GlusterFS 存储
Posted flytor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GlusterFS 存储相关的知识,希望对你有一定的参考价值。
GlusterFS简介:
互联网四大开源分布式文件系统分别是:MooseFS、CEPH、Lustre、GusterFS.
GluterFS最早由Gluster公司开发,其目的是开发一个能为客户提供全局命名空间、分布式前端及高达数百PB级别扩展性的分布式文件系统。
相比其他分布式文件系统,GlusterFS具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器
的设计,让整个服务没有单点故障的隐患。
常见的分布式文件系统简介:
1、MooseFS
MooseFS主要由管理服务器(master)、元日志服务器(Metalogger)、数据存储服务器(chunkserver)构成。
管理服务器:主要作用是管理数据存储服务器,文件读写控制、空间管理及节点间的数据拷贝等。
元日志服务器:备份管理服务器的变化日志,以便管理服务器出问题时能恢复工作。
数据存储服务器:听从管理服务器调度,提供存储空间,接收或传输客户数据等。
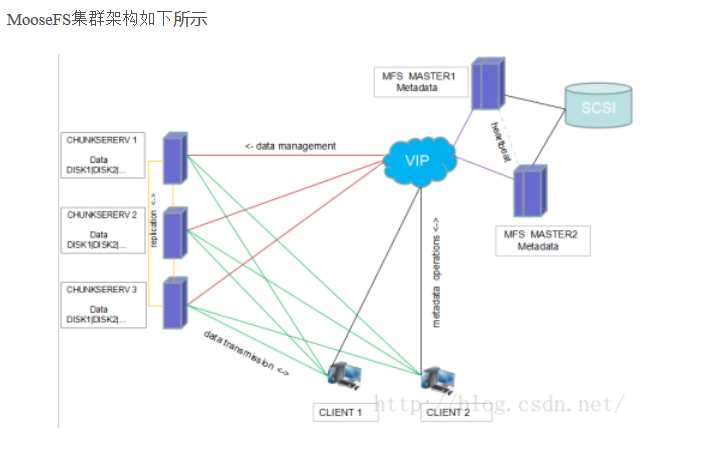
MooseFS的读过程如图所示:
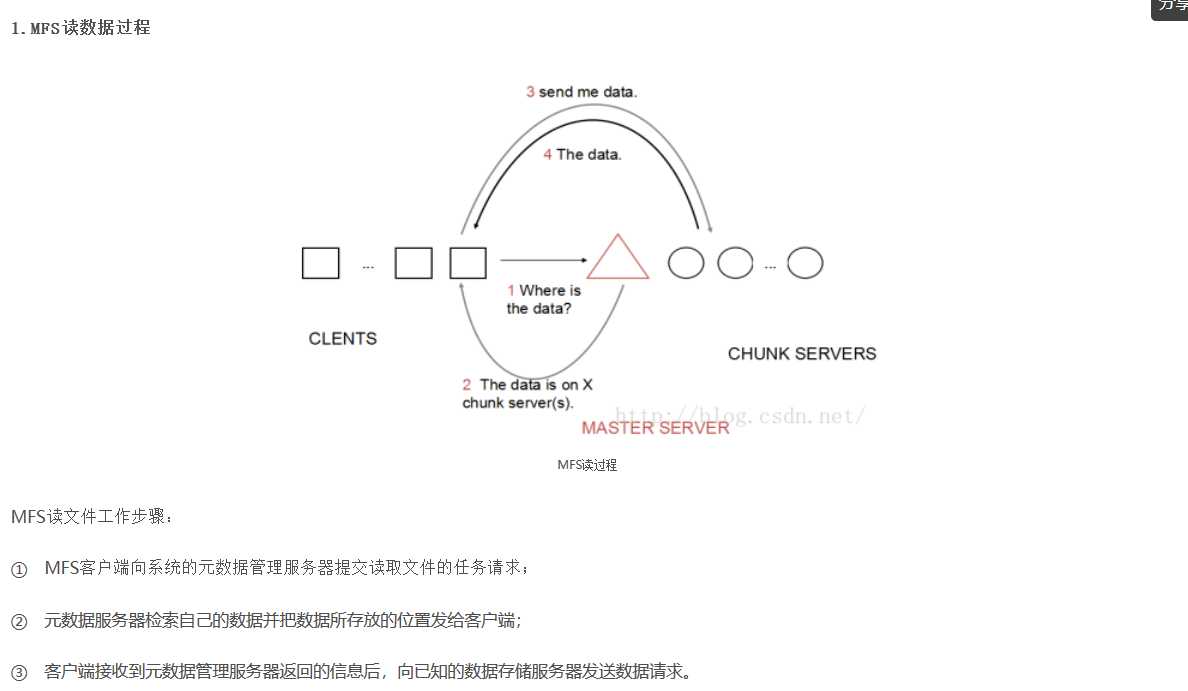
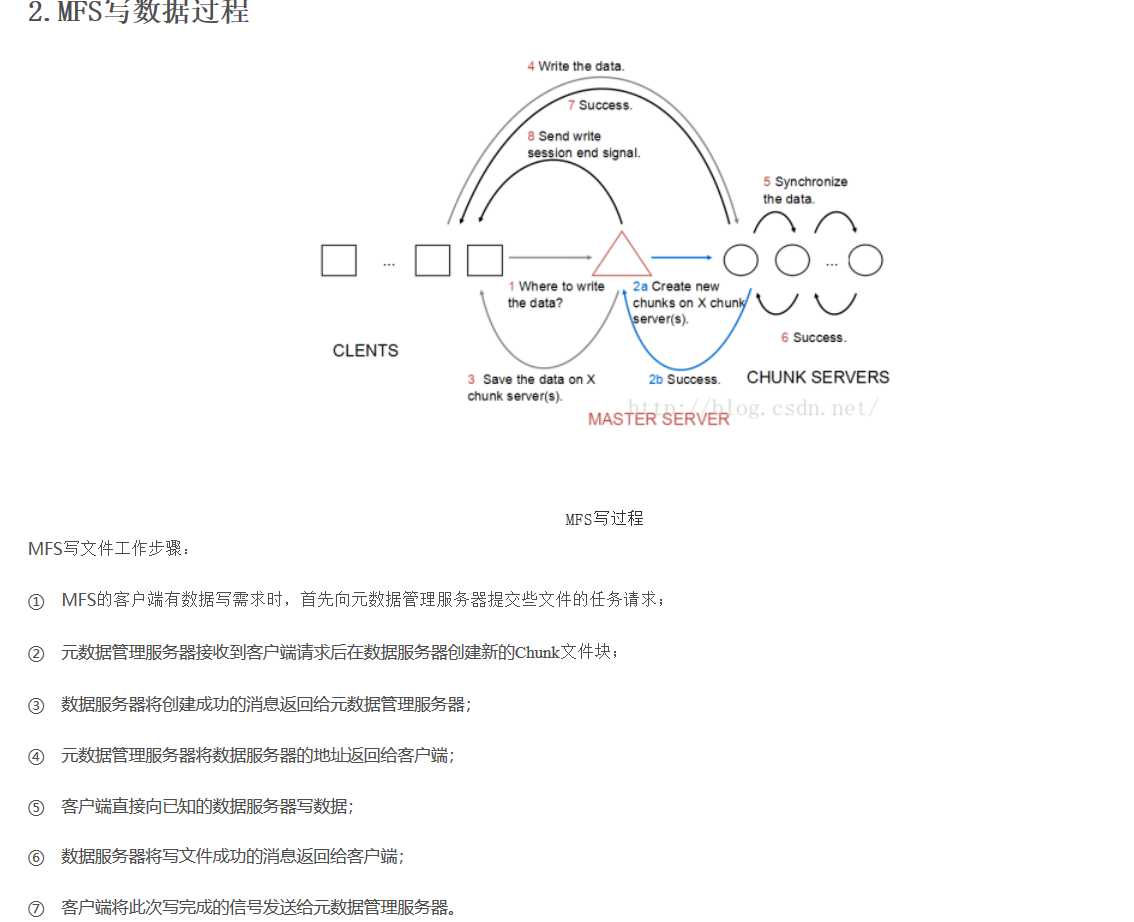
总结:MooseFS结构简单,适合初学者理解分布式文件系统的工作过程,但MooseFS具有单点故障隐患,一旦master无法工作,整个分布式文件系统
都将停止工作,因此需要实现master服务器的高可用(比如heartbeat+drbd实现)
2、Lustre
Lustre 是一个比较典型的高性能面向对象的文件系统,其结构相对比较复杂,如图所示:
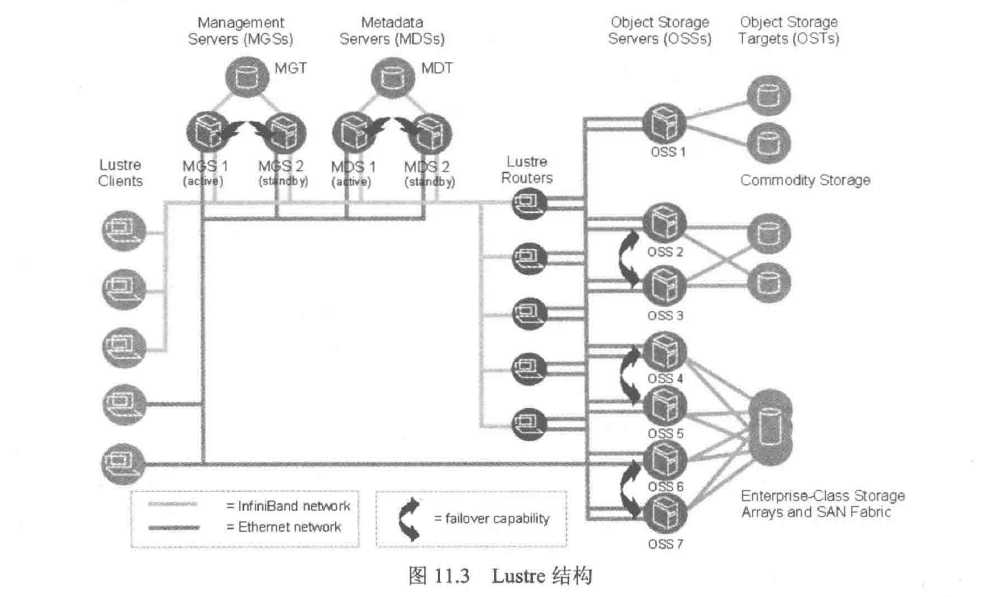
Lustre由元数据服务器(Metadata Servers,MDSs)、对象存储服务器(Object Storage Servers,OSSs)和管理服务器(Management
