大数据架构综述计算引擎篇之Spark概述
Posted LanternTeam
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据架构综述计算引擎篇之Spark概述相关的知识,希望对你有一定的参考价值。
1. 引言
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
在大数据处理框架里,MapReduce将函数式编程思想引入了分布式数据处理中,其思想简单,使用Map 和 Reduce两个计算抽象便完成了许多大数据处理任务,但是随着大数据处理的需求越来越多,MapReduce开始显得有些力不从心。其处理流程固定,难以实现迭代计算,又因为其基于磁盘进行数据传输导致效率较低。而Spark在2012年横空出世,其抽象了一种新的称为RDD的数据结构作为基础进行数据处理,并且采用了基于内存的机制,大大提高了计算性能。下面我们来详细了解一下Spark的整体架构吧。
2. 基本概念
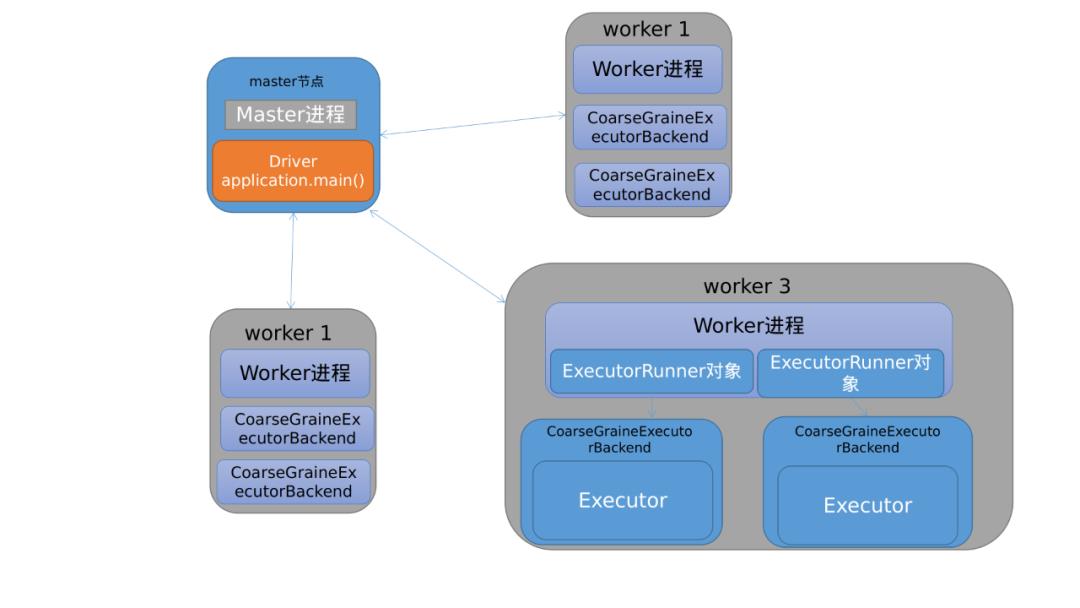
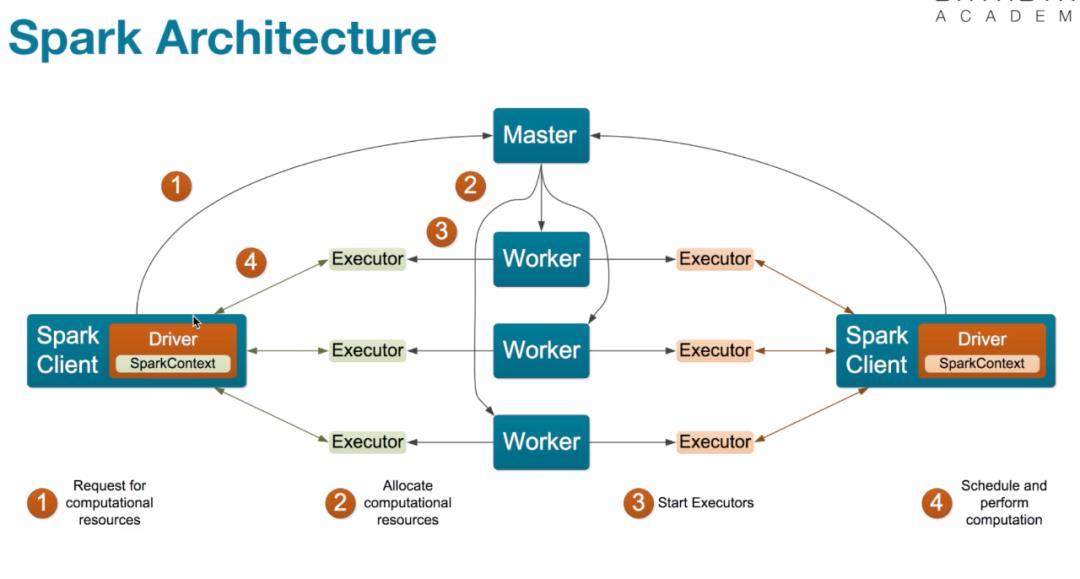
Spark和MapRedecu类似,也是采用Master-Worker结构。
Master节点运行Master进程
-
该进程负责管理全部Worker节点 -
任务分配 -
收集Worker节点信息 -
监控Worker存活状况
Worker节点运行Worker进程
-
与Master节点通信 -
负责Spark任务的执行
Spark架构中还有几个基本概念需要理解:
Driver:运行Application的main() 函数并创建SparkContext
Executor: 执行器,在worker node上执行任务组件,用于启动线程执行任务.每个Application拥有独立的一组Executors
Task:Spark应用的计算任务。Driver在运行spark应用的main()函数时,会将应用拆分为多个计算任务,然后分配给多个Executor执行,task是原子计算单位,不可拆分了。
3. 编程模型
3.1 特点
RDD(Resilient Distributed Datasets),全称是“弹性分布式数据集”。
