \\rangle$和$\\vec {CF}_2 = \\langle N_2, \\vec {\\Sigma}_{l2}, {\\Sigma}_{s2} \\rangle$分别表示两个不相交的簇的聚类特征,如果将这两个簇合并成一个大簇,则大簇的聚类特征为$$\\begin{equation} \\vec {CF}_1 + \\vec {CF}_2 = \\langle N_1+N_2, \\vec {\\Sigma}_{l1} + \\vec {\\Sigma}_{l2}, {\\Sigma}_{s1} + {\\Sigma}_{s2} \\rangle \\end{equation}$$
例 1[2]:假设簇1有三个数据点$(2,5) $、$(3,2) $和$(4,3) $,根据定义 1,簇1的聚类特征是$$ \\begin{split} \\vec{CF}_1 & = \\langle 3, (2+3+4, 5+2+3), (2^2+5^2)+(3^2+2^2)+(4^2+3^2) \\rangle \\\\ & = \\langle 3, (9,10), 67 \\rangle \\end{split}$$如有与簇1不相交的簇2,该簇聚类特征是$$\\vec{CF}_2 = \\langle 3, (35, 36), 857 \\rangle $$簇1与簇2合并之后形成簇3,簇3的聚类特征可如式(3)计算:$$ \\begin{split} \\vec{CF}_3 & = \\vec{CF}_1 + \\vec{CF}_2 \\\\ & = \\langle 3+3, (9+35, 10 + 36), 67+857 \\rangle \\\\ & = \\langle 6, (44, 46), 924 \\rangle \\end{split} $$
聚类特征本质上是给定簇的统计汇总,可以有效地对数据进行压缩,而且基于聚类特征可以很容易地推导出簇的许多统计量和距离度量。假设给定簇中有$N$个$D$维的数据点,$\\{\\vec x_n : n=1,2,...,N\\} $,则在簇的统计量方面可以推导出形心$ \\bar {\\vec x} $、半径$\\rho$和直径$\\delta$:$$\\begin{equation} \\bar {\\vec x} = \\frac 1N \\sum_{n = 1} ^N \\vec x_n = \\frac {\\vec {\\Sigma}_l}{N} \\end{equation}$$$$ \\begin{equation} \\rho = \\sqrt{\\frac{\\sum_{n=1}^N (\\vec x_n - \\bar {\\vec x})^2}{N}} = \\sqrt{\\frac{N \\Sigma_s - \\vec{\\Sigma}_l^2}{N^2}} \\end{equation} $$$$ \\begin{equation} \\delta = \\sqrt{\\frac{\\sum_{m=1}^N \\sum_{n=1}^N (\\vec x_m - \\vec x_n)^2}{N(N-1)}} = \\sqrt{\\frac{2N {\\Sigma}_s - 2 \\vec {\\Sigma}_l^2}{N(N-1)}} \\end{equation} $$其中,$\\rho$是簇内数据点到簇形心的平均距离,$\\delta$是簇内两两数据点的平均距离,这两个统计量都反映了簇内紧实度。除此之外,基于聚类特征中的三项还可以进一步定义出不同簇间的距离度量,以反映出簇间邻近度。假设有两个簇,簇1由$N_1$个$D$维数据点组成:$\\{ \\vec x_{1m}: m=1,2,...,N_1 \\} $,其聚类特征为$\\vec{CF}_1 = \\langle N_1, \\vec {\\Sigma}_{l1}, \\Sigma_{s1} \\rangle $,形心为$ \\bar {\\vec x}_1 $、半径$\\rho_1 $和直径$\\delta_1$,簇2由$N_2$个$D$维数据点组成:$\\{ \\vec x_{2n}: n=1,2,...,N_2 \\} $,其聚类特征为$\\vec{CF}_2 = \\langle N_2, \\vec {\\Sigma}_{l2}, \\Sigma_{s2} \\rangle $,形心为$ \\bar {\\vec x}_2 $、半径$\\rho_2 $和直径$\\delta_2$,簇1和簇2可合并成簇3:$\\{ \\vec x_{3n}: n=1,2,...,N_1 + N_2 \\} $,不失一般性,可设簇3中前$N_1$个为簇1中数据点,后$N_2$个为簇2中数据点。