Servers,MGSs)组成。与MooseFS类似,当客户端读取数据时,主要集中在MDSs和OSSs间;写入数据时就需要MGS、MDSs及OSSs
共同参与操作。
总结:Lustre主要面对的是海量的数据存储,支持多达10000个节点、PB级的数据存储、100Gbit/s以上传输速度。在气象、石油等领域应用十分
广泛,是目前比较成熟的解决方案之一。
3、Ceph
请参考Ceph分布式存储篇。
二、GluserFS概述
1、无元数据设计
元数据是用来描述一个文件或给定区块在分布式文件系统中所在的位置,简而言之就是文件或某个区块存储的位置。
主要作用就是管理文件或数据区块之间的存储位置关系。
GlusterFS设计没有集中或分布式元数据,取而代之的是弹性哈希算法。集群中的任何服务器、客户端都可利用哈希算法、路径及文件名
进行计算,就可以对数据进行定位,并执行读写访问操作。
结论:无元数据设计带来的好处是极大地提高了扩展性,同时也提高了系统的性能和可靠性。如果需要列出文件或目录,性能会大幅下降,因为
列出文件或目录,需要查询所在的节点并对节点中的信息进行聚合。但是如果给定确定的文件名,查找文件位置会非常快。
2、服务器间的部署
GlusterFS集群服务器之间是对等的,每个节点服务器都掌握了集群的配置信息。所有信息都可以在本地查询。每个节点的信息更新都会
向其他节点通告,保证节点信息的一致性。但是集群规模较大后,信息同步效率会下降,非一致性概率会提高。
3、客户端访问
当客户端访问GlusterFS存储时,流程如图所示:
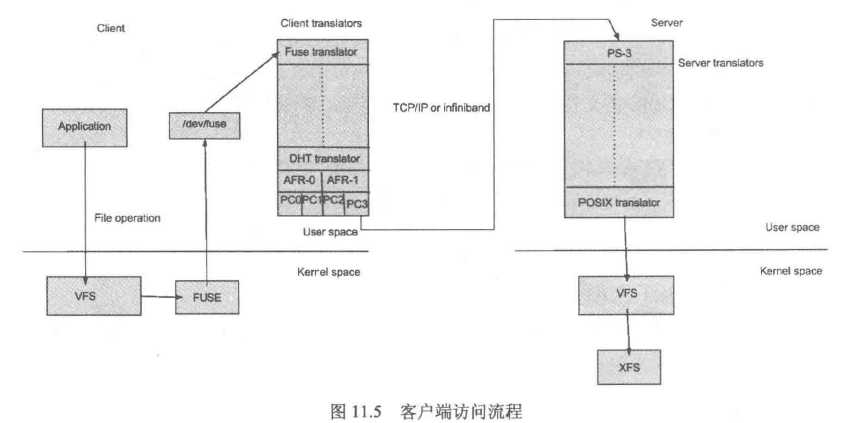
首先程序通过访问挂载点的形式读写数据,对于用户和程序而言,集群文件系统是透明的,用户和程序根本感觉不到文件系统是本地
还是远端服务器上。读写操作会被交给VFS(Virtual File System,虚拟文件系统) 来处理,VFS会将请求交给FUSE内核模块,而FUSE又会
通过设备/dev/fuse将数据交给GlusterFS Client。最后经过GlusterFS Client计算,并最终通过网络将请求或数据发送到GlusterFS Servers上。
4、可管理性