RDD是因什么而出现的呢?在一个数据处理任务流程中,我们从数据源获得数据后,就要对数据进行操作,而后再输出,那么在这个输入/输出的过程中,中间数据应该怎么表示呢,面向对象语言的抽象方法是将数据抽象成对象,mapreduce的抽象方法是将数据抽象成键值对。但是MapReduce的处理方法过于简单,不支持一些复杂操作。
而Spark将这个中间数据抽象成了RDD,RDD中可以包括多种数据类型,整型,浮点型等
RDD的特点有:
-
只读:不能修改,只能通过转换操作生成新的 RDD。 -
分布式:可以分布在多台机器上进行并行处理。 -
弹性:计算过程中内存不够时它会和磁盘进行数据交换。 -
基于内存:可以全部或部分缓存在内存中,在多次计算间重用。
将数据抽象成RDD后,就可以对数据进行操作了,RDD 的操作分为tranformation()操作和action()操作。转化操作就是从一个 RDD 产生一个新的 RDD,而行动操作就是进行实际的计算,RDD 的操作是惰性的当 RDD 执行转化操作的时候,实际计算并没有被执行,action一般是对数据结果进行后处理,产生输出结果,触发Spark提交Job真正执行数据处理任务
3.2 依赖关系
tranformation()操作会产生新的RDD,根据不同的转换关系,RDD的血缘关系分为窄依赖和宽依赖两种。
什么是宽依赖,什么窄依赖呢?
宽依赖和窄依赖描述的是父RDD和子RDD的关系
如果新生成的child RDD中每个分区都依赖parent RDD中的一部分分区,就是窄依赖
如果新生成的child RDD中的分区依赖parent RDD中每个分区的一部分,就是宽依赖(子RDD的每个分区都要依赖于父RDD的所有分区)
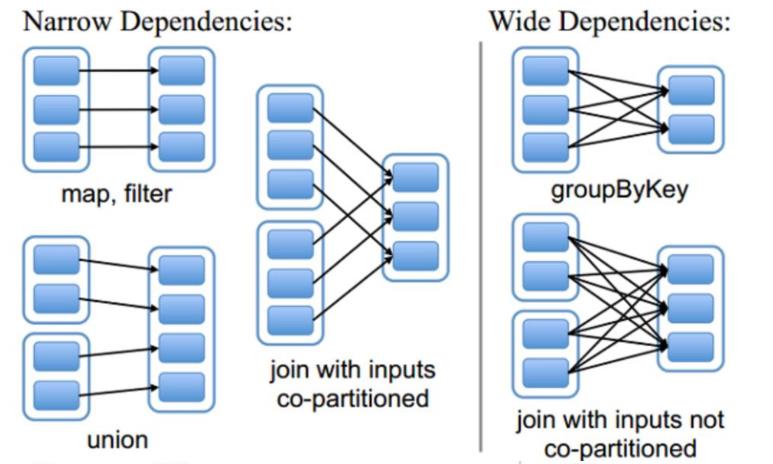
而窄依赖又可以分为四种:
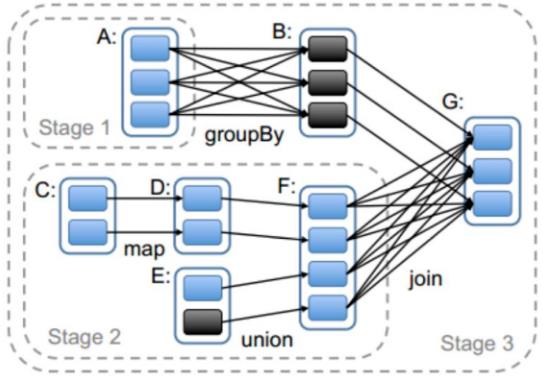
-
一对一依赖:map操作,filter操作,如上图 -
区域依赖:union操作,如上图 -
多对一依赖:join操作,如上图 -
多对多依赖:cartesian操作,child RDD中的一个分区以里parent RDD中的多个分区,同时parent RDD中的一个分区被child RDD中的多个分区依赖
那么设置不同的依赖关系具体有什么作用呢?
