从spark架构中透视job
Posted 大数据和人工智能躺过的坑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从spark架构中透视job相关的知识,希望对你有一定的参考价值。
本博文的主要内容如下:
1、通过案例观察Spark架构
2、手动绘制Spark内部架构
3、Spark Job的逻辑视图解析
4、Spark Job的物理视图解析
1、通过案例观察Spark架构
spark-shell中,默认情况下,没有任何的Job。
从Master角度讲:
1、管理CPU、MEM等资源(也考虑网络)
2、接收Driver端提交作业的请求,并为其分配资源(APPid等)
注:spark默认是粗粒度,即spark作业提交的时候就会为我们作业分配资源,后续运行的过程中一般使用已分配的资源,除非资源发生异常需要重新分配。
从Worker角度讲:
Worker进程负责当前worker节点上的资源的使用。从分布式的节点架构讲Spark是Master/Slave分布式的,从作业的运行架构来讲主要分为Driver和众多的Worker,而从集群静态部署来讲分为Master和Worker。
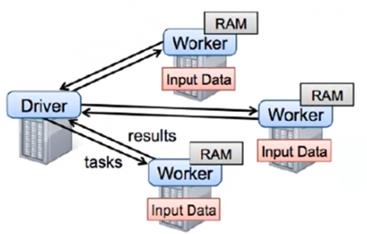
图1 Spark逻辑执行
运行作业
在spark的安装目录下的bin下, 执行 ./spark-shell --master spark://Master:7077
此时web控制台http://Master:8080,多了一个Running Applications ,该Application有Master分配的ApplicationId和由Master的分配的资源(MEM、CPU的Cores等),而分配的Cores的个数和MEM在spark.env.sh中做了配置,Spark-shell中默认情况下没有任何的job,但是在Standalone模式中默认为粗粒度的资源分配模式,提交应用程序后,Master已经进行了粗粒度的资源分配。

图2 作业运行job视图
从图2看出在作业运行的端口中可以看出Cores是32,Mem是4G是在Spark-env.sh中配置的,standalone模式spark-shell只是提交了一个程序,没有做任何事。默认情况下每个Worker上启动一个ExecutorBackend进程,一共有5个Executor。driver驱动整个应用程序的运行,一个Worker上可以配置多个ExecutorBackend进程,例如在只有一个Executor的时候,CPU利用率不高的情况,只有应用程序关闭Executor线程池才会stop。
应用程序在提交的时候会进行注册并由Master分配id和计算资源,无论一个应用程序中有多少的Action导致的作业在运行,也不会产生资源冲突的情况,因为作业运行的资源实际上是在粗粒度的方式下在程序注册的时候分配好的,多个job可以采取资源复用和排队执行的方式运行完应用程序。
默认的资源分配方式在每个Worker上启动一个ExecutorBackend进程,且默认情况下会最大的占用CPU和MEM,若不加限制,集群上除了Spark还有其他程序的话,Spark运行就会占用最大的资源,给人一种Spark很占内存的感觉,若有多套计算框架,就需要资源管理器yarn或者mesos。
- root@Worker1:~#jps
- 3920 Worker
- 3244 DataNode
- 2565 jps
- 6455 CoarseGrainedExecutorBacken
采用Client的方式提交应用程序,让driver运行在Client的机器上,也可以采用Cluster的方式提交到集群中,使用spark-shell运行程序会在Worker上多了进程CoarseGrainedExecutorBackend进程,默认情况下Worker节点为程序分配一个Executor,而CoarseGrainedExecutorBackend进程里有Executor,Executor会通过并发线程池并发执行的方式执行Task。
- scala> sc.TextFile("/library/wordCount/input/Data").flatMap(_.split("")).map(word => (word,1)).reduceByKey(_+_,1).map(pair => (pair._2 , pair._1)).sortByKey(false).map(pair = > (pair._2,pair._1)).collect
运行程序,广告点击排名,在ReduceByKey(_+_,1)进行了全局单词的排序,然后在ReduceByKey中指定并行度为1,因为只有一个作业collect,DAG如下:
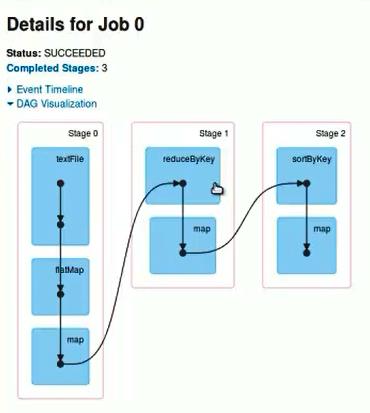
图3 DAG视图
从上面运行的job可以看出一个job产生了3个stage(数据在Stage内部是pipeline流过去的,依次是HadoopRDD、MapPartitionRDD、MapPartitionRDD、ShuffledRDD...),两个shuffledRDD,因为shuffledRDD是宽依赖(每个父RDD都被子RDD使用),因为遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入该Stage中,所以形成三个stage。

