Python 爬虫入门(requests)
Posted lucky_pin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 爬虫入门(requests)相关的知识,希望对你有一定的参考价值。
相信最开始接触Python爬虫学习的同学最初大多使用的是urllib,urllib2。在那之后接触到了第三方库requests,requests完全能满足各种http功能,真的是好用爆了 :D
他们是这样说的:
“Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。Requests 允许你发送纯天然,植物饲养的 HTTP/1.1 请求,无需手工劳动。你不需要手动为 URL 添加查询字串,也不需要对 POST 数据进行表单编码。Keep-alive 和 HTTP 连接池的功能是 100% 自动化的,一切动力都来自于根植在 Requests 内部的 urllib3。”
-----来自官方文档(http://cn.python-requests.org/zh_CN/latest/)
敲入命令“Pip Install Requests”安装即可享用(前提是已经安装了pip)
还等什么呢?赶紧import requests加入豪华午餐吧
先看看几个常用的方法和属性:
1.requests.Session()这样就可以在会话中保留状态,保持cookie等
2.requests.get()获取某个网页,get时你可以使用params参数发送一些数据过去
d = {key1 : value1, key2 : value2 }
requests.get(‘URL’, params=d)
get时也可以使用headers参数定制请求头。
h = {key1 : value1, key2 : value2 }
requests.get(‘URL’, headers=d)
3.requests.post()发送post请求,类似的,post时也可以发送数据(使用data参数)和定制请求头(使用headers参数)。
一些常用的属性:
eg=requests.get() eg.text #可以获取响应的内容如抓回来的网页 eg. encoding=\'utf-8\' #有时回来的是乱码,改变编码以使其正常显示根据实际情况改变编码utf-8、gb2312等 eg. content #可以获取二进制内容,如抓取登陆时的验证码等非字符资源 eg.cookies #可以查看当前保存的cookie情况 eg. status_code #可以查看HTTP状态码(如200 OK、404 Not Found等) eg.url #可以查看当前请求的网址
其他详细内容参见官方文档(http://cn.python-requests.org/zh_CN/latest/)
好了,其实只要懂那么一点点就可以进行爬虫之旅了。
一个有趣的现象:童鞋们在学习爬虫时都会去爬一个叫做“教务处”的网站,哈哈。那这里的小爬虫也是以登陆本校(成都信息工程大学)的教务处作为实例
首先使用浏览器打开教务处,按F12打开“开发人员工具”,进行一次正常的登陆,对登陆的数据进行分析。
1.教务处的登陆页面为http://210.41.224.117/Login/xLogin/Login.asp
2.在开发者工具中点击网络,经查看登陆的发送post数据的地址也是http://210.41.224.117/Login/xLogin/Login.asp
3.同时看到post的数据包括如下
|
参数列表
|
||
|
表单名 |
例 |
说明 |
|
WinW |
1366 |
屏幕分辨率-宽 |
|
WinH |
728 |
屏幕分辨率-高 |
|
txtId |
2013215042 |
学号 |
|
txtMM |
123456 |
密码 |
|
verifycode |
123a |
验证码 |
|
codeKey |
597564 |
动态登陆码,html文件中可见 |
|
Login |
Check |
登陆类型(固定) |
|
IbtnEnter.x |
10 |
登陆按钮点击位置 |
|
IbtnEnter.y |
10 |
登陆按钮点击位置 |
“开发者工具”中的登陆post表单数据:
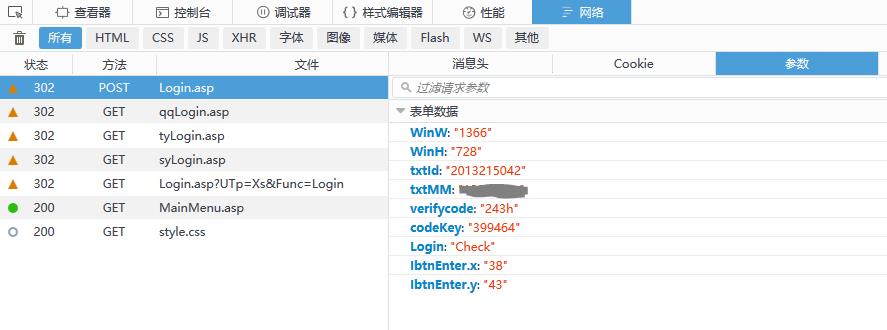
4.其中codeKey在登陆页载入时可以在页面中获得(使用正则表达式获取)。
那么思路来了:
1.get()载入登陆页
2.在载入页中获取codeKey和验证码
3.使用post()将登陆学号、密码、验证码等参数发送过去
4.登陆成功。
然而事实并不是如此顺利,经以上思路登陆之后会返回“LoginOK!”登陆成功的消息,本来是要经两个302跳转到教务处的学生主页的,但并不能顺利跳转而且哪怕手动加载学生页不行。
经再次分析发现从教务处首页点击登陆链接并不是直接链接到登陆页http://210.41.224.117/Login/xLogin/Login.asp,而是先访问http://jxgl.cuit.edu.cn/JXGL/xs/MainMenu.asp试图打开学生页失败,再经跳转到一个http://210.41.224.117/Login/qqLogin.asp?Oid=jxgl.cuit.edu.cn&OSid=*********再经这里跳转才到登陆页,其中的OSid为服务器下发分配的。实践表明我需要模仿这个过程才能顺利登陆成功。
好了,那么思路再次来了:
