视觉机器学习读书笔记--------SVM方法
Posted 有梦放飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视觉机器学习读书笔记--------SVM方法相关的知识,希望对你有一定的参考价值。
SVM是一种二类分类模型,有监督的统计学习方法,能够最小化经验误差和最大化几何边缘,被称为最大间隔分类器,可用于分类和回归分析。支持向量机的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。支持向量机的学习算法是求解凸二次规划的最优化算法。
一、基本原理
SVM是一个机器学习的过程,在高维空间中寻找一个分类超*面,将不同类别的数据样本点分开,使不同类别的点之间的间隔最大,该分类超*面即为最大间隔超*面,对应的分类器称为最大间隔分类器,对于二分类问题,下图可描述SVM的空间特征。
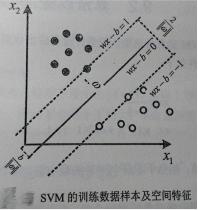
假设数据样本为x1,x2,...,xn,分类超*面可表示为:wTx-b=0.其中x为分类超*面上的点;w为垂直于分类超*面的向量;b为位移量,用于改善分类超*面的灵活性,超*面不用必须通过原点。
两个分类超*面之间具有最大间隔,需要知道训练样本中的支撑向量、距离支撑向量最*的*行超*面,这些超*面可表示为:
wTx-b=1
wTx-b=-1
其中,w是分类超*面的法向量,长度未定;1和-1只是为了计算方便而取的常量,其他常量只要互为相反数即可。
如果给定的训练样本是线性可分的,那么就可以找到两个间距最大的*行超*面,并且这两个超*面之间没有任何训练样本,它们之间的距离为2/||w||2.所以最小化||w||2,就可以使这两个超*面之间的间隔最大化。
为了使所有训练样本点在上述两个*行需要超*面间隔区域以外,我们确保所有的训练数据样本点x1,x2,...,xn都满足以下条件之一,即
wTxi-b≥1
wTxi-b≤-1
二、算法改进
假定问题的目标函数及其约束条件如下:
max(1/||w||)
s.t. yi(wTxi+b)≥1 i=1,...,n
求解1/||w||的最大值,相当于求解(1/2)||w||2的最小值,所以上述问题可以等价于如下约束不等式:
min(1/2)||w||2
s.t. yi(wTxi+b)≥1 i=1,...,n
通过将目标函数转化,求解SVM可以变成一个标准的凸优化问题(是指求取最小值的目标函数为凸函数的一类优化问题)。因为目标函数是二次的,而约束条件是线性的,所以这是一个凸二次规划问题。虽然这个问题是一个标准的二次规划问题,但同时具有它的特殊结构,通过Langrang对偶变换为对偶变量的优化问题后,可以找到一种更加有效的方法进行求解。
通过对每个约束条件加一个拉格朗日乘值,即引入拉格朗日乘子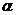 ,可以通过拉格朗日函数将约束条件融入到目标函数之中。
,可以通过拉格朗日函数将约束条件融入到目标函数之中。
L(w,b,α)=(1/2)||w||2-∑αi(yi(wTxi+b)-1)
令:θ(w)=max L(w,b,α)(αi≥0)
当某个约束条件不满足时,如:yi(wTxi+b)<1 那么有:θ(w)=∞
当所有约束条件都满足时,则:θ(w)=(1/2)||w||2 即为最初要最小化的变量。
在要求约束条件得到满足情况下最小化(1/2)||w||2,实际上等价于最小化θ(w)。因为如果约束条件没有得到满足,θ(w)就会等于无穷大,不会是所要求的最小值,则目标函数变为:
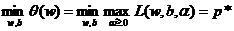
用p*表示这个问题的最优值,这个问题和最初的问题是等同的。通过把最小和最大的位置对换,可以获得:
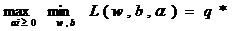
交换后不再等价于原来的问题,这个新问题的最优值用q*来表示,并且q*<p*,因为最大一个值中最小的一个比最小值中最大的要大。第二个问题的最优解q*提供第一个问题的最优解p*的一个下界,在满足某些条件的情况下,这两者相等,可以通过求解第二个问题间接求解第一个问题。
因此,可以通过先求L对w,b的极小,再求L对α的极大。之所以从最小和最大化的原始问题p*转化为最大和最小化的对偶问题q*,是因为q*是p*的*似解,转化为对偶问题后,求解过程更容易。
通常情况下,这种变换需要满足KKT条件。通常一个最优化的数学模型能够表示成如下标准形式:
min f(x)
s.t. h(x)=0, j=1,...,p
gk(x)≤0, k=1,..,q
x∈XсRn
其中,f(x)是需要最小化的函数,h(x)是等式约束,g(x)是不等式约束,p和q分别为等式约束和不等式约束的个数。
假设XсRn为一个凸集,凸函数,f:X->R为一个凸函数。凸优化就是要找出一个点x*∈X,使得每一点 x∈X满足f(x*)≤f(x).