图4
从Stage中可以看出,一共有88个Task,因为这里有88个文件且每个文件大小小于HDFS默认的文件块BLOCK大小128MB,每个文件就是一个Partition,共有88个Partitions,而默认情况下一个Task对应执行一个Partition,所以就有88个Task,而每个Task都运行在Executor中,并发复用执行。每个Worker运行多少个Task,主要由于数据本地行,数据在哪尽量在哪儿排队并发运行,以此减少网络传输IO,减少通信频率。

图5
可以从图5看出一共有4个Executor,每个Worker上一个Executor进程,因为默认情况下每个Worker上启动一个Executor进程(一个CoarseGrainedExecutorBackend进程一一对应一个Executor进程,而CoarseGrainedExecutorBackend是进程级别的,Executor是计算资源级别的,因为其内部有线程池),并最大化利用当前Worker上的内存和CPU,这点前面已经提到,并且每个Executor运行不同个数的Task。
需要注意的是:一次性最多在Executor中能运行多少个并发的任务task取决于当前节点Executor中Cores数量,在实际运行的时候哪个task执行完成,就会将资源回收到线程池中进行覆用,对于一次没法全部运行的任务,就会形成task排队的情况,为了应对这种情况,优化的方法(避免oom),指定多个Executor线程池,增加分片数量,每个分片中的数据就小,所以减少OOM情况,获取更多的MEM和资源,但前提是我们的Spark运行在拥有其他大数据框架的集群中。
下面运行有Cache的情况(Cache后不同有算子,Cache后Storage中):
- scala>val cached = sc.TextFile("/library/wordCount/input/Data").flatMap(_.split("")).map(word => (word,1)).reduceByKey(_+_,1).map(pair => (pair._2 , pair._1)).cache
运行完成后产生一个新的job

图 6 Storage视图
从图6看出,由于进行了Cache操作,所以讲ShuffledRDD Cache到了内存中,且只有一个副本,因为数据不足128MB,所以只有一个Partition,对应一个Task,这里Executor在Worker2上,那么作业运行在Worker2上,充分说明了运行任务的时候基于数据本地性。
下面测试在ReduceByKey的时候,不传入第二个参数,即不指定作业运行的并行度,分别运行:
- scala>val cached = sc.TextFile("/library/wordCount/input/Data").flatMap(_.split("")).map(word => (word,1)).reduceByKey(_+_).map(pair => (pair._2 , pair._1)).cache
- scala>cached.map(pair = > (pair._2,pair._1)).collect