在此假设下,可定义下述5个距离以度量簇1和簇2之间的相异性:$$ \\begin{equation} d_0 = \\sqrt{(\\bar{\\vec x}_1 - \\bar{\\vec x}_2)^2} = \\sqrt {\\left ( \\frac{\\vec{\\Sigma}_{l1}}{N_1} - \\frac{\\vec{\\Sigma}_{l2}}{N_2} \\right )^2} \\end{equation} $$$$ \\begin{equation} d_1 = | \\bar{\\vec x}_1 - \\bar{\\vec x}_2 | = \\left | \\frac{\\vec{\\Sigma}_{l1}}{N_1} - \\frac{\\vec{\\Sigma}_{l2}}{N_2} \\right | \\end{equation} $$$$ \\begin{equation} d_2 = \\sqrt{\\frac{\\sum_{m=1}^{N_1} \\sum_{n=1}^{N_2} (\\vec x_{1m} - \\vec x_{2n})^2}{N_1 N_2}} = \\sqrt{\\frac{\\Sigma_{s1}}{N_1} - 2\\frac{\\vec{\\Sigma}_{l1}^T}{N_1} \\frac{\\vec{\\Sigma}_{l2}}{N_2} + \\frac{\\Sigma_{s2}}{N_2}} \\end{equation} $$$$ \\begin{equation} \\begin{split} d_3 & = \\sqrt{\\frac{\\sum_{m=1}^{N_1 + N_2} \\sum_{n=1}^{N_1 + N_2} (\\vec{x}_{3m} - \\vec{x}_{3n})^2}{(N_1 + N_2)(N_1 + N_2 - 1)}} \\\\ & = \\sqrt{\\frac{2(N_1 + N_2)(\\Sigma_{s1} + \\Sigma_{s2}) - 2(\\vec{\\Sigma}_{l1} + \\vec{\\Sigma}_{l2})^2}{(N_1 + N_2)(N_1 + N_2 - 1)}} \\end{split} \\end{equation} $$$$ \\begin{equation} \\begin{split} d_4 = & \\rho_3 - \\rho_1 - \\rho_2 \\\\ = & \\sqrt{\\frac{(N_1 + N_2)(\\Sigma_{s1}+\\Sigma_{s_2}) - (\\vec{\\Sigma}_{l1} + \\vec{\\Sigma}_{l2})^2}{(N_1+N_2)^2}} - \\\\ & \\sqrt{\\frac{N_1 \\Sigma_{s1} - \\vec{\\Sigma}_{l1}^2}{N_1^2}} - \\sqrt{\\frac{N_2 \\Sigma_{s2} - \\vec{\\Sigma}_{l2}^2}{N_2^2}} \\end{split} \\end{equation} $$式(11)中$\\rho_3 $表示簇3的半径,上述距离中,$d_0 $称为形心欧基里得距离(centroid Euclidian distance),$d_1 $称为形心曼哈顿距离(centroid Manhattan distance),$d_2 $称为簇连通平均距离(average inter-cluster distance),$d_3 $称为全连通平均距离(average intra-cluster distance),$d_4 $称为散布恶化距离(variance increase distance)。
2、聚类特征(CF)树
CF树是等高树,有三个参数:枝平衡因子$\\beta$(branch factor)、叶平衡因子$\\lambda$(leaf factor)和空间阈值$\\tau$(threshold)。CF树由根节点(root node)、枝节点(branch node)和叶节点(leaf node)构成(如图 1所示),非叶节点(nonleaf node)中包含不多于$\\beta$个形如$[\\vec{CF}_i, child_i] $的元项(entry),其中$\\vec{CF}_i $表示该节点上第$i$个子簇的聚类特征信息,指针$child_i $指向该节点的第$i$个子节点。叶节点中包含不多于$\\lambda$个形如$[\\vec{CF}_i] $的元项,此外每个叶节点中都包含指针$prev$指向前一个叶节点和指针$next$指向后一个叶节点。每个节点都代表一个由各元项中聚类特征对应子簇(sub-cluster)合并而成的簇。空间阈值$\\tau$用于限制叶节点的子簇的大小,即所有叶节点的各元项对应子簇的直径$\\delta$或半径$\\rho$不得大于$\\tau$。
在本文中,假设CF树高为$H$,$O_{hi} $表示第$h$层的第$i$个节点,其中$O_{1i} $表示第$i$个叶节点,$O_{H1} $表示根节点,$\\epsilon_{hi} $表示节点$O_{hi} $中元项的个数,$E_{hij} $表示节点$O_{hi} $中的第$j$个元项,可以计算出元项$E_{hij} \\; (h > 1) $中指针指向的子节点为$O_{h-1,i‘} $,其中$i‘ = \\sum_{k=1}^{i-1} \\epsilon_{hk} + j $.
