实验一
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实验一相关的知识,希望对你有一定的参考价值。
实验一、词法分析实验
商业软件工程专业 李润锋 201506110127
一、 实验目的
通过设计一个词法分析程序,对词法进行分析,加强对词法的理解,掌握对程序设计语言的分解和理解。
二、 实验内容和要求
在原程序中输入源代码
- 对字符串表示的源程序
- 从左到右进行扫描和分解
- 根据词法规则
- 识别出一个一个具有独立意义的单词符号
- 以供语法分析之用
- 发现词法错误,则返回出错信息
在源程序中,自动识别单词,把单词分为五种,并输出对应的单词种别码。
- 识别关键字:main if int for while do return break continue,该类的单词码为1.
- 识别标识符:表示各种名字,如变量名、数组名、函数名等,如char ch, int syn, token,sum,该类的单词码为2.
- 运算符:+、-、*、/、=、>、<、>=、<=、!=
- 分隔符:,、;、{、}、(、)
- 常数,如123,4587
各种单词符号对应的种别码。
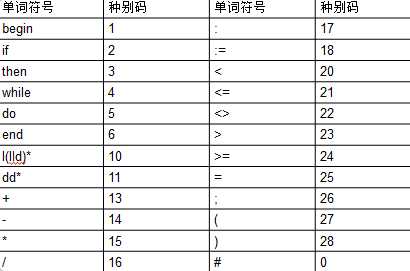
输出形式:
- 二元式
– (单词种别,单词自身的值)
- 单词种别,表明单词的种类,语法分析需要的重要信息
– 整数码
- 关键字、运算符、界符:一符一码
- 标识符:10, 常数:11
- 单词自身的值
– 标识符token、常数sum
– 关键字、运算符、界符token
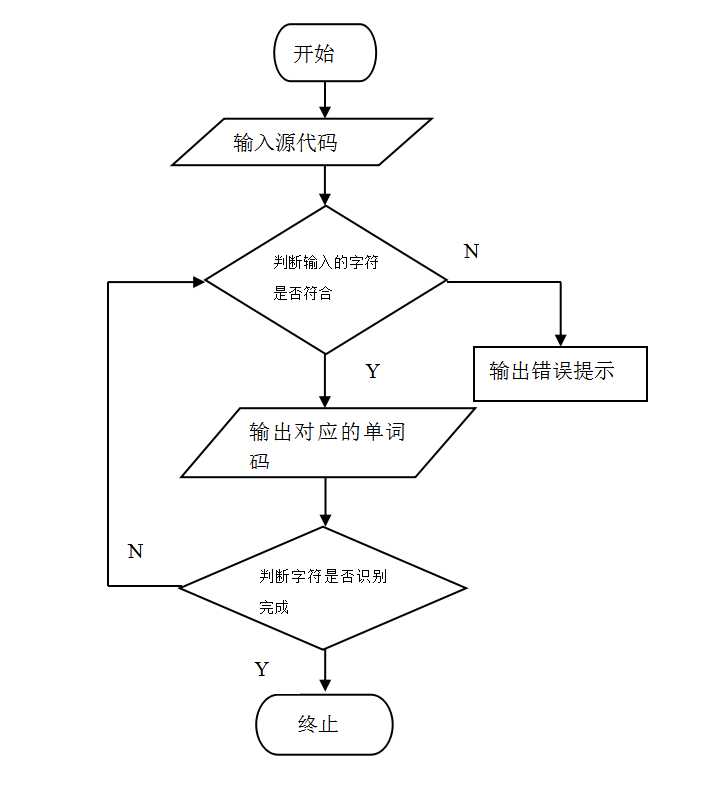
原理分析及流程图
#include <stdio.h>
#include <string.h>
char string[80],simbol[8],ch;
int wordID,index,m,n,sum;
char *rwtab[6]={"begin","if","then","while","do","end"};
void scaner(void);
main()
{
int index=0;
// printf("\\n lease inindexut a string(end with ‘#‘):\\n");
printf("Please input string (end#):");
do{
scanf("%c",&ch);
string[index++]=ch;
}while(ch!=‘#‘);
index=0;
do{
scaner();
switch(wordID)
{
case 11:
printf("( %-10d%5d )\\n",sum,wordID);
break;
case -1:
printf("you have inindexut a wrong string\\n");
//getch();
return 0;
break;
default:
printf("( %-10s%5d )\\n",simbol,wordID);
break;
}
}while(wordID!=0);
//getch();
return 0;
}
void scaner(void)
{
sum=0;
for(m=0;m<8;m++)
simbol[m++]= NULL;
ch=string[index++];
m=0;
while((ch==‘ ‘)||(ch==‘\\n‘))
ch=string[index++];
if(((ch<=‘z‘)&&(ch>=‘a‘))||((ch<=‘Z‘)&&(ch>=‘A‘)))
{
while(((ch<=‘z‘)&&(ch>=‘a‘))||((ch<=‘Z‘)&&(ch>=‘A‘))||((ch>=‘0‘)&&(ch<=‘9‘)))
{
simbol[m++]=ch;
ch=string[index++];
}
index--;
wordID=10;
for(n=0;n<6;n++)
if(strcmp(simbol,rwtab[n])==0)
{
wordID=n+1;
break;
}
}
else if((ch>=‘0‘)&&(ch<=‘9‘))
{
while((ch>=‘0‘)&&(ch<=‘9‘))
{
sum=sum*10+ch-‘0‘;
ch=string[index++];
}
index--;
wordID=11;
}
else
{
switch(ch)
{
case ‘<‘:
simbol[m++]=ch;
ch=string[index++];
if(ch==‘=‘)
{
wordID=22;
simbol[m++]=ch;
}
else
{
wordID=20;
index--;
}
break;
case ‘>‘:
simbol[m++]=ch;
ch=string[index++];
if(ch==‘=‘)
{
wordID=24;
simbol[m++]=ch;
}
else
{
wordID=23;
index--;
}
break;
case ‘+‘:
simbol[m++]=ch;
ch=string[index++];
if(ch==‘+‘)
{
wordID=17;
simbol[m++]=ch;
}
else
{
wordID=13;
index--;
}
break;
case ‘-‘:
simbol[m++]=ch;
ch=string[index++];
if(ch==‘-‘)
{
wordID=29;
simbol[m++]=ch;
}
else
{
wordID=14;
index--;
}
break;
case ‘!‘:
ch=string[index++];
if(ch==‘=‘)
{
wordID=21;
simbol[m++]=ch;
}
else
{
wordID=31;
index--;
}
break;
case ‘=‘:
simbol[m++]=ch;
ch=string[index++];
if(ch==‘=‘)
{
wordID=25;
simbol[m++]=ch;
}
else
{
wordID=18;
index--;
}
break;
case ‘*‘:
wordID=15;
simbol[m++]=ch;
break;
case ‘/‘:
wordID=16;
simbol[m++]=ch;
break;
case ‘(‘:
wordID=27;
simbol[m++]=ch;
break;
case ‘)‘:
wordID=28;
simbol[m++]=ch;
break;
case ‘{‘:
wordID=5;
simbol[m++]=ch;
break;
case ‘}‘:
wordID=6;
simbol[m++]=ch;
break;
case ‘;‘:
wordID=26;
simbol[m++]=ch;
break;
case ‘\\"‘:
wordID=30;
simbol[m++]=ch;
break;
case ‘#‘:
wordID=0;
simbol[m++]=ch;
break;
case ‘:‘:
wordID=17;
simbol[m++]=ch;
break;
default:
wordID=-1;
break;
}
}
simbol[m++]=‘\\0‘;
}