4. shuffle机制
4.1 Spark运行流程
讲shuffle前,先来了解一下Spark的整体运行流程
(1)构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
(2)资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
(3)SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task
(4)Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
(5)Task在Executor上运行,运行完毕释放所有资源。
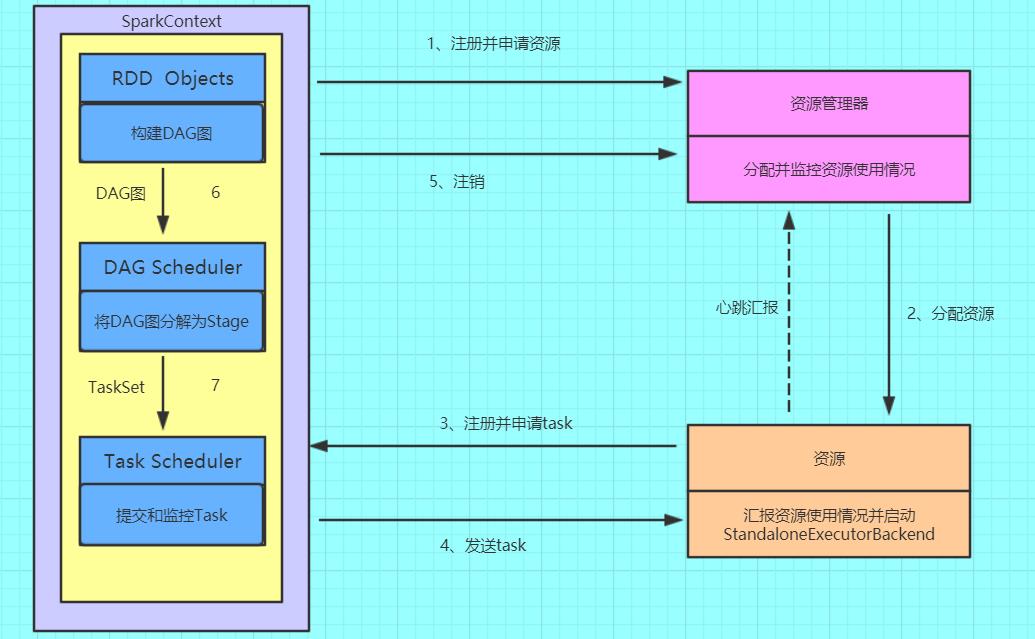
先来解释一下名词
DAG:有向无环图
DAGScheduler:根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler,其划分Stage的依据是RDD之间的依赖关系
TaskScheduler:将TaskSet提交给Worker(集群)运行,每个Executor运行什么Task就是在此处分配的。
Stage:一组并行的任务
Job:包含很多task的并行计算,可以认为是Spark RDD 里面的action,每个action的计算会生成一个job
Task:stage 下的一个任务执行单元,分为ShuffleMapTask和ResultTask
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。
现在回到shuffle上,什么是shuffle,前面讲到的依赖关系,区分两个依赖的方法还有一个就是宽依赖会产生shuffle过程,因为宽依赖的child RDD 的各个分区会依赖于parent RDD 的多个分区,所以会造成parent RDD 的各个分区在集群中重新划分。