CF树上的路径定义为根节点到叶节点的节点的序列,由于上一层元项一一对应地指向下一层节点,也可以等价地认为路径是根节点到叶元项(leaf entry)的序列,因此路径有如下两种表示方式:$$\\begin{equation} \\begin{split} \\tilde P & = \\langle \\tilde p_1, \\tilde p_2, ..., \\tilde p_{H-1} \\rangle \\\\ & = \\langle E_{H1j_H}, E_{H-1,i_{H-1},j_{H-1}}, ..., E_{2i_2j_2} \\rangle \\\\ & = \\langle O_{H-1,i_{H-1}}, O_{H-2, i_{H-2}},..., O_{1i_1} \\rangle \\end{split} \\end{equation} $$其中,元项$E_{h,i_h,j_h} $与节点$O_{h-1,i_{h-1}} $一一对应,且有$ i_{h-1} = \\sum_{k=1}^{i_h-1} \\epsilon_{hk} + j_h $.从路径的定义易知,每个叶节点都有唯一的一条路径与之对应,并且根据各层节点的次序,可区分出路径的先后,假如有两条路径$\\tilde P^{(1)} = \\langle \\tilde p_1^{(1)}, ..., \\tilde p_{H-1}^{(1)} \\rangle $和$\\tilde P^{(2)} = \\langle \\tilde p_1^{(2)}, ..., \\tilde p_{H-1}^{(2)} \\rangle $,如果$\\tilde p_1^{(1)} = \\tilde p_1^{(2)} $, …, $\\tilde p_{h-1}^{(1)} = \\tilde p_{h-1}^{(2)} $,但$\\tilde p_{h}^{(1)} < \\tilde p_{h}^{(2)} $ $(0 \\le h \\le H-1) $,则路径$\\tilde P^{(1)} $在$\\tilde P^{(2)} $之前。
例 2:图 1中所示的CF树的参数分别为:$\\beta = 2 $、$\\lambda = 3 $,共分为3层,第1层中为根节点,第2层中有2个枝节点,第3层中共3个叶节点。以图中节点2为例,该节点中有2个元项:$[\\vec{CF}_3, child_3] $和$[\\vec{CF}_4, child_4] $,其中指针$child_3 $指向节点4,$child_4 $指向节点5,因此$\\vec{CF}_3 = \\vec{CF}_6 + \\vec{CF}_7 + \\vec{CF}_8 $,即$\\vec{CF}_6 $、$\\vec{CF}_7 $和$\\vec{CF}_8 $分别对应的3个簇合并后即是$\\vec{CF}_3 $对应的簇。
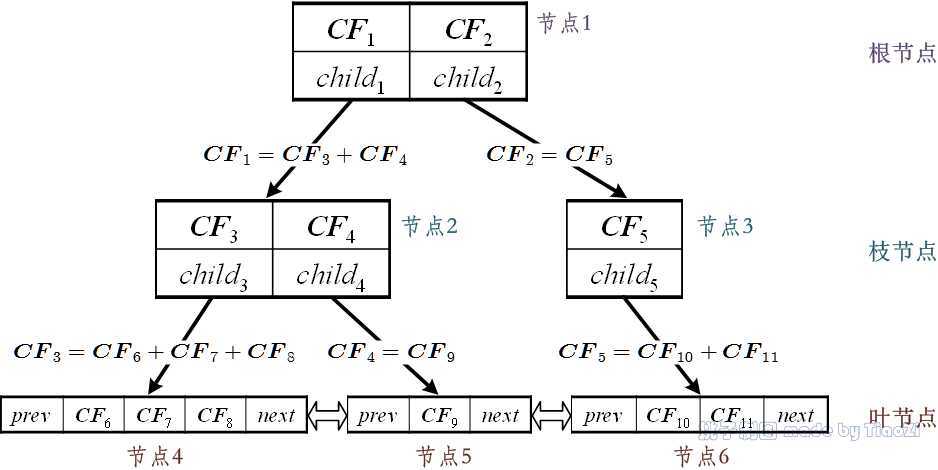
图 1:聚类特征树
图 1中各节点及其元项代表的簇间的关系如图 2所示。节点1代表的簇中包含了当前所有数据点,该簇分成了6个部分:分别是$\\vec{CF}_6 $、$\\vec{CF}_7 $、$\\vec{CF}_8 $、$\\vec{CF}_9 $、$\\vec{CF}_{10} $和$\\vec{CF}_{11} $对应的小簇。CF树上不同层次的节点及其包含数据点的范围由不同颜色表示。需要说明的是,CF树上不保存任何数据点,仅有树的结构信息以及相关的聚类特征信息,因此CF树可以达到压缩数据的效果。
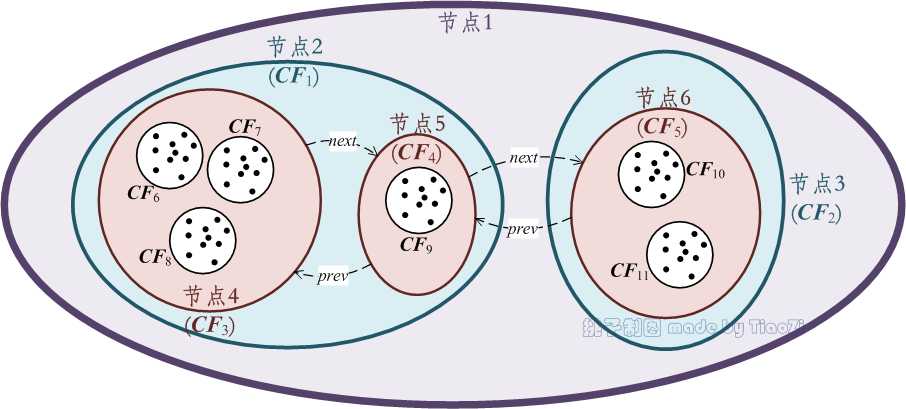
