实验 词法分析器
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实验 词法分析器相关的知识,希望对你有一定的参考价值。
实验一、词法分析实验
商业软件工程专业 姓名:张木贵 学号:201505060365
一.实验目的
通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
二、实验内容和要求
1. 根据状态转换图直接编程
编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词的二元式,形成二元式(记号)流文件输出。在此,词法分析程序作为单独的一遍,如下图所示。

具体任务有:
(1)组织源程序的输入
(2)拼出单词并查找其类别编号,形成二元式输出,得到单词流文件
(3)删除注释、空格和无用符号
(4)发现并定位词法错误,需要输出错误的位置在源程序中的第几行。将错误信息输出到屏幕上。
(5)对于普通标识符和常量,分别建立标识符表和常量表(使用线性表存储),当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则返回0并且填写符号表或常量表。
标识符表结构:变量名,类型(整型、实型、字符型),分配的数据区地址
注:词法分析阶段只填写变量名,其它部分在语法分析、语义分析、代码生成等阶段逐步填入。
常量表结构:常量名,常量值
2.能对任何S语言源程序进行分析
在运行词法分析程序时,应该用问答形式输入要被分析的S源语言程序的文件名,然后对该程序完成词法分析任务。
3.能检查并处理某些词法分析错误
词法分析程序能给出的错误信息包括:总的出错个数,每个错误所在的行号,错误的编号及错误信息。
4. 本实验要求处理以下两种错误(编号分别为1,2):
1:非法字符:单词表中不存在的字符处理为非法字符,处理方式是删除该字符,给出错误信息,“某某字符非法”。
2:源程序文件结束而注释未结束。注释格式为:/* …… */
三、实验方法、步骤及结果测试
1. 原理分析及流程图
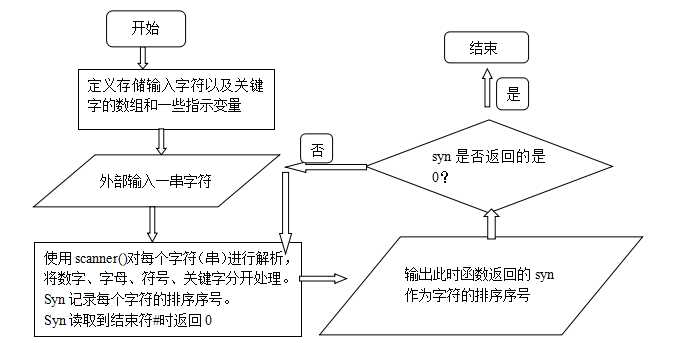
2.源代码:
public class 词法分析 { /* 初始化数据 syn为单词种别码; token为存放的单词自身字符串; sum为整型常数。 */ static String prog; static char ch; static char[]token=new char[8]; static int syn,p,m,n,sum; static //关键字表的初值 String[] rwtable={"begin","if","then","while","do","end"}; /** * @param args * @throws IOException */ public static void main(String[] args) throws IOException { //1、输入字符串 //prog="begin x:=9; if x>0 then x:=2*x+1/3;end #"; //1、从文件中读取字符串 prog=dofile.readFileByChars("src/data.txt"); //2、扫描输出 p=0; do{ scaner(); switch(syn){ case 11:System.out.print("("+syn+" , ");//单词符号:Digit digit* System.out.print(sum); System.out.println(")"); break; case -1:System.out.println("error!"); break; default: System.out.print("("); System.out.print(syn); System.out.print(" , "); String str=new String(token); System.out.print(str); System.out.println(")"); } }while(syn!