宽依赖会划分stage,这个过程就是通过shuffle完成的,
Spark的shuffle机制也在不断的优化进步:
-
Spark 0.8及以前 Hash Based Shuffle -
Spark 0.8.1 为Hash Based Shuffle引入File Consolidation机制 -
Spark 0.9 引入ExternalAppendOnlyMap -
Spark 1.1 引入Sort Based Shuffle,但默认仍为Hash Based Shuffle -
Spark 1.2 默认的Shuffle方式改为Sort Based Shuffle -
Spark 1.4 引入Tungsten-Sort Based Shuffle -
Spark 1.6 Tungsten-sort并入Sort Based Shuffle -
Spark 2.0 Hash Based Shuffle退出历史舞台
虽然Hash Shuffle机制已经退出历史舞台,不过还是很有学习价值的,先来介绍一下它吧
4.2 Hash Shuffle
先上图
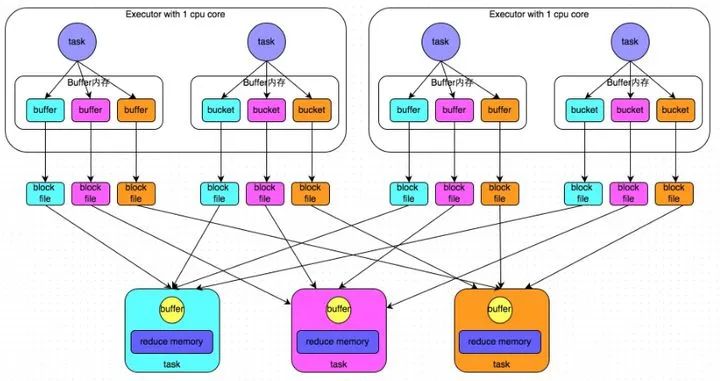
两个Executor里面分别有两个task,它们是并行的。Hash算法会根据key的分类将任务分配给不同的task,map task将不同结果写到不同的buffer中,然后写到本地磁盘,最后三个reduce task又会根据Hash算法分类,分成三个不同的类别,reducer的数据一开始是存储在内存中的。
缺点
-
Shuffle前磁盘会产生海量小文件(默认Mapper 阶段会为Reducer 阶段的每一个Task单独创建一个文件来保存该Task中要使用的数据),会产生许多低效率的IO操作(产生的小文件: Mapper 端 Task 的个数 x Reduce 端 Task 的数量) -