图 2:聚类特征树(图 1)对应的簇划分
3、CF树的生长(Insertion into a CF Tree)
CF树的生长由一根空树开始,是逐个插入一系列簇[b]的聚类特征到CF树的过程,方法步骤如下:
步骤1(初始化):初始化CF树为空树,置树高度$H=0 $,设置枝平衡因子$\\beta $、叶平衡因子$\\lambda $和空间阈值$\\tau $的值,从半径$\\rho $和直径$\\delta $中选择一个作为簇散布大小的统计量,记为$\\varsigma $,从$d_0 \\sim d_4 $中选择一个作为簇间距离的度量,记为$d $;
步骤2(选择最优插入路径):确定当前需要插入的簇$C $,计算其聚类特征信息.从根节点开始,逐层计算簇$C $与节点$O_{hi_h} $各元项$E_{hi_hj_h} $ $(j_h=1,...,\\epsilon_{hi_h}) $的距离$d(C,E_{hi_hj_h}) $,选出与簇$C $距离最近的元项$E_{hi_hj_h^*} $,并确定该元项对应的子节点$O_{h-1,i_{h-1}} \\; (i_{h-1} = \\sum_{k=1}^{i_h-1} \\epsilon_{hk} + j_h^*) $,直至叶节点。因此最优的插入路径为$$ \\begin{equation} \\begin{split} \\tilde P & = \\langle \\tilde p_1, \\tilde p_2, ..., \\tilde p_{H-1} \\rangle \\\\ & = \\langle E_{H1j_H^*}, E_{H-1,i_{H-1},j_{H-1}^*}, ..., E_{2i_2j_2^*} \\rangle \\\\ & = \\langle O_{H-1,i_{H-1}}, O_{H-2, i_{H-2}},..., O_{1i_1} \\rangle \\end{split} \\end{equation} $$该路径长度为$H-1 $,有元项和节点两种等价的表示方式。
步骤3(修剪叶子):在簇$C $到达叶节点$O_{1i_1} $后,首先设置参数$h‘ = 1 $,然后通过距离的计算筛选出与簇$C $最近的元项$E_{1i_1j_1^*} $,并验证元项$E_{1i_1,j_1^*} $是否有能力吸收簇$C $,即元项$E_{1i_1j_1^*} $对应的簇与簇$C $合并的大簇的散布大小$\\varsigma(E_{1i_1j_1^*} \\bigcup C) $是否满足空间阈值$\\tau $:
- 如果$\\varsigma(E_{1i_1j_1^*} \\bigcup C) \\le \\tau $,将簇$C $吸收进元项$E_{1i_1j_1^*} $中,并更新该元项的聚类特征,转步骤5;
- 否则,如果$\\varsigma(E_{1i_1j_1^*} \\bigcup C) > \\tau $,需要为叶节点$O_{1i_1} $新增一个元项:
- 如果该叶节点$O_{1i_1} $还能多容纳元项,即该节点元项的个数$\\epsilon_{1i_1} $小于叶平衡因子$\\lambda $,置$\\epsilon_{1i_1} = \\epsilon_{1i_1} + 1 $,为叶节点$O_{1i_1} $新增一个元项,转步骤5;
- 否则,如果$\\epsilon_{1i_1} = \\lambda $,分裂叶节点$O_{1i_1} $:选出叶节点$O_{1i_1} $中两个距离最远的元项,以这两个元项为种子,按距离远近瓜分余下元项,形成新的叶节点$O_{1i_1} $和$O_{1,i_1 + 1} $,将原叶节点$O_{1i‘} \\; (i‘ > i_1) $置为$O_{1,i‘+1} $,并更新两个新叶节点的聚类特征信息和$\\epsilon_{1i_1} $、$\\epsilon_{1,i_1+1} $数值,转步骤4;
