足球游戏论坛数据分析--简单粗暴的贝叶斯
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了足球游戏论坛数据分析--简单粗暴的贝叶斯相关的知识,希望对你有一定的参考价值。
前些日子入了PS4的某著名游戏2017, 寻小妖刷ML中. 不得不说刚开始的时候,涛哥坤哥的解说感觉颇为带感. 一个月后...还是关音量吧,解说词太贫乏了
在寻小妖的过程中, 突发奇想看看某著名论坛的数据有没有什么特别的地方,于是scrapy走起...
被服务器ban了几次后, 扒拉下来2w多主贴,30多w回帖存入sqlite数据库
[数据清洗]
使用xpath清洗html代码, 筛出板块,帖子内容,作者,时间等等等
删掉爬虫乱跑其他板块扒拉下来的帖子
这第一步清洗说起来简单, 倒也花了不少时间. 结果剩下的如下
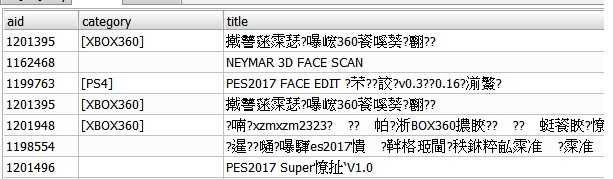
sqladmin不支持中文我也没办法 -_-!
[分析]
说实话刚拿到这些数据,我是一脸矇逼的, 当初匆匆上马scrapy, 完全没考虑到分析什么, 数据也抓得不多. 算了,看看能做什么吧, 懒得再跑爬虫,省电
首先看到, 部分帖子作者给标上了主题, 如[PS4][XBOX360], 统计一下各主机的帖子吧:
select category, count(0) from articles group by category
结果
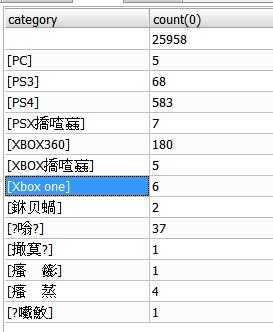
其他是什么鬼? 删了 :-(
看到大量空的category, 我上去论坛看了一下, 原来大部分作者发帖都是懒得选择主题的, 象"pes2017真的很棒一个**老粉自白"这种, 自称老粉的绝壁是PS主机用户啊.
那就尝试一下把category是空的帖子做下分类吧.
文档分类, 词语向量跑不掉, jieba分词走起


conn = sqlite3.connect(‘expData2.db‘) conn.text_factory = str rows = conn.execute(‘select * from articles ‘).fetchall() conn.close() rmvList = [‘x‘,‘y‘,‘uj‘] #移除部分无用词 f1=codecs.open(‘forum_all.txt‘,‘w‘,‘utf-8‘) j = 1 for row in rows: wList = ‘‘ words = row[2] + row[5] keys = jieba.posseg.cut(words) for k in keys: if k.flag not in rmvList: wList += ‘ ‘ + k.word f1.write(wList) f1.write(‘\\n‘) j += 1 if j%1000 ==0: print ‘Write %dk records...‘ %(j/1000) f1.close() print ‘Completed.‘
根据category,我选了200贴PS的, 180贴Xbox系列的, 人肉选了200贴讨论PC的帖子经jieba分词后, 存成txt文件作为训练集,结果如下:
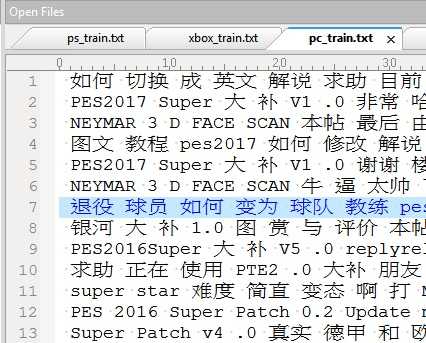
训练测试结果有9+%的准确率,有点偏高, 不管了, 先把所有数据来一发分类看看
def classNB_txt(): C, X, Y = loadDataSet() print ‘Building trainning matrix....‘ trainMat1d = [] trainMat2d = [] for postinDoc in X: ary = array(setOfWords2Vec(C, postinDoc)) trainMat2d.append(ary) print ‘Building trainning matrix completed‘ clf = GaussianNB().fit(trainMat2d, Y) f = codecs.open(‘forum_all.txt‘, ‘r‘) #fw = codecs.open(‘forum_all_result.txt‘, ‘w‘) lines = f.readlines() totalNum = len(lines) j = 1 thisDoc = [] for line in lines: ar = line.split(‘ ‘) thisDoc.append( setOfWords2Vec(C, ar)) aryDoc = np.array(thisDoc) r = clf.predict(aryDoc) f.close() print ‘Completed.‘ l = list(r) #ary = [[x] for x in l ] #print ary print ‘XB: %d‘ %(l.count(1)) print ‘PS: %d‘ % (l.count(2)) print ‘PC: %d‘ % (l.count(3))
最后结果
Building trainning matrix.... Building trainning matrix completed Completed. XB: 7223 PS: 1943 PC: 17692 Process finished with exit code 0
结果颇为意外, PS/XBox/PC三大主机的主题贴比例竟然接近1:4:9.
如果说它合理无非以下两个原因:
- 在上一代主机战争中, Xbox360是胜者. 而且关键的是, 有破解
- PC版虽然因为引擎的原因画面不如主机版,但是PC版便宜啊, 用户多啊. 而且关键的是, 有破解⊙▂⊙
不合理也是可能的:
- 准备训练数据不精准,而且并没有筛选关键词, 屏蔽stopwords
- 相当大一部分玩家在论坛上只回复不发主题, 而我只考虑了主贴,没有算回贴
- 数据太片面
综上,这个统计只能说是针对某个板块的统计。
以上是关于足球游戏论坛数据分析--简单粗暴的贝叶斯的主要内容,如果未能解决你的问题,请参考以下文章