当数据量过大的时候,容易出现OOM问题
4.3 优化后的Hash Shuffle
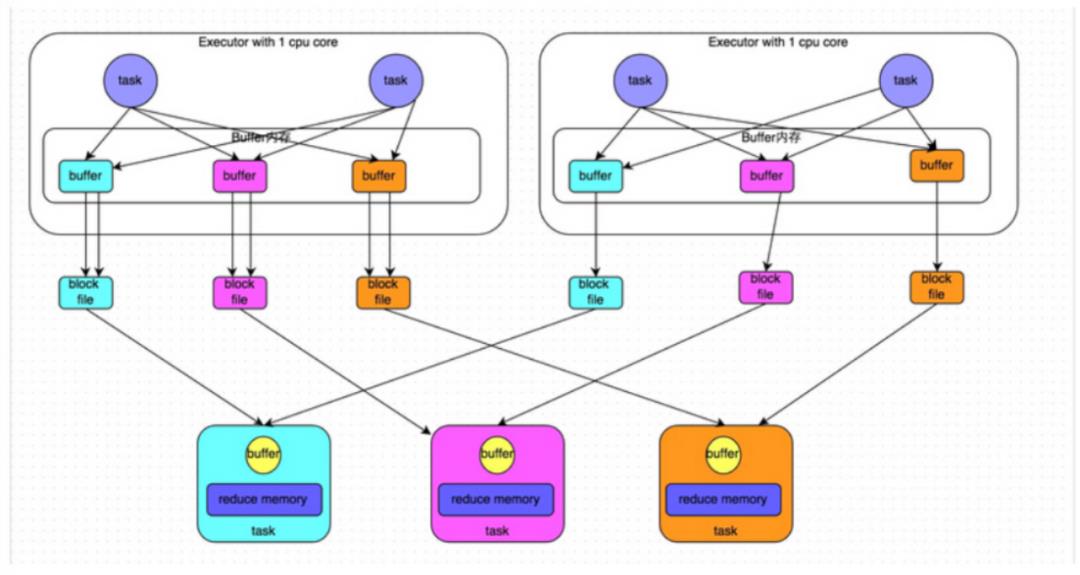
针对原始Hash的缺点,进行了一些优化。四个Task的情况,Hash根据key对任务进行分类,同key同buffer。buffer中数据,然后将buffer中的数据写入以core数量为单位的本地文件中,每1个Task所在的进程中,分别写入共同进程中的3份本地文件,上图中有4个Mapper Tasks,所以总共输出是 2个core x 3个分类文件 = 6个本地小文件。(一个core只有一种类型的key的数据))
此算法产生磁盘小文件的个数:C(core的个数)*R(reduce的个数)
4.4 SortShuffle
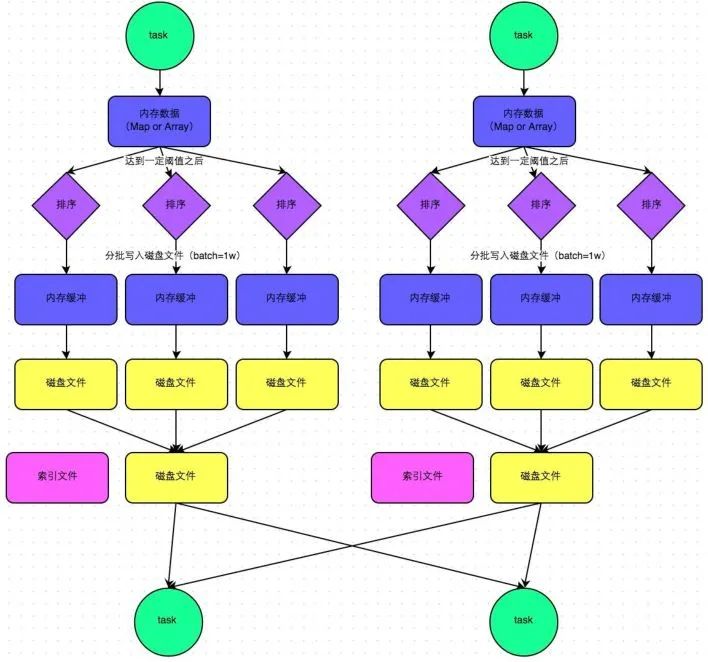
-
map task 的计算结果会写入到一个内存数据结构里面,内存数据结构默认是5M -
在shuffle的时候会有一个定时器,不定期的去估算这个内存结构的大小,当内存结构中的数据超过5M时,比如现在内存结构中的数据为5.01M,那么他会申请5.01*2-5=5.02M内存给内存数据结构。 -
如果申请成功不会进行溢写,如果申请不成功,这时候会发生溢写磁盘。 -
在溢写之前内存结构中的数据会进行排序分区 -
然后开始溢写磁盘,写磁盘是以batch的形式去写,一个batch是1万条数据 -
map task执行完成后,会将这些磁盘小文件合并成一个大的磁盘文件(有序),同时生成一个索引文件。 -
reduce task去map端拉取数据的时候,首先解析索引文件,根据索引文件再去拉取对应的数据。
4.5 bypass机制
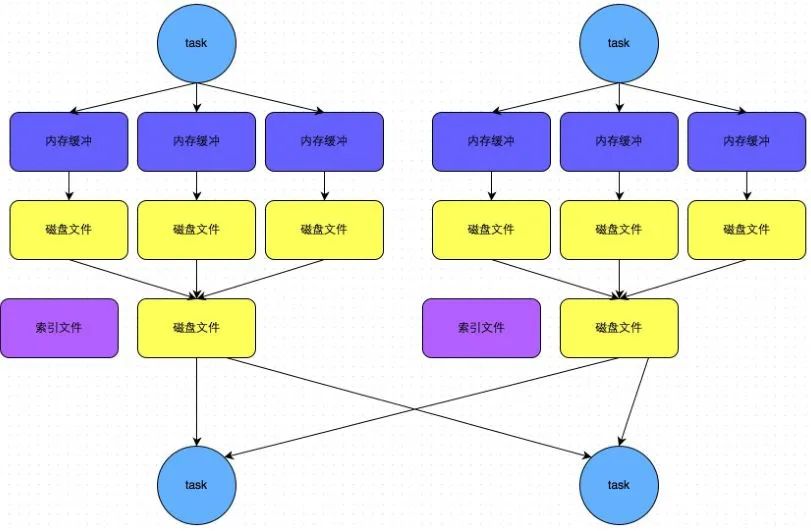
bypass运行机制的触发条件如下:
-
shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值(默认为200)。 -
不是排序类的shuffle算子(比如reduceByKey)。
bypass机制与普通SortShuffle机制的不同在于
-
磁盘写机制不同 -
不会进行排序
5. 内存管理机制
当我们讨论Spark的内存管理的时候,一般讨论的是Executor 的内存管理,Executor 的内存管理建立在 JVM 的内存管理之上,Spark的内存管理分为堆内和堆外两个部分
5.1 堆内存和堆外内存
堆内内存:JVM堆内存大小
堆外(Off-heap)内存:为了进一步优化内存的使用以及提高Shuffle时排序的效率,Spark引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间
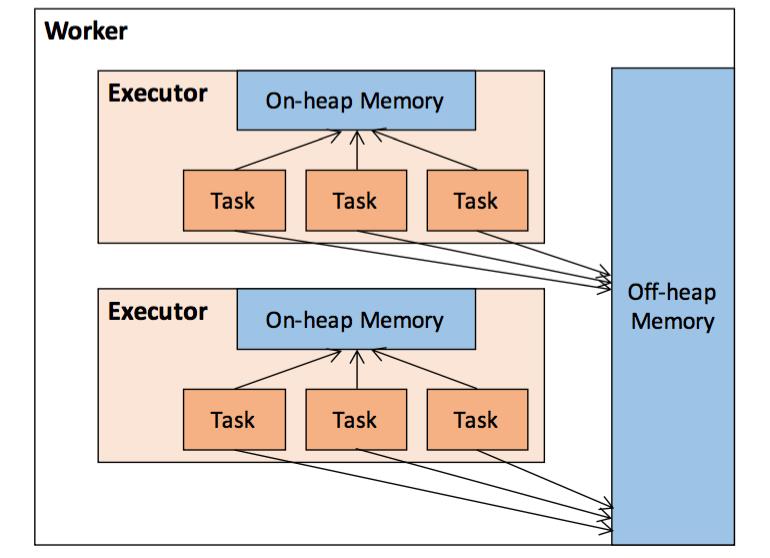
5.2 内存空间分配
Spark早期采用的是静态内存管理:
静态内存管理:用户可在启动前进行配置各个区域大小占比,但是运行过程中,各内存区间的大小均是固定的

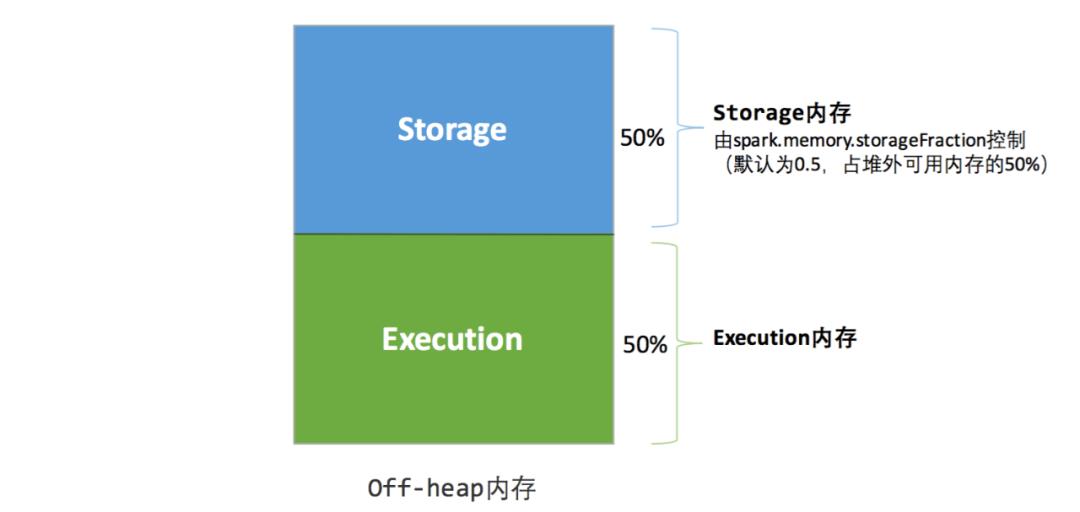
统一内存管理:与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域。
堆内:
堆外:
参考资料
[1].https://www.cnblogs.com/jcchoiling/p/6431969.html
[2].https://www.zhihu.com/search?type=content&q=Spark%20RDD%E4%BE%9D%E8%B5%96
[3].https://www.cnblogs.com/qingyunzong/p/8955141.html
以上是关于大数据架构综述计算引擎篇之Spark概述的主要内容,如果未能解决你的问题,请参考以下文章