步骤4(修缮路径上树枝):置$h‘ = h‘ + 1 $,此阶段需要修缮的节点为路径$\\tilde P $上的节点$O_{h‘i_{h‘}} $(如果$h‘=H $,此时需要修缮的节点为根节点$O_{h‘i_{h‘}}=O_{H1} $,不在路径$\\tilde P $上),根据上一个步骤的节点分裂可知,该节点中的元项$E_{h‘i_{h‘}j_{h‘}^*} $被分裂成$E_{h‘i_{h‘}j_{h‘}^*} $和$E_{h‘,i_{h‘},j_{h‘}^*+1} $两个元项,其它元项依次更改下标值,更新元项聚类特征信息及$\\epsilon_{h‘i_{h‘}} $的数值:
- 如果$\\epsilon_{h‘i_{h‘}} < \\beta $,即节点$O_{h‘i_{h‘}} $还有容纳更多元项的空间,对节点$O_{h‘i_{h‘}} $进行精修(见下方“修缮路径上树枝——树枝精修”步骤),转步骤5;
- 否则如果$\\epsilon_{h‘i_{h‘}} = \\beta $,参照分裂叶节点的方法分裂节点$O_{h‘i_{h‘}} $,形成新的节点$O_{h‘i_{h‘}} $和$O_{h‘,i_{h‘}+1} $,依次更改同层其它后续节点的下标值,并更新两个新节点的聚类特征信息和$\\epsilon_{h‘i_{h‘}} $、$\\epsilon_{h‘,i_{h‘}+1} $的数值:
- 如果$h‘ < H $,即$O_{h‘i_{h‘}} $非根节点,转步骤4;
- 否则如果$h‘ = H $,即$O_{h‘i_{h‘}}=O_{H1} $是根节点,上述分裂得到的新节点分别为$O_{H1} $和$O_{H2} $,为这两个节点构建父节点$O_{H+1,1} $,该节点有两个元项$E_{H+1,1,1} $和$E_{H+1,1,2} $分别指向节点$O_{H1} $和$O_{H2} $,更新两个元项的聚类特征信息,置$\\epsilon_{H+1,1} = 2 $且$H=H+1 $;如果待插入簇构成的集合为空,结束,输出CF树;否则转步骤2;
步骤5(更新路径信息):置$h‘= h‘+1 $,更新路径$\\tilde P $上元项$E_{h‘i_{h‘}j_{h‘}^*} $的聚类特征信息;
- 如果$h‘ = H $,此时路径到达根节点:
- 如果待插入簇构成的集合为空,结束,输出CF树;
- 否则转步骤2;
- 否则如果$h‘<H $,转步骤5。
考虑到偏斜数据可能对聚类精度或者CF树节点空间利用率造成影响,在步骤4中增加树枝精修步骤,以降低偏斜数据的影响,“修缮路径上树枝——树枝精修”步骤如下:
计算节点$O_{h‘i_{h‘}} $中两两元项之间的距离,找出距离最近的两个元项$E_{h‘i_{h‘}j_1} $和$E_{h‘i_{h‘}j_2} $,假设这两个元项指向的子节点分别为$O_{h‘-1,i_1} $和$O_{h‘-1,i_2} $:
- 如果最近的两个元项就是$E_{h‘i_{h‘}j_{h‘}^*} $和$E_{h‘,i_{h‘},j_{h‘}^*+1} $,结束该步骤;
- 否则,合并这两个子节点为$O_{h‘-1,i_3} $,更新$\\epsilon_{h‘-1,i_3} $的数值:
- 如果$\\epsilon_{h‘-1,i_3} \\le \\beta $,更新$O_{h‘i_{h‘}} $中元项信息及其子节点信息,结束该步骤;
