霍夫丁不等式与真实的机器学习
Posted nolonely
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了霍夫丁不等式与真实的机器学习相关的知识,希望对你有一定的参考价值。
1.霍夫丁不等式
在一个罐子里,放着很多小球,他们分两种颜色{橘色,绿色}。从罐中随机抓N个小球。设:罐中橘色球的比例为μ(未知),抓出来的样本中橘色球的比例为ν(已知)。根据概率论中的霍夫丁不等式(Hoeffding’s Inequality)若N足够大,ν就很可能接近μ。
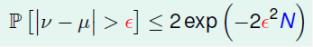
同理的,在机器学习中:N足够大的时候可以用数据集D上的 [h(x)≠f(x)] 来推测{χ}上的 [h(x)≠f(x)]。就是说,如果样本足够大,那么备选函数h在D上犯错误的比例接近其在{χ}上犯错误的比例。设某一备选函数h在D上的犯错比例为E-in(h),在整个输入集上的犯错比例为E-out(h),则有:
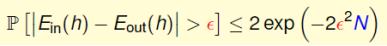
通过上式,可以根据备选函数h在D上的表现来衡量它的正确性,并最终从备选函数集H中选出最优的那个h作为g,且g≈f。
2.真实的机器学习
先举一个例子,150个人每人抛一个硬币5次,至少有一个人5次皆为人头向上的概率为1 - (31/32)^150 = 99.15%所以一个小概率事件如果重复多次,他发生的概率就会变得很大。
同理,如下情形是有可能的:学习算法A在备选函数集H中(含有很多h)孜孜不倦地挑选着h,突然找到一个hi,发现它在D上没犯错误或只犯了很少错误,A高兴大喊:我找到g了,就是这个hi!但实际上这个hi在{χ}上却犯了很多错误(Ein(hi)与Eout(hi)差很远)。对于这个hi来说,D是一个坏样本(Bad Sample)。H中可能提取若干样本Di,{ i= 1, 2,3 . . . },对于某一个h来说,其中一些样本是Bad Sample。因为Eout big (far from f), but Ein small(correct on most examples)

对于对于任意样本D和给定的h,有
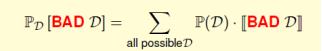
BAD data for many h
⇐⇒ no ‘freedom of choice’ by A
⇐⇒ there exists some h such thatEout(h) and Ein(h) far away
在整个备选函数集H(有M个元素)上,以下4个命题等价:
---D是H的Bad Sample ---D是某些h的Bad Sample --学习算法A不能在H中做自由筛选 ---存在某些h使得E-in(h)与E-out(h)差很远
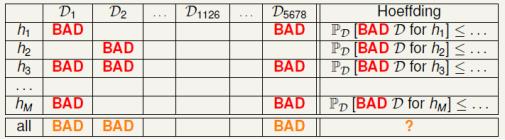
根据上表,可以看出,D-1126这样的训练数据集是比较优质的。
给定任意D,它是某些H的Bad Sample的概率为:
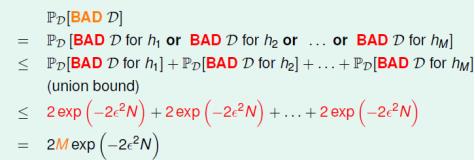
即H中备选函数的数量M越少,样本数据量N越大,则样本成为坏样本的概率越小。在一个可接受的概率水平上,学习算法A只需要挑选那个表现最好的h作为g就行了。即在上式中H的个数要求为有限个。
以上是关于霍夫丁不等式与真实的机器学习的主要内容,如果未能解决你的问题,请参考以下文章