图7 作业运行DAG视图
从图7 反应的Stage的DAG可以看出Stage8已经kipped了,是Application内部进行的优化,查看job得知本次作业运行产生了88个并行度,即88个Partition,因为不指定并行度的话,作业会继承并行度。
注:如果我们的Spark集群只是作为唯一的计算框架,没有其他计算框架,为了应对oom,需要增加分片数量,每个分片运行的数据减小。
任务在运行前具体分配给谁主要取决于数据本地性(有些机器分配的多,也有些分配的少)!
2、手动绘制Spark内部架构
无
3、Spark Job的逻辑视图解析
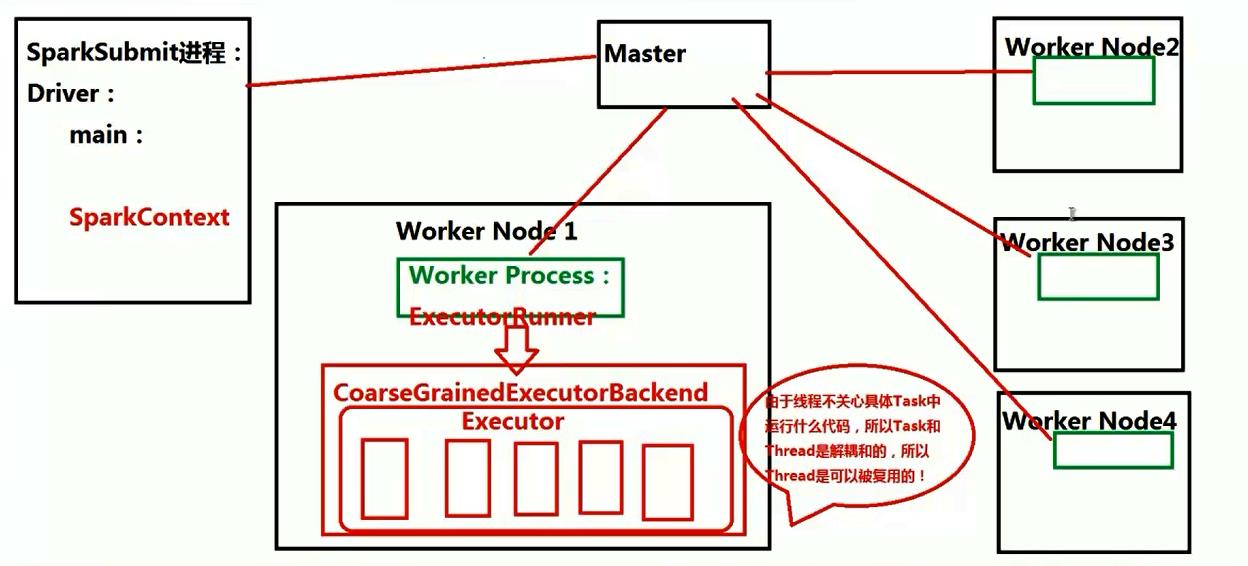
图8 Spark执行逻辑图
(Worker NODE上是Worker进程,其中有Executor Process句柄,管理当前节点上的计算资源接受Master的管理)
从总体而言,spark在集群启动的时候,有个全局的资源管理器Master,负责整个集群资源的管理以及接受程序提交并为程序分配资源,而每个Worker节点上都一个Worker process来管理当前机器上的计算资源,当应用程序提交的时候,Master就会为我们提交的应用程序在每个节点上默认分配一个CorseGrainedExecutorBackend进程,该进程默认情况下载不对MEN和CPU进行限制,会最大化的应用当前机器的MEN和CPU,当Driver实例化没有问题的时候,Driver本身会进行作业的调度来驱动CorseGrainedExecutorBackend中的Executor中的线程,来具体并发执行task,这也是Spark并发执行的过程。
而从CorseGrainedExecutorBackend的角度来看是Worker Process来管理当前节点上的MEM 和CPU,但是真正管理资源的是Master,Worker Process只是走个形式,因为我们的CorseGrainedExecutorBackend进程是被Worker Process分配的,实质上是通过Master来管理Worker节点的资源。
每个Worker上包含一个或者多个ExecutorBackend进程,而每个ExecutorBackend中包含一个Executor对象,该对象拥有一个线程池,而每个线程又可以覆用多个Task任务。
从DAG逻辑角度来看数据在Stage内部是pipeline流过去的,因为有两次ShuffledRDD,所以job被划分成3个Stage。
从Hadoop的MapReduce角度看stage0上stage1的mapper;而stage1上stage0 的mapper;stage1上stage2 的mapper;而stage2上stage1 的mapper,我们可以将Spark看做一个MapReduce的更加具体的实现。
扩充:
a)Application中由于不同的Action产生若干job;
b)每个Job中都会至少有一个Stage;
c)每个Stage内部的TaskSet一定是在Executor中执行的。
4、Spark Job的物理视图解析
无
感谢下面的博主:
http://bbs.pinggu.org/thread-4631944-1-1.html
以上是关于从spark架构中透视job的主要内容,如果未能解决你的问题,请参考以下文章
Spark IMF传奇行动第21课:从Spark架构中透视Job
第11课:Spark Streaming源码解读之Driver中的ReceiverTracker架构设计以及具体实现彻底研究