- 否则再度分裂子节点$O_{h‘-1,i_3} $:根据距离最远,确定两个元项为种子,根据距离最近逐个分配余下元项,目标是分裂出的两个节点中有一个节点元项个数最少;分配完毕后更新$O_{h‘i_{h‘}} $中元项信息及其子节点信息,结束该步骤。
例 3:现有簇$C $需插入到图 1中的CF树中,假设簇$C $的聚类信息为$\\vec{CF}_{12} $,根据簇$C $的空间位置(见图 3)易知:$$ d(\\vec{CF}_{12}, \\vec{CF}_1) < d(\\vec{CF}_{12}, \\vec{CF}_2) $$$$d(\\vec{CF}_{12}, \\vec{CF}_4) < d(\\vec{CF}_{12}, \\vec{CF}_5)$$因此簇$C $插入路径为⟨节点2, 节点4⟩。在例 2中已知$\\lambda = 3 $,因此需要对分裂叶节点4;分裂后,节点2将包含3个节点,由于$\\beta = 2 $,因此需要进一步分裂节点2(图 4中节点2.1和2.2);分裂后,节点1中也将出现3个节点,因此需要分裂节点1(图 4中节点1.1和1.2),而后为节点1分裂出的2个节点添加父节点,即新的根节点(图 4中的节点7),CF树树高增加。至此簇$C $插入到CF树的过程结束,新的CF树如图 4所示。
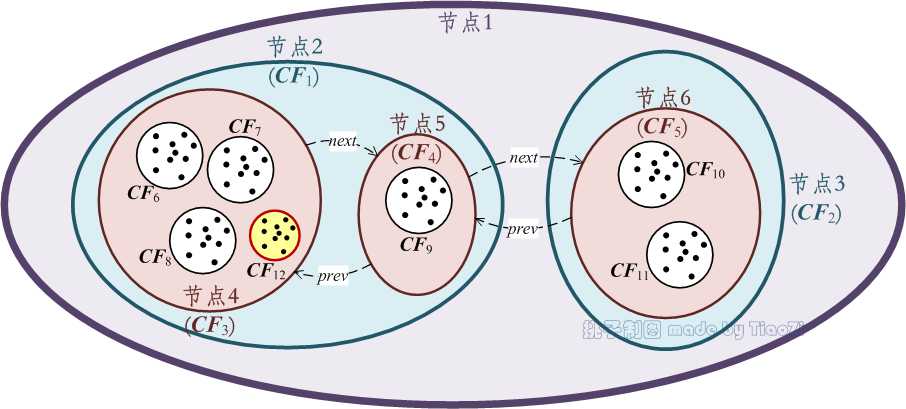
图 3:簇$C $的空间位置示意图
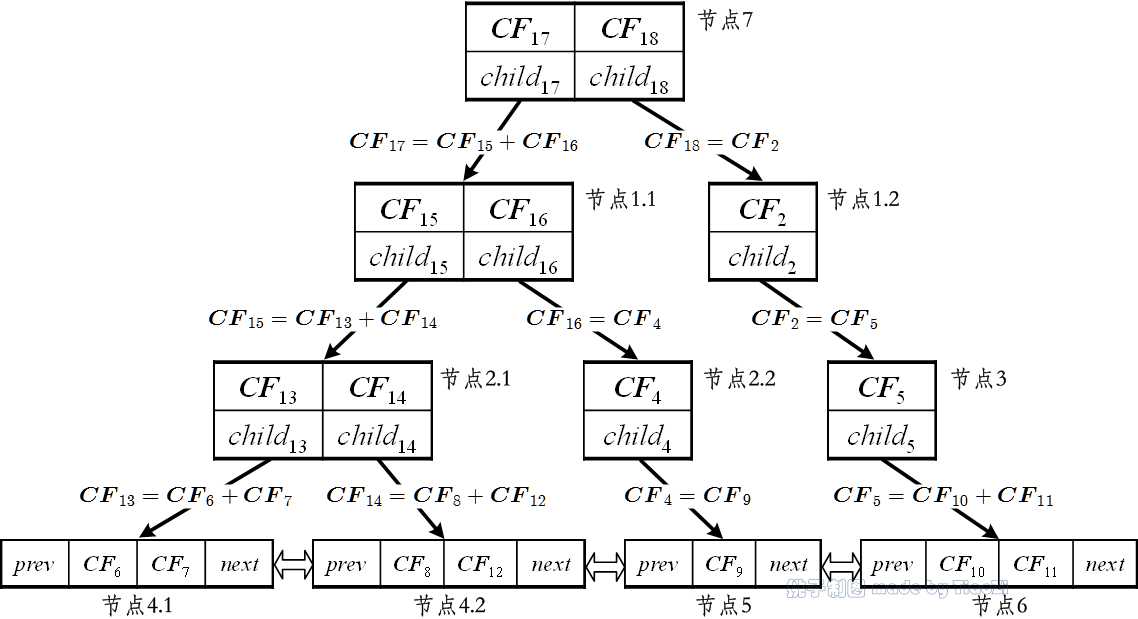
图 4:CF树的插入与修剪
当所有数据点都插入到CF树上,即CF树生长完毕后,所有叶元项对应的子簇,将作为基础的最小簇,完成后续的聚类过程。
4、CF树瘦身(Rebuilding CF tree)
BIRCH算法对CF树进行瘦身主要有两个方面的需求:1)在将数据点插入到CF树的过程中(见第3节“CF树的生长”),用于存储CF树节点及其相关信息的内存有限,导致部分数据点生长形成的CF树占满了所有内存,因此需要对CF树进行瘦身(同时增加空间阈值$\\tau $)以将余下数据点插入到CF树上;2)CF树生长完毕后,叶元项对应的子簇太小,影响到后续聚类的速度和质量,需要对CF树进行瘦身,以增加叶节点子簇的尺寸,减小叶节点子簇的数量。
CF树的瘦身是在将原空间阈值$\\tau $增加至$\\tau‘ $的基础上,将原CF树$\\mathcal T $瘦身为新的CF树$\\mathcal T‘ $,使得CF树$\\mathcal T‘ $上的节点个数小于$\\mathcal T $的节点个数,同时$\\mathcal T‘ $上叶节点的子簇尺寸上较$\\mathcal T $上的更大,数量较$\\mathcal T $上的更少。在CF树的瘦身过程中,内存将同时保存处理过程中的旧CF树$\\mathcal T $和新CF树$\\mathcal T‘ $,逐条按先后次序将旧树$\\mathcal T $上的路径搬移至新树$\\mathcal T‘ $上。在每一次的路径搬移中,需要先在新树中预留当前路径的位置$\\tilde P‘^c $,而后为旧树中的当前路径$\\tilde P^c $寻找距离最近的路径$\\tilde P‘^* $,并插入其中。在旧树$\\mathcal T $中按照路径的先后次序选择当前路径$\\tilde P^c $开始如下步骤:
1、根据路径$\\tilde P^c $在旧树$\\mathcal T $中位置,对应在新树$\\mathcal T‘ $中创建相应空节点,以便预留出路径位置,记这些空节点的路径为$\\tilde P‘^c $;
