spark:spark架构及物理执行图
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark:spark架构及物理执行图相关的知识,希望对你有一定的参考价值。
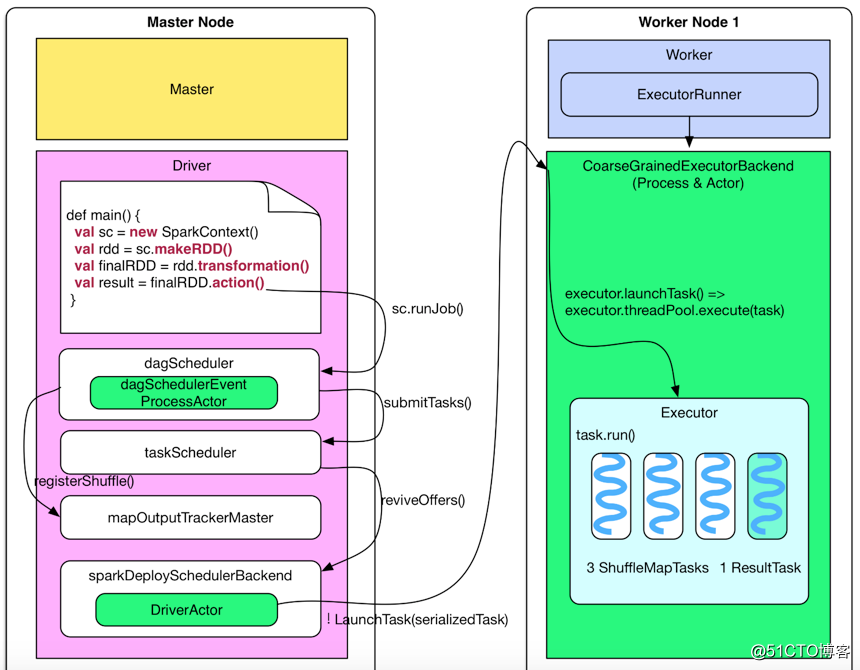
上图是一个job的提交流程图,job提交的具体步骤如下
- 一旦有action,就会触发DagScheduler.runJob来提交任务,主要是先生成逻辑执行图DAG,然后调用 finalStage = newStage() 来划分 stage。
- new Stage() 的时候会调用 finalRDD 的 getParentStages();
- getParentStages() 从 finalRDD 出发,反向 visit 逻辑执行图,遇到 NarrowDependency 就将依赖的 RDD 加入到 stage,遇到 ShuffleDependency 切开 stage,并递归到 ShuffleDepedency 依赖的 stage。
- 一个 ShuffleMapStage(不是最后形成 result 的 stage)形成后,会将该 stage 最后一个 RDD 注册到MapOutputTrackerMaster.registerShuffle(shuffleDep.shuffleId, rdd.partitions.size),这一步很重要,因为 shuffle 过程需要 MapOutputTrackerMaster 来指示 ShuffleMapTask 输出数据的位置。
- 之后是submitStage(finalStage)
- 先确定该 stage 的 missingParentStages,使用getMissingParentStages(stage)。如果 parentStages 都可能已经执行过了,那么就为空了。
- 如果 missingParentStages 不为空,那么先递归提交 missing 的 parent stages,并将自己加入到 waitingStages 里面,等到 parent stages 执行结束后,会触发提交 waitingStages 里面的 stage。
- 如果 missingParentStages 为空,说明该 stage 可以立即执行,那么就调用submitMissingTasks(stage, jobId)来生成和提交具体的 task。如果 stage 是 ShuffleMapStage,那么 new 出来与该 stage 最后一个 RDD 的 partition 数相同的 ShuffleMapTasks。如果 stage 是 ResultStage,那么 new 出来与 stage 最后一个 RDD 的 partition 个数相同的 ResultTasks。一个 stage 里面的 task 组成一个 TaskSet,最后调用taskScheduler.submitTasks(taskSet)来提交一整个 taskSet。
- taskScheduler会把task发给DriverActor进程,DriverActor序列话之后发给exector真正执行。
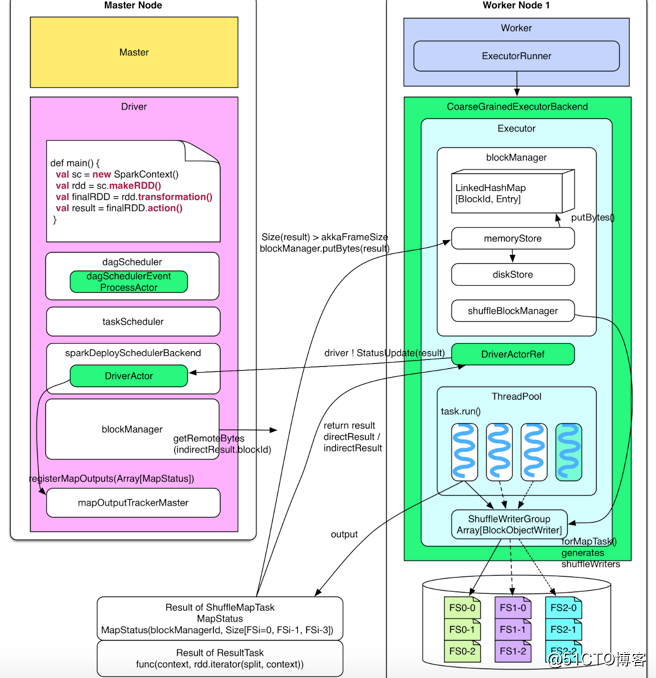
上图是task执行流程,具体执行过程如下
- Worker 端接收到 tasks 后,executor 将 task 包装成 taskRunner,并从线程池中抽取出一个空闲线程运行 task。
- Executor 收到 serialized 的 task 后,先 deserialize 出正常的 task,然后运行 task 得到其执行结果 directResult,这个结果要送回到 driver 那里。
- 如果 result 比较大(比如 groupByKey 的 result)先把 result 存放到本地的“内存+磁盘”上,由 blockManager 来管理,只把存储位置信息(indirectResult)发送给 driver。
- ShuffleMapTask 生成的是 MapStatus,MapStatus 包含两项内容:一是该 task 所在的 BlockManager 的 BlockManagerId(实际是 executorId + host, port, nettyPort),二是 task 输出的每个 FileSegment 大小。
- ResultTask 生成的 result 的是 func 在 partition 上的执行结果。**比如 count() 的 func 就是统计 partition 中 records 的个数。
- Driver 收到 task 的执行结果 result 后会进行一系列的操作:
- a,首先告诉 taskScheduler 这个 task 已经执行完,然后去分析 result。
- b,如果是 ResultTask 的 result,那么可以使用 ResultHandler 对 result 进行 driver 端的计算(比如 count() 会对所有 ResultTask 的 result 作 sum)
- c,如果 result 是 ShuffleMapTask 的 MapStatus,那么需要将 MapStatus(ShuffleMapTask 输出的 FileSegment 的位置和大小信息)存放到 mapOutputTrackerMaster 中的 mapStatuses 数据结构中以便以后 reducer shuffle 的时候查询
- d,如果 driver 收到的 task 是该 stage 中的最后一个 task,那么可以 submit 下一个 stage,如果该 stage 已经是最后一个 stage,那么告诉 dagScheduler job 已经完成
以上是关于spark:spark架构及物理执行图的主要内容,如果未能解决你的问题,请参考以下文章