GlusterFS在提供了一套基于Web GUI的基础上,还提供了一套基于分布式体系协同合作的命令行工具,两者相结合就可以完成
GlusterFS的管理工作。
三、GlusterFS集群模式
GlusterFS集群模式是指数据在集群中的存放结构,类似于磁盘阵列中的级别。GlusterFS支持多种集群模式,具体如下:






四、集群部署:
主机环境:RHEL6.5 selinux and iptables disabled
Master:172.25.10.2 (HA) 172.25.10.3 (HA)
VIP 172.25.10.100
##Metalogger: 192.168.0.77
Chunkserver: 172.25.10.6 172.25.10.7 172.25.10.8
Client: 172.25.10.4
172.25.10.5 (iSCSI)
生成 rpm,便于部署:
# yum install gcc make rpm-build fuse-devel zlib-devel -y
# rpmbuild -tb mfs-1.6.27.tar.gz
# ls ~/rpmbuild/RPMS/x86_64
mfs-cgi-1.6.27-4.x86_64.rpm
mfs-master-1.6.27-4.x86_64.rpm
mfs-chunkserver-1.6.27-4.x86_64.rpm
元数据服务器 Master server 安装
yum install -y mfs-cgi-1.6.27-4.x86_64.rpm mfs-cgiserv-1.6.27-4.x86_64.rpm mfs-master-1.6.27-4.x86_64.rpm
# cd /etc/mfs/
# cp mfsmaster.cfg.dist mfsmaster.cfg
# cp mfsexports.cfg.dist mfsexports.cfg
# vi mfsexports.cfg
172.25.10.0/24 / rw,alldirs,maproot=0
该文件每一个条目分为三部分:
第一部分:客户端的ip地址
第二部分:被挂接的目录
第三部分:客户端拥有的权限