KKT条件是一个非线性规划问题,具有最优化解法的充分必要条件。KKT条件就是指上面最优化数学模型的标准形式中的最小点x*必须满足如下条件:
hj(x)=0,j=1,...,p,gk(x)≤0,k=1,...,q
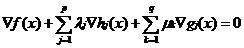
λj≠0,μk≥0,μkgk(x)=0
通过观察,这里的问题是满足KKT条件的,因此可以将其转化为求解第二个问题。也就是说,现在原问题通过满足一定条件,已经转化成它的对偶问题。
而求解这个对偶学习问题,通常可以分为三个步骤:首先要让L(w,b,α)关于w和b最小化,然后求对α的极大,最后利用SMO算法求解对偶因子。
为求解线性不可分问题,首先需要给出分类超*面的定义。对于数据点x进行分类,实际上式通过把x代入到f(x)=wTx+b算出结果,然后根据正负号进行类别划分。
由前述推导,可以知道: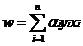
因此分类函数可以表述为:f(x)=(∑αiyixi)Tx+b=∑αiyi<xi ,x>+b
通过观察,可以看出对新点x的预测,只需要计算它与训练数据点的内积即可。这一点至关重要,是使用核函数进行非线性推广的基本前提。所有非支撑向量所对应的系数α都等于0,因此对于新点的内积计算,实际上只需要针对少量的支撑向量,而不是所有的训练数据。
假定数据是线性可分的,即可以找到一个分类超*面将两类数据完全分开。为处理非线性数据,可使用核函数方法对线性SVM进行推广。虽然通过映射φ(·)将原始数据映射到高维空间之后,能够线性分裂的概率大大增加,但是对于某些情况还是很难处理。例如并不是因为数据本身是非线性结构的,而只是因为数据有噪声。对于这种偏离正常位置很远的数据点,称之为野值点。在原来的SVM模型中,野值点的存在有可能造成很大影响,因为超*面本身就是只有少数几个支撑向量组成的。如果这些支撑向量里存在野值点,其影响就很大。
对于分类*面上的点值为0,边缘上的点值在[0,1/L]之间,其中,L为训练数据集个数,即数据集大小;对于野值点数据和内部的数据值为1/L,则原来的约束条件变为:
yi(wTxi+b)≥1-ξi ,i=1,...,n
其中,ξi≥0称为松弛变量,对应数据点xi允许偏离的量。如果允许ξi任意大的话,那任意的超*面都符合条件了。在原来的目标函数后面加上一项,使得这些ξi的加和也要最小,即:
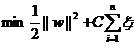
其中,C是一个参数,控制目标函数中的两项(寻找边界最大的超*面和保证数据点偏差最小)之间的权重。
ξi是需要优化的变量,而C是一个事先确定的常量。因此有:
s.t. yi(wTxi+b)≥1-ξi i=1,...,n
ξi≥0,i=1,...,n
将约束条件加入到目标函数之中,得到新的拉格朗日函数:
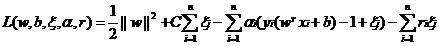
针对问题的分析方法和前面一样,在转换为另一个问题后,先使L针对w,b和ξ最小化:
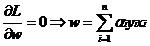
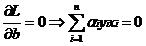
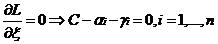
将w代回L并化简,得到和原来一样的目标函数,即:
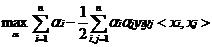
