机器为什么可以学习---一般化理论
Posted 罐装可乐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器为什么可以学习---一般化理论相关的知识,希望对你有一定的参考价值。
1、课程内容
上节课中针对hypothesis set的分类问题,我们引入了成长函数,表示在数据集D上的hypothesis set可以分成种类的最大值,希望可以使用mH(N)来替代霍夫丁不等式中的M,如果mH(N)存在一个break point使得mH(N)的成长速度很慢是否一定可以使用mH(N)来替代M?
上次课讨论了break point 的意义即:当存在break point时hypothesis set可以被分成有限类,同时说明了霍夫丁不等式在M为一个多项式级别下依然成立,因此继续讨论在存在break point的情况下,使用最小的break point作为参数K,输入数据规模为参数N,谈论在此情况下hypothesis set 的分类的极限为小于多项式的增长率,得出bound function的计算公式,B(N, K) = B(N-1, K-1) + B(N - 1, K),此时霍夫丁不等式成立,学习存在可能,最后给出了霍夫丁不等式的一般情况。
2、break point的限制
当break point的最小值在k时,可以有什么限制?

当k=2时,
输入数据个数为1时,mH(N)必然等于2,因为只有1个数据输入要shatted两个数据,那么一个必然可以shatted,因此dichotomy set的规模最大就是2;
输入数据个数为2时,根据break point的定义可以知道dichotomy set的规模必然小于22;
输入数据个数为3时,根据图形化的推导可以知道mH(N) = 4;
因此对于N>k的情况下,break point严格限制了mH(N)的最大值,此时我们不在考虑特定的hypothesis set,因为分析时并没有指出特定的hypothesis set;会不会有这样的情况出现?

3、bound function:成长函数在break point = k时, mH(N) 的最大值
bound function考虑的是:给定输入数据的规模后,按照数据规模生成O和X的向量组合,根据这2N个向量判断在给定break point的情况下判断最大的dichotomy set的最大值,这就是在给定数据规模、给定break point的情况下,hypothesis set可以被分成最大的类的数量。

这样做的好处就是,在计算bound function时并不需要考虑特定的hypothesis set,也就是说只要输入数据规模和break point一定那么无论hypothesis set是何种规模,那么其分类的最大值不会超过bound function:

现在的目标更新成:bound function 是一个多项式级别的:

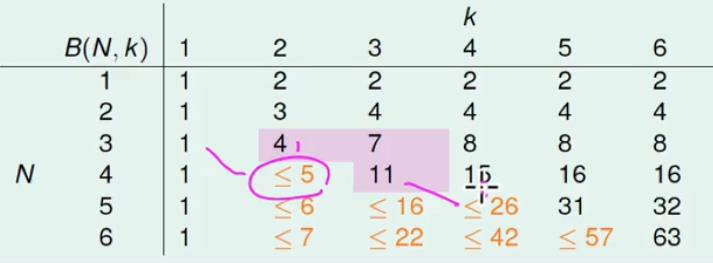
下面对boundfunction表进行填表:
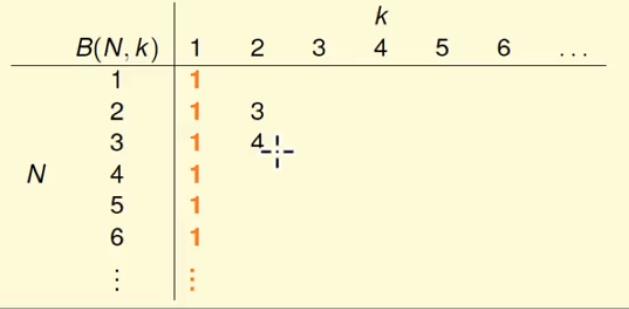
根据已知的当k = 1时,所有的数据输入bound function为1,而当N < K 时表示所有的dichotomy set 必然可以被shatter,那么bound function就是2N,依据上述已知的情况可以进行填写部分表格;
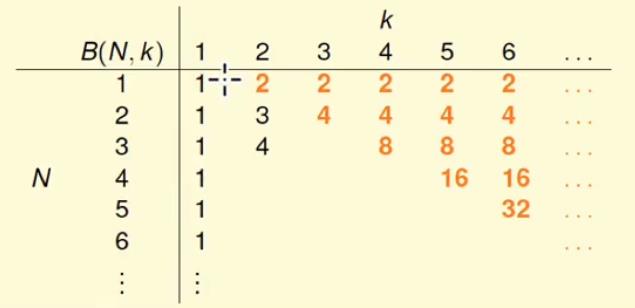
当N == k时,因为等于k时不能shatter,那么就让可以在k时的shatter的情况-1,即 2N - 1;
继续计算表格的剩余的部分,计算B(4, 3)时能不能通过B(3, x)来计算?
首先列出B(4, 3)的11个解:
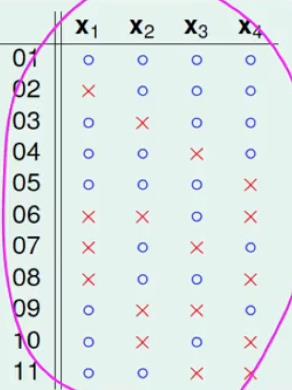
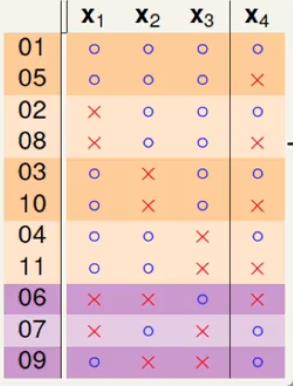
经过对解进行整理发现有8个除了x4之外,其他的数据存在相同的部分,因此可以写成:
B(4, 3) = 2α + β;
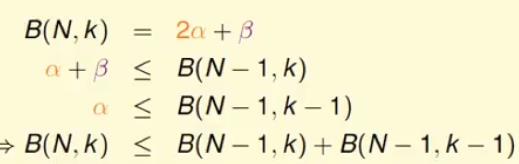
最后完整的table:
最后bound function的上限就是:
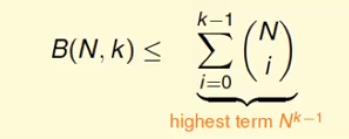
该上限的最大次项为Nk-1
5、霍夫丁不等式的一般化
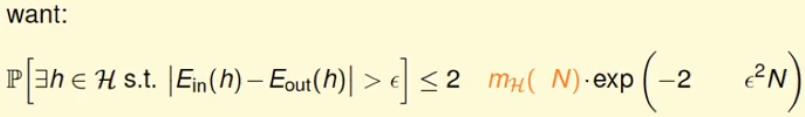
能不能直接使用已经证明了的mH(N)来替换M,不能,更一般的替代如下所示:替代条件为当N足够大时;
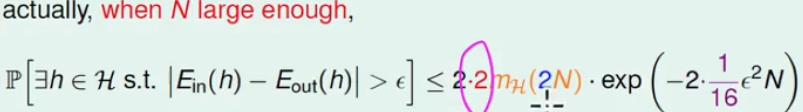
该不等式的证明不了解了。
以上是关于机器为什么可以学习---一般化理论的主要内容,如果未能解决你的问题,请参考以下文章
机器学习理论知识部分--偏差方差平衡(bias-variance tradeoff)