# cd /var/lib/mfs
# cp metadata.mfs.empty metadata.mfs
# chown -R nobody /var/lib/mfs
修改/etc/hosts文件,增加下面的行:
172.25.10.2 mfsmaster
# mfsmaster start 启动 master server
# mfscgiserv #启动 CGI 监控服务
lockfile created and locked
starting simple cgi server (host: any , port: 9425 , rootpath: /usr/share/mfscgi)
# cd /usr/share/mfscgi/
# chmod +x chart.cgi mfs.cgi
在浏览器地址栏输入 http://172.25.10.2:9425 即可查看 master的运行情况
存储服务器 Chunk servers 安装
# yum localinstall -y mfs-chunkserver-1.6.27-4.x86_64.rpm
# cd /etc/mfs
# cp mfschunkserver.cfg.dist mfschunkserver.cfg
# cp mfshdd.cfg.dist mfshdd.cfg
# vi mfshdd.cfg 定义 mfs 共享点
/mnt/mfschunks1
# chown -R nobody:nobody /mnt/mfschunks1
修改/etc/hosts 文件,增加下面的行:
172.25.10.2 mfsmaster
mkdir /var/lib/mfs
chown nobody /var/lib/mfs
现在再通过浏览器访问 http://172.25.10.2:9425/ 应该可以看见这个 MFS系统的全部信息,包括元数据管理master和存储服务chunkserver。
客户端 client安装
# yum localinstall -y mfs-client-1.6.27-4.x86_64.rpm
# cd /etc/mfs
# cp mfsmount.cfg.dist mfsmount.cfg
# vi mfsmount.cfg 定义客户端默认挂载
mfsmaster=mfsmaster
/mnt/mfs
# mfsmount
# df -h
...
