机器学习技法(11)--Gradient Boosted Decision Tree
Posted cyoutetsu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习技法(11)--Gradient Boosted Decision Tree相关的知识,希望对你有一定的参考价值。

AdaBoost D Tree有了新的权重的概念。

现在的优化目标,如何进行优化呢?

不更改算法的部门,而想办法在输入的数据方面做修改。
权重的意义就是被重复取到的数据的次数。这样的话,根据权重的比例进行重复的抽样。最后的结果也和之前一样能够表达权重的意义在里面了。
在一个fully grown tree的情况下:
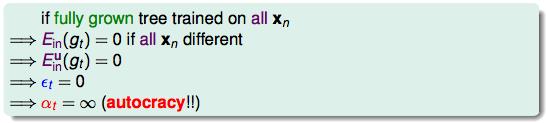
应对办法:

如果剪枝剪到极限的时候:

就是AdaBoost Stump。
在AdaBoost中:


有阴影的部分就是用来投票决定G最终结果的。这个方程式延伸一下:
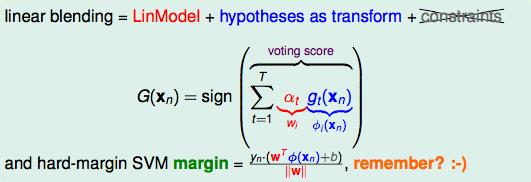
对他们这样投票的过程可以类比SVM里margin的概念。voting score也可以看成是一种距离。这个距离也是越大越好。

又成了一个最佳化的过程。
随着AdaBoost进行,这个值会越来越小。

最终想要优化的目标:
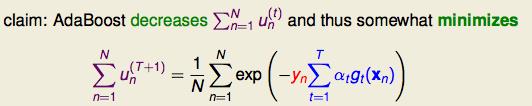
所以我们会有一个exponential error measure来对AdaBoost的上界进行bound。下面就是数学上进行优化了。
按照梯度下降的思路进行最佳化:
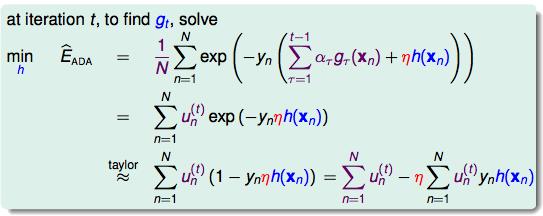

所以,在AdaBoost中的A就是好的gt了。下面就是优化步幅η了。

微分一下:

根据以上思路进行拓展:

Gradient Boost可以对任何的error function进行拓展。
拓展到regression问题的时候:
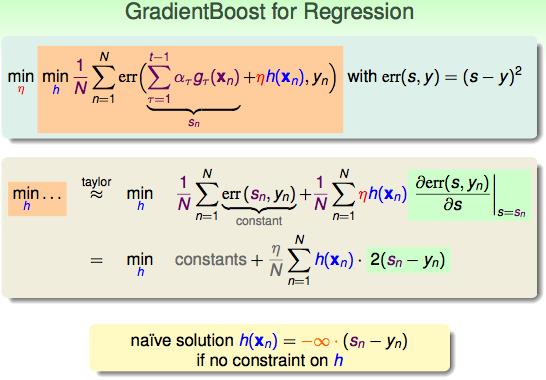
加上正则化的惩罚项:


最终得出了GBDT的形式:

最后对几个ensemble的模型进行一些总结:


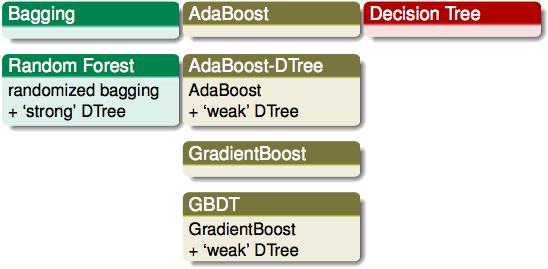
总结:

以上是关于机器学习技法(11)--Gradient Boosted Decision Tree的主要内容,如果未能解决你的问题,请参考以下文章
机器学习系列(11)_Python中Gradient Boosting Machine(GBM)调参方法详解