分析一套源代码的代码规范和风格并讨论如何改进优化代码
Posted handson
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分析一套源代码的代码规范和风格并讨论如何改进优化代码相关的知识,希望对你有一定的参考价值。
1.结合工程实践选题相关的一套源代码,根据其编程语言或项目特点,分析其在源代码目录结构、文件名/类名/函数名/变量名等命名、接口定义规范和单元测试组织形式等方面的做法和特点;
本次分析的源代码是《基于RaspberryPi的门禁系统开发》项目的源代码,该项目实现了网页端登录开锁和人脸识别开锁。


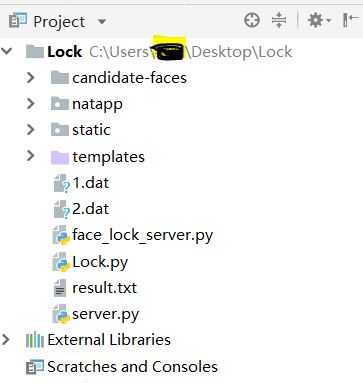
该项目的目录结构:
该项目采用python编写,文件命名规范准确,文件名Lock直观的表示了该项目与锁相关,函数名和变量名直观准确,注释完整。比如
# 加载人脸检测模块
def face_detect():
global detector
global sp
global facerec
# 1.加载正脸检测器
detector = dlib.get_frontal_face_detector()
# 2.加载人脸关键点检测器(使用68点特征提取器)
sp = dlib.shape_predictor(predictor_path)
# 3. 加载人脸识别模型
facerec = dlib.face_recognition_model_v1(face_rec_model_path)
# 对文件夹下的每一个人脸进行:
#glob.glob(pathname)返回所有匹配的文件路径列表
#os.path.join(path1,path2)连接多个路径
for f in glob.glob(os.path.join(faces_folder_path, "*.jpg")):
print("Processing file: ".format(f))
img = io.imread(f) #导入图片
# 1.人脸检测
dets = detector(img, 1) #特征提取器实例化
print("Number of faces detected: ".format(len(dets)))
for k, d in enumerate(dets):
# 2.关键点检测
shape = sp(img, d)
# 3.描述子提取,128维向量。
face_descriptor = facerec.compute_face_descriptor(img, shape)
# 转换为numpy数组
v = numpy.array(face_descriptor)
descriptors.append(v)
return descriptors
在该模块中函数名face_detect()直观的表达该模块是人脸检测模块。变量名detector代表检测器。
2.列举哪些做法符合代码规范和风格一般要求:
该代码文件名函数名准确,编码符号准确,注释完整,可读性强,容错性强,代码的简洁、清晰、无歧义。
3.列举哪些做法有悖于“代码的简洁、清晰、无歧义”的基本原则,及如何进一步优化改进;
相关代码没有建立类,没有使用好面向对象的思想,个别变量命名相似,难以辨别。
应当将相关代码组建在同一类中,变量名称应当采用驼峰式命名法,做到清晰好理解,代码的帮助文档和相关信息要补充完整,让读者能快速理解并使用。
4.总结同类编程语言或项目在代码规范和风格的一般要求。
比如java,java要求代码文件开始时,详细标注功能,作者,时间等。
- 要求函数名和变量名采用驼峰式命名。
- 要求符号和变量间隔合理,做到清晰整洁。
- 要求文件名符合文件内容
- 要求文件目录清晰合理,相关内容做到合理的分门归类。
以上是关于分析一套源代码的代码规范和风格并讨论如何改进优化代码的主要内容,如果未能解决你的问题,请参考以下文章