由于得到:C-αi-ɤi=0
又:ɤi≥0
作为拉格朗日乘子的条件,因此有:αi≤C
所以整个对偶问题可表示为:
s.t. 0≤αi≤C, i=1,...,n
∑αiyi=0
可以看出唯一区别就是现在对偶变量α多了一个上限C。而Kernel化的非线性形式也一样,只要把<xi,xj>换成k(xi,xj)即可,可以获得完整的处理线性和非线性、能够容忍噪声和野值点的支撑向量机。
三、实验
基于内容的图像检索中,关联反馈机制能够提高检索性能。首先用结果户标记一些相关的检索作为正样本和一些不相关的结果作为负样本,然后图像检索系统基于这些反馈样本更新检索结果;接着上述两个步骤交替执行,可以逐渐学习用户需求,增强检索性能。
在关联反馈机制方面,可以通过调整各种特征维度的权重来适应用户偏好,估计正反馈样本的密度,将判别学习方法用于图像的特征选择。
基于分类方法的关联反馈机制成为图像检索领域的前沿课题,在各种二分类器中,基于SVM的关联反馈机制具有很好的泛化性能,基于SVM的主动学习方法将图像空间分为两部分,其中距离分类面最远的正样本通常作为最相关的样本,距离分类面最*的样本作为最具信息量的样本。
下面详细阐述基于SVM的图像检索系统的关联反馈方法。
SVM是一种有效的二分类算法,考虑一个线性可分的二分类问题:{xi,yi}iN ,并且yi={+1,-1}.其中,xi是一个n维向量,yi是向量所属的类别信息。
SVM通过一个超*面将两类样本点进行划分,即:wTx+b=0 .其中,w是一个输入向量,x是一个自适应权重向量,b是一个偏置。SVM通过最大化几何边界2/||w||2 获得最优超*面的参数w和b,并且满足:yi(wTxi+b)≥+1
通过引入拉格朗日系数,求解对偶问题可获得:
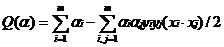
并且同时满足: αi≥0
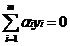
在对偶模式中,数据点仅出现内积形式。为了获得数据的更好表达,可将这些数据点通过替换操作映射到希尔伯特内积空间中:xi·xj->φ(xi)·φ(xj)=K(xi,xj).其中K(·)是一个核函数。
可以获得对偶问题的核函数表示形式:
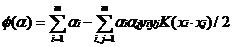
对于任意给定的核函数,SVM分类器可以表示为: F(x)=sgn(f(x)). 其中,f(x)是SVM分类超*面的决策函数:f(x)=∑i=1lαiyiK(xi,x)+b
对于给定图像样本,当|f(x)|越高时,相应的预测确信度越高。对于给定模式,当|f(x)|越低时,意味着预测确信度越低。因此SVM的输出可以作为测量给定模式与查询模式之间相似度的度量。
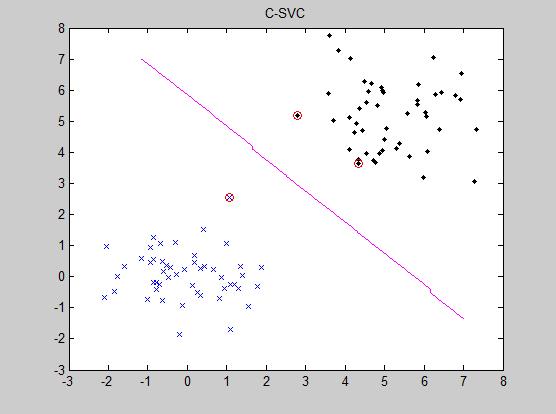
%matlab编程实现 % kernel function C = 200; %% 拉格朗日乘子上界 ker = struct(\'type\',\'linear\') %% ker - 核参数(结构体变量) % type - linear : k(x,y) = x\'*y % test sample 构造两类训练样本 n = 50; randn(\'state\',6); % \'state\'是对随机发生器的状态进行初始化,并且定义该状态初始值.