2、逐个地将路径$\\tilde P^c $中叶元项插入到新树$\\mathcal T‘ $中;对于$\\tilde P^c $中每个叶元项$E $,在新树$\\mathcal T‘ $中从上至下确定距离最近的元项(此时可确定距离最近路径$\\tilde P‘^* $),在到达$\\mathcal T‘ $的叶节点后,如果该元项$E $能够在新的空间阈值$\\tau‘ $下被某个元项吸收形成更大的簇,或者成为该叶节点的新元项,同时$\\tilde P‘^* $的次序在$\\tilde P‘^c $之前,则将元项$E $插入到$\\tilde P‘^* $的叶节点中,否则将元项$E $插入到路径$\\tilde P‘^c $的对应位置;需要明确的是,路径$\\tilde P^c $中叶元项可能有多个,这些元项在新树$\\mathcal T‘ $上的距离最近路径$\\tilde P‘^* $并不一定相同;
3、在完成路径$\\tilde P^c $中所有叶元项的转移后,$\\tilde P^c $上的节点将全部成为空节点,此外路径$\\tilde P‘^c $上也可能因为没有插入元项,会保持原来新建的空节点,因此可以删除空节点及路径,以释放空间;
4、置旧树$\\mathcal T $中下一条路径为当前路径$\\tilde P^c $,重复1~3的步骤,直至旧树$\\mathcal T $完全消失。
5、BIRCH算法流程
BIRCH算法的流程分为以下4个阶段:
1、在内存中构建CF树;
2、对第1阶段中的CF树进行瘦身(可选步骤);
3、以CF树叶元项对应的子簇为基础,实现数据点的聚类;
4、对第3阶段的聚类结果进行精修(可选步骤)。
5.1 构建CF树
本小节是BIRCH算法的第一阶段,主要任务是在设定内存的限制下,将数据库中的数据对象(数据点)逐个地插入到CF树上,当CF树构建完毕,这棵CF树将包含了数据库的所有聚类特征信息,完成数据压缩。该阶段的具体过程如下:
1、初始化枝平衡因子$\\beta $,叶平衡因子$\\lambda $和空间阈值$\\tau $;
2、在数据库$\\mathfrak D $中逐个选取数据点$\\vec x_n $,将数据点插入到CF树$\\mathcal T $上:
- 如果数据库$\\mathfrak D $中没有未被插入的数据点,对潜在离群点进行处理,确定真正的离群点(离群点处理方法可参考后文),本阶段结束,输出CF树;
- 否则,
- 如果内存溢出,增加空间阈值$\\tau $(空间阈值的设置方法见后文),并对CF树$\\mathcal T $进行瘦身操作,在瘦身之后,将CF树$\\mathcal T $中叶节点的稀疏元项作为离群点,从CF树$\\mathcal T $中暂时移至别处(离群点处理方法可参考后文),完毕后,从数据库$\\mathfrak D $选取下一个数据点,重复本步骤;
- 否则,从数据库$\\mathfrak D $选取下一个数据点,重复本步骤。
5.2 进一步瘦身CF树
首先,此阶段并非必要。该阶段的主要任务是:当第1阶段中输出的叶元项对应的簇尺寸偏小,与第3阶段中选用的聚类方法不匹配时,需要对第1阶段的输出CF树进行瘦身,以增加用以后续聚类的簇的尺寸。瘦身方法与第4节中方法无异。
5.3 二度聚类
该阶段的聚类可以直接使用现有方法,如k-means和凝聚法等,聚类的对象是第1阶段或第2阶段输出的CF树上叶元项对应的所有子簇。
假设由第1阶段或第2阶段输出的子簇共$M$个:$\\{ C_m \\}_{m=1,...,M} $,这些子簇的聚类特征都在CF树的构建中得到计算,记为$\\{ \\vec{CF}_m \\}_{m=1,...,M} $,因为聚类特征十分便于度量簇的散布度量和簇间的距离,因此可借助现有方法或者方法思想,基于聚类特征的计算,对上述$M $个子簇进行二度聚类。如选用的是凝聚法,即是逐步合并上述$M $个子簇中距离最近的2个,直到将所有子簇合并成一个大簇。