mfsmaster:9421 2729728 0 2729728 0% /mnt/mfs
MFS 测试
在 MFS 挂载点下创建两个目录,并设置其文件存储份数:
# cd /mnt/mfs
# mkdir dir1 dir2
# mfssetgoal -r 2 dir2/ 设置在 dir2 中文件存储份数为两个,默认是一个
dir2/:
inodes with goal changed: 1
inodes with goal not changed: 0
inodes with permission denied: 0
对一个目录设定“goal”,此目录下的新创建文件和子目录均会继承此目录的设定,但不会改变已经存在的文件及目录的copy份数。但使用-r选项可以更改已经存在的copy份数。
拷贝同一个文件到两个目录
# cp /etc/passwd dir1 # cp /etc/passwd dir2
查看文件信息
# mfsfileinfo dir1/passwd
dir1/passwd:
chunk 0: 0000000000000001_00000001 / (id:1 ver:1)
copy 1: 172.25.10.6:9422
# mfsfileinfo dir2/passwd
dir2/passwd:
chunk 0: 0000000000000002_00000001 / (id:2 ver:1)
copy 1: 172.25.10.6:9422
copy 2: 172.25.10.7:9422
关闭 mfschunkserver2 后再查看文件信息
# mfsfileinfo dir1/passwd
dir1/passwd:
chunk 0: 0000000000000001_00000001 / (id:1 ver:1)
no valid copies !!!
# mfsfileinfo dir2/passwd
dir2/passwd:
chunk 0: 0000000000000002_00000001 / (id:2 ver:1)
copy 1: 172.25.10.7:9422
启动 mfschunkserver2 后,文件回复正常。
恢复误删文件
# rm -f dir1/passwd
# mfsgettrashtime dir1/
dir1/: 86400
文件删除后存放在“ 垃圾箱”中的时间称为隔离时间,这个时间可以用mfsgettrashtime命令来查看,用mfssettrashtime命令来设置,单位为秒,默认为86400秒。
# mkdir /mnt/mfsmeta
# mfsmount -m /mnt/mfsmeta/ -H mfsmaster
挂载 MFSMETA 文件系统,它包含目录trash (包含仍然可以被还原的删除文件的信息)和
trash/undel (用于获取文件)。把删除的文件,移到/ trash/undel 下,就可以恢复此文件。
# cd /mnt/mfsmeta/trash
# mv 00000004\\|dir1\\|passwd undel/
到 dir1 目录中可以看到passwd文件恢复
在 MFSMETA 的目录里,除了trash和trash/undel两个目录,还有第三个目录reserved,该目录内有已经删除的文件,但却被其他用户一直打开着。在用户关闭了这些被打开的文件后,reserved目录中的文件将被删除,文件的数据也将被立即删除。此目录不能进行操作。
MFS高可用部署
iSCSI 配置
增加一块虚拟磁盘,无需格式化(vdb)
yum install scsi-target-utils.x86_64 -y
vim /etc/tgt/targets.conf
#<target iqn.2016-03.com.example:server.target9>
# backing-store /dev/vdb1
# initiator-address 172.25.10.2
# initiator-address 172.25.10.3
#</target>
/etc/init.d/tgtd start && chkconfig tgtd on
在master(172.25.10.2 172.25.10.3)端下载安装 iscsi-initiator-utils.x86_64
iscsiadm -m discovery -t st -p 172.25.10.5
iscsiadm -m node -l
将磁盘格式化为ext4格式
fdisk -cu /dev/sda
mkfs.ext4 /dev/sda1
将/var/lib/mfs/* 所有数据移到网络磁盘/dev/sda1中去,然后将其挂载到/var/lib/mfs
mount /dev/sda1 /mnt/
cp -p /var/lib/mfs/* /mnt/
mfsmaster start
Pacemaker安装(172.25.10.2;3)
配yum源
默认yum源只有基础包Server,yum源包里有
ResilientStorage/
HighAvailability/
LoadBalancer/
Packages/
images/
Packages/
...