=0); } //扫描程序 private static void scaner() throws IOException { // 1、初始化 for(int i=0;i<8;i++) token[i]=‘ ‘; // 2、读字母 ch=prog.charAt(p++); while(ch==‘ ‘){//如果是空格,则取下一个字符 ch=prog.charAt(p++); } // 3、开始执行扫描 // 1、是字母 // 读标识符,查保留字表 // 查到,换成属性字表,写到输出流 // 没查到, 查名表,换成属性字,写到输出流 if(ch>=‘a‘&&ch<=‘z‘){ m=0; //获取完整单词 while((ch>=‘a‘&&ch<=‘z‘)||(ch>=‘0‘&&ch<=‘9‘)){ token[m++]=ch; ch=prog.charAt(p++); } token[m++]=‘\\0‘; --p; syn=10;//单词符号为letter(letter|digit)* //判断是哪个关键字 String newStr=new String(token); newStr=newStr.trim(); //System.out.println("newStr:"+newStr); for(n=0;n<6;n++){ //System.out.println("rwtable:"+rwtable[n]); if(newStr.equals(rwtable[n])){ syn=n+1; System.out.println("syn 的值是:"+syn); break; } } token[m++]=‘\\0‘; } // 2、是数字 // 取数字,查常量表,换成属性字表,写到输出流 else if(ch>=‘0‘&&ch<=‘9‘){ while(ch>=‘0‘&&ch<=‘9‘){ sum=sum*10+ch-‘0‘; ch=prog.charAt(p++); } --p; syn=11;//digitdigit* token[m++]=‘\\0‘; } // 3、是特殊符号 // 查特殊符号表,换成属性字。写到输出流 // 4、错误error // 4、是否分析结束 // 未结束,到2 // 结束,到出口 else switch(ch){ case‘<‘: m=0; token[m++]=ch; ch=prog.charAt(p++); if(ch==‘>‘){ syn=21;//<> } else if(ch==‘=‘){ syn=22;//<= token[m++]=ch; } else{ syn=20;//< --p; } break; case‘>‘: token[m++]=ch; ch=prog.charAt(p++); if(ch==‘=‘){ syn=24;//>= } else{ syn=23;//> --p; } break; case‘:‘: token[m++]=ch; ch=prog.charAt(p++); if(ch==‘=‘){ syn=18;//:= token[m++]=ch; } else{ syn=17;//: --p; } break; case‘+‘: syn=13;token[0]=ch;token[1]=‘\\0‘;break; case‘-‘: syn=14;token[0]=ch;token[1]=‘\\0‘;break; case‘*‘: syn=15;token[0]=ch;token[1]=‘\\0‘;break; case‘/‘: syn=16;token[0]=ch;token[1]=‘\\0‘;break; case‘=‘: syn=25;token[0]=ch;token[1]=‘\\0‘;break; case‘;‘: syn=26;token[0]=ch;token[1]=‘\\0‘;break; case‘(‘: syn=27;token[0]=ch;token[1]=‘\\0‘;break; case‘)‘: syn=28;token[0]=ch;token[1]=‘\\0‘;break; case‘#‘: syn=0;token[0]=ch;token[1]=‘\\0‘;break; default: syn=-1; } File txt=new File("src/nihao.txt"); if(!txt.exists()){ txt.createNewFile(); } byte[] bytes=new byte[token.length];//定义一个长度与需要转换的char数组相同的byte数组 for(int i=0;i<bytes.length ;i++){//循环将char的每个元素转换并存放在上面定义的byte数组中 byte b=(byte)token[i];//将每个char转换成byte bytes[i]=b;//保存到数组中 } FileOutputStream fos; try { fos = new FileOutputStream(txt,true); fos.write(syn); fos.write(bytes); fos.close(); } catch (Exception e) { e.printStackTrace(); } } }
3.运行结果
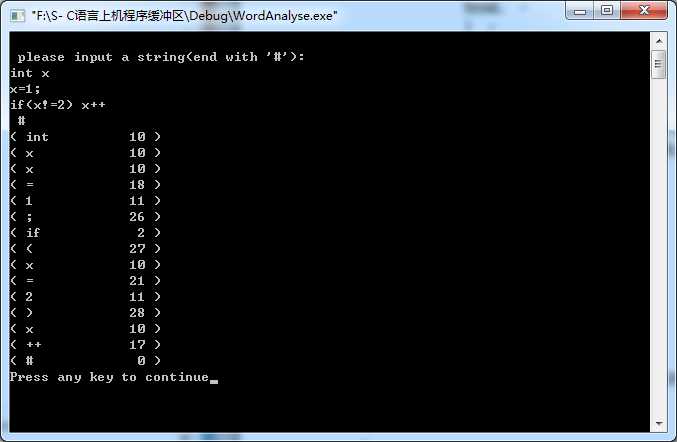
以上是关于实验 词法分析器的主要内容,如果未能解决你的问题,请参考以下文章