5.4 聚类精修
此阶段并非必要。该阶段的实施以第3阶段的输出簇为对象,方法十分简单:以第3阶段的输出簇的中心为种子,以距离最近为准则,重新将数据库$\\mathfrak D $中的数据点分布到相应簇中,如有必要可进一步识别和剔除离群点。
6、空间阈值的更新
在将数据库中数据点插入到CF树的过程中,一般会给一个较小的空间阈值$\\tau $,当内存溢出时,再逐步增加空间阈值$\\tau $,对CF树进行修身,再插入后续数据点。
假设当前的空间阈值是$\\tau_c $,已插入到CF树上的数据点个数为$N_c $,当前CF树的叶元项的个数为$\\epsilon_l $,根节点元项对应簇的平均半径为$\\bar r_c $.
首先大致预估下一阶段内存溢出之前插入到CF树上数据点的数量为$N_{c+1} = \\min(2N_c,N) $,其中$N $为数据库中数据点的总数。由此可计算下述值:$$ \\begin{equation} \\dot \\tau_{c+1} = \\tau_c \\cdot \\left ( \\frac{N_{c+1}}{N_{c}} \\right ) ^{\\frac{1}{D}} \\end{equation} $$
利用平均半径$\\bar r_c $与数据点数$N_c $的关系,作最小二乘线性回归估计出$\\bar r_{c+1} $的值,由此定义如下的膨胀因子(expansion factor):$$\\begin{equation} \\phi = \\max(1.0, \\frac{\\bar r_{c+1}}{\\bar r_c}) \\end{equation}$$
找出密度最高的叶节点,寻找方法可以采用贪婪法:从CF树按路径次序逐层找出包含数据点最多的节点,直至叶节点。找到密度最高叶节点后,计算该叶节点中距离最近的两个元项之间的距离$d_{\\min} $.
空间阈值更新公式如下:$$ \\begin{equation} \\tau_{c+1} = \\max \\left \\{ d_{\\min}, \\phi \\cdot \\dot \\tau_{c+1} \\right \\} \\end{equation} $$
7、离群点处理(Outlier-Handling)
BIRCH算法预留出一定空间用于潜在离群点的回收。在每次对当前CF树进行瘦身之后,需要搜索叶节点中的稀疏子簇,作为离群点放入回收空间中。此处的稀疏子簇表示簇内数据点数量远远少于所有簇平均数据点数的叶节点子簇。放入回收空间后,需要同步剔除CF树上的相关路径及节点。
当回收空间溢出时,逐个尝试将潜在离群点插入到现有CF树中,如果某个潜在离群点可以在不增加CF树节点数量的条件下被某个叶元项吸收,该潜在离群点将从回收空间中取出;否则继续留在回收空间中。
在数据库中所有数据点都被实施插入CF树的操作后,扫描所有潜在离群点,并尝试插入到CF树中,如果仍未能插入CF树中,可以确定为真正离群点,得以删除。
参考文献
[1] Zhang, T., Ramakrishnan, R., & Livny, M. (1996). BIRCH: an efficient data clustering method for very large databases. Acm Sigmod Record, 25(2), 103-114.
[2] Han, J., Kamber, M., & Pei, J. (2012). 数据挖掘:概念与技术(第3版) (范明 & 孟小峰, Trans.). 北京: 机械工业出版社.
以上是关于挑子学习笔记:BIRCH层次聚类的主要内容,如果未能解决你的问题,请参考以下文章