- get(‘http://jxgl.cuit.edu.cn/JXGL/xs/MainMenu.asp’)这里要get两次才能跳转到登陆页
- 在载入的登陆页中获取codeKey和验证码
- 使用post()将登陆学号、密码、验证码等参数发送过去
- 登陆成功,加载学生主页
要点:
- 两次get()之后得到一个跳转页面由浏览器执行javascript自动跳转,但在爬虫里需要在这个页面中找出跳转的地址手动跳转过去。使用正则表达式在javascript代码中获取需要跳转的网址,再get该网址即可。
- 获取验证码,验证码是随机生成的,得到验证码刷新地址http://210.41.224.117/Login/xLogin/yzmDvCode.asp?k=597564&t=1471855009329其中参数k为codeKey,t为时间戳加上三位随机数。那就使用前边提到eg. content可以获取二进制内容将图片保存下来再打开人工识别后输入验证码。
思考完毕,接下来就是实现了,最后的登陆代码如下:
#coding=utf-8 import requests import re import time import random from PIL import Image import cStringIO def login(username,password): headers = { #请求头请求刷新验证码和发送post时需要使用 \'Host\': \'210.41.224.117\', \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0\', \'Accept\': \'*/*\', \'Accept-Language\': \'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3\', \'Accept-Encoding\': \'gzip, deflate\', \'Referer\': \'http://210.41.224.117/Login/xLogin/Login.asp\', \'Connection\': \'keep-alive\' } session = requests.Session() step1 = session.get(\'http://jxgl.cuit.edu.cn/JXGL/xs/MainMenu.asp\') #连get两次学生主页以跳转至登陆页 step1 = session.get("http://jxgl.cuit.edu.cn/Jxgl/Xs/MainMenu.asp") get_osid_url = re.compile(r\'content="0;URL=(.*?)">\') #获取含OSid的跳转网址 osid_url = get_osid_url.findall(step1.text) step2 = session.get(osid_url[0]) #跳转,上文要点1 get_codeKey = re.compile(r\'var codeKey = \\\'(.*?)\\\';\') #在登陆页html中获取codeKey(参数k) codeKey = get_codeKey.findall(step2.text) timeKey = str(time.time())[:10] + str(random.randint(100, 999)) #生成参数t的值(时间戳+三位随机数) payload = {\'k\': codeKey[0], \'t\': timeKey} yzm_url=\'http://210.41.224.117/Login/xLogin/yzmDvCode.asp\' yzmdata = session.get(yzm_url, params=payload, headers=headers) #刷新验证码,上文要点2 tempIm = cStringIO.StringIO(yzmdata.content) im = Image.open(tempIm) im.show() yzm = raw_input(\'please enter yzm: \') #人工识别验证码后输入 post_data = { \'WinW\': \'1366\', \'WinH\': \'728\', \'txtId\': username, \'txtMM\': password, \'verifycode\': yzm, \'codeKey\': codeKey[0], \'Login\': \'Check\', \'IbtnEnter.x\': 10, \'IbtnEnter.y\': 10 } post_url=\'http://210.41.224.117/Login/xLogin/Login.asp\' step3 = session.post(post_url, data=post_data, headers=headers) #post登陆数据 return session cuitJWC=login(\'username\',\'password\') con=cuitJWC.get(\'http://jxgl.cuit.edu.cn/JXGL/xs/MainMenu.asp\') con.encoding=\'gb2312\' print con.text
以上是关于Python 爬虫入门(requests)的主要内容,如果未能解决你的问题,请参考以下文章