用来产生该相同的随机数 x1 = randn(2,n); % 返回一个2*n的随机项矩阵,满足正态分布 y1 = ones(1,n); % 生成1行N列的元素为1的矩阵 x2 = 5+randn(2,n); y2 = -ones(1,n); figure(1); plot(x1(1,:),x1(2,:),\'bx\',x2(1,:),x2(2,:),\'k.\'); %以x1中第1行数据为横坐标,第2行数据为纵坐标,在坐标图中描点,每点用“蓝色x型”标记; %以x2中第1行数据为横坐标,第2行数据为纵坐标,在坐标图中描点,每点用“黑色圆点”标记; axis([-3 8 -3 8]); title(\'C-SVC\') hold on; X = [x1,x2]; % 训练样本,n×d的矩阵,n为样本个数,d为样本维数 Y = [y1,y2]; % 训练目标,n×1的矩阵,n为样本个数,值为+1或-1 % train SVM tic %tic用来保存当前时间,而后使用toc来记录程序完成时间,显示时间单位:秒 svm = svmTrain(\'svc_c\',X,Y,ker,C); t_train = toc % find sustain vector a = svm.a; epsilon = 1e-8; i_sv = find(abs(a)>epsilon); plot(X(1,i_sv),X(2,i_sv),\'ro\'); % test output [x1,x2] = meshgrid(-2:0.1:7,-2:0.1:7); [rows,cols] = size(x1); nt = rows*cols; Xt = [reshape(x1,1,nt);reshape(x2,1,nt)]; tic Yd = svmSim(svm,Xt); t_sim = toc Yd = reshape(Yd,rows,cols); contour(x1,x2,Yd,[0 0],\'m\'); hold off;
四、算法特点
非线性映射是SVM的基本理论基础,SVM采用内积核函数代替样本内积向高维空间的非线性映射;获得在高维特征空间划分的最优超*面是SVM的最终目标,最大化分类超*面的思想是SVM的核心。
支撑向量是训练SVM过程中获得的在分类超*面上的样本点,在SVM对测试样本的分类决策中起决定作用;支撑向量是一种有着坚实理论基础的小样本学习方法。SVM的决策函数由少数几个支撑向量来确定,它的计算复杂性取决于支撑向量的数目,而不是样本空间的维数,避免了常规学习方法的“维数灾难”。在SVM方法中,通常少数支撑向量就可以决定最终结果,这样不但可以抓住关键样本、“剔除”大量冗余样本,而且使得该方法不但运算简单,而且具有较好的鲁棒性,这是由于增加或者啥暗处非支撑向量样本对模型没有影响,而支撑向量样本集具有一定的鲁棒性。
SVM对大规模训练数据样本难以进行分类操作,这是由于SVM借助二次规划来求解支撑向量,它涉及m阶矩阵的计算,其中m为训练样本的个数,当m很大时,训练过程中矩阵存储和计算将耗费大量内存和计算代价。
经典的SVM只给出二分类算法,而在真实的数据挖掘的应用中,一般需要解决的是多分类问题。通常多分类问题可以通过构造多个二分类SVM的组合来解决,如一对多模式、一对一模式等,只要机理是构造多个SVM分类器的组合,克服SVM固有缺点,结合其他算法的优势,提高多分类问题的分类精度。
以上是关于视觉机器学习读书笔记--------SVM方法的主要内容,如果未能解决你的问题,请参考以下文章
Python深度学习:计算机视觉处理库OpenCVNumpy编辑图片高斯模糊处理(读书笔记)