分析一套源代码的代码规范和风格并讨论如何改进优化代码
Posted milburn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分析一套源代码的代码规范和风格并讨论如何改进优化代码相关的知识,希望对你有一定的参考价值。
- 结合工程实践选题相关的一套源代码,根据其编程语言或项目特点,分析其在源代码目录结构、文件名/类名/函数名/变量名等命名、接口定义规范和单元测试组织形式等方面的做法和特点;
- 列举哪些做法符合代码规范和风格一般要求;
- 列举哪些做法有悖于“代码的简洁、清晰、无歧义”的基本原则,及如何进一步优化改进;
- 总结同类编程语言或项目在代码规范和风格的一般要求。
我的工程实践题目是正负新闻分类,是情感分析的拓展,接下来我分析一下相关的代码。
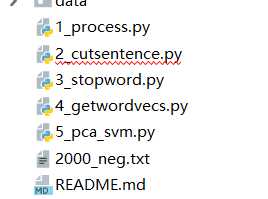
*目录结构
目录结构较为简单,一个文件夹data,顾名思义存储着数据文件(正负向语料库、分割词等)。
*文件名
文件名由5个文件名组成。可以从文件名中看出各个文件的主要内容,命名简洁清晰规范。
1_process是一个预处理过程。
2_cutsentence翻译为断句,也就是分词,实现的是逐行读取文件数据进行jieba分词,该文件包括清洗本文和文本分割。
3_stopword是对停用词的处理,主要实现的是对停用词的剔除。
4_getwordvecs是“获取文本向量”,也就是从之前的词向量模型中提取文本特征向量,返回特征词向量,构建文档词向量。
5_pca_svm是对获取到的数据进行(主成分分析)pca降维和pca作图,根据图形取100维之后,支持向量机算法。
#!/usr/bin/env python # -*- coding: utf-8 -*- #逐行读取文件数据进行jieba分词 import jieba import jieba.analyse import codecs,sys,string,re # 文本分词 def prepareData(sourceFile,targetFile): f = codecs.open(sourceFile, ‘r‘, encoding=‘utf-8‘) target = codecs.open(targetFile, ‘w‘, encoding=‘utf-8‘) print ‘open source file: ‘+ sourceFile print ‘open target file: ‘+ targetFile lineNum = 1 line = f.readline() while line: print ‘---processing ‘,lineNum,‘ article---‘ line = clearTxt(line) seg_line = sent2word(line) target.writelines(seg_line + ‘ ‘) lineNum = lineNum + 1 line = f.readline() print ‘well done.‘ f.close() target.close() # 清洗文本 def clearTxt(line): if line != ‘‘: line = line.strip() intab = "" outtab = "" trantab = string.maketrans(intab, outtab) pun_num = string.punctuation + string.digits line = line.encode(‘utf-8‘) line = line.translate(trantab,pun_num) line = line.decode("utf8") #去除文本中的英文和数字 line = re.sub("[a-zA-Z0-9]","",line) #去除文本中的中文符号和英文符号 line = re.sub("[s+.!/_,$%^*(+"‘;:“”.]+|[+——!,。??、~@#¥%……&*()]+".decode("utf8"), "",line) return line #文本切割 def sent2word(line): segList = jieba.cut(line,cut_all=False) segSentence = ‘‘ for word in segList: if word != ‘ ‘: segSentence += word + " " return segSentence.strip() if __name__ == ‘__main__‘: sourceFile = ‘2000_neg.txt‘ targetFile = ‘2000_neg_cut.txt‘ prepareData(sourceFile,targetFile) sourceFile = ‘2000_pos.txt‘ targetFile = ‘2000_pos_cut.txt‘ prepareData(sourceFile,targetFile)
*函数名
以其中一个文件的函数名为例,prepareData为预处理数据,clearText为清洗数据,sent2word为文本切割。可以看出对函数的命名依据其功能命名,且一目了然,简介易懂。
*变量名
sourceFile为源文件,targetFile为目标文件。
*代码规范
代码的缩进符合代码规范:
模块导入在文件首部。
每个缩进级别缩进4个空格。
没有tab和space的混用。
代码行的最大长度在要求之内。
不同函数组之间存在两个空行来分割函数。
类内方法定义使用一个空行分割。
每个函数有注释说明其内容。
驼峰式命名。
*有悖于“代码的简洁、清晰、无歧义”的做法
未发现
*总结同类编程语言或项目在代码规范和风格的一般要求。
一、概述
1、如无特殊情况,文件一律使用UTF-8编码,文件头部必须加 入#-*-coding:utf-8-*-标识
2、统一使用4个空格进行缩进
3、自然语言使用双引号,机器标示使用单绰号,代码里应该使用单引号,文档字符串使用三个双引号
二、空行
4、模块级函数和类定义之间空两行
5、类成员函数之间空一行
6、可以使用多个空行分隔多组相关的函数
三、语句
7、impor语句分行书写,放在文件头部,置于模块说明及docstring之后,于全局变明之前,每组之前用一个空行分隔
imort os
import sys
from too.bar impor Bar
8、导入其他模块的类定义时,可以使用相对导入
from myclass import MyClass
9、在二元运算符两边各空一格[=,-,+=,==,>,in,is not ,and]
i = i + 1
10、函数的参数列表中,,之后要有空格;默认值等号两边不要加空格
四、docstring
11、所有的公共模块、函数、类、方法都应该写docstring
五、命名规范
12、模块 尽量使用小写命名,尽量不要用下划线
13、类名着字母大写,私有类可用一个下划组开头
classs Farm();
pass
clase _PrivateFarm(Farm):
pass
14、函数名一律小写,如有多个单词,用下划线隔开;私有函数在函数前加一个下划线
15、变量名尽量用小写,如有多个单词,用下划线隔开
16、常量全用大写,如有多个韵语单词,用下划线隔开
以上是关于分析一套源代码的代码规范和风格并讨论如何改进优化代码的主要内容,如果未能解决你的问题,请参考以下文章