所需安装包pacemaker在HighAvailability包里
yum install pacemaker -y
使用pacemaker配置时需要安装pacemaker的接口,程序接口为crmshell,早期装上pacemaker自带有crmshell接口,新版本已被独立出来,不再是pacemaker组成部分。而crmshell又依赖于pssh相关包,因此得安装这两个组件。
# yum install crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm
使用yum install安装pacemaker时会安装其大量相关性依赖包,包括corosync,所以corosync不再安装,直接修改其配置文件/etc/corosync/corosync.conf。
cd /etc/corosync/
#cp corosync.conf.example corosync.conf
vim corosync.conf
#bindnetaddr: 172.25.10.0
#mcastaddr: 226.94.1.1
#
#service
# name: pacemaker
# ver: 0
#
/etc/init.d/corosync start && chkconfig corosync on
fence安装(1229)
本次部署采用外部fence ,fence是C/S架构,在fence服务端节点需要安装如下三个软件包。
fence-virtd.x86_64
fence-virtd-libvirt.x86_64
fence-virtd-multicast.x86_64
安装好之后使用命令fence_virtd -c进入交互式界面配置fence文件,在配置时需要注意的是选择接口(interface)时选主机之间通信的网卡。
mkdir /etc/cluster #默认不存在cluster;
服务端和客户端之间通过key文件进行通信,key文件默认不存在,需要手动生成并拷贝到所有客户端节点。节点默认没有/etc/cluster目录,需自己建立
# dd if=/dev/urandom of=/etc/cluster/fence_xvm.key
# for i in 2,3 ;do scp /etc/cluster/fence_xvm.key master$i.example.com:/etc/cluster ; done
systemctl start fence_virtd.service
systemctl enable fence_virtd.service
在客户端(172.25.10.2,3)需安装fence-virt工具
# yum install fence-virt.x86_64 -y
元数据高可用性高可用实现
之前安装好的crmshell接口提供一个命令行交互接口对pacemaker集群进行管理,具有非常强大且易用的管理功能,所做的配置会同步到各个集群节点上。下面将元数据服务器上各个服务交由集群管理。
a. 首先将fence服务交由集群。由于外部fence只能识别domain,所以需要将domain与hostname绑定,并每隔60s监控一次。
# crm(live)configure# primitive vmfence stonith:fence_xvm parms pcmk_host_map="master1.example.com:vm2;master2.example.com:vm3" op monitor interval=60s
b. 在将MFS系统服务交由集群接管之前,需建立一个虚拟IP(VIP),VIP对外为master节点,当集群里某个master节点资源宕机,则服务通过VIP将资源迁移到另一个master节点,对client来说,丝毫没有感觉。
# crm(live)configure# primitive vip ocf:hearbeat:IPaddr2 params ip="172.25.10.100" cidr_netmask="24" op monitor interval="30s"
c. 将MFS系统服务交由集群管理器管理。
# crm(live)configure# property no-quorum-policy="ignore" # 默认结点数若只有一个,表示集群不存在,忽视
# crm(live)configure# primitive mfsdata ocf:heartbeat:Filesystem params device="/dev/sda1" directory="/var/lib/mfs" fstype="ext4" op monitor interval="60s"
# crm(live)configure# primitive mfs lsb:mfs op monitor interval="60s"
# crm(live)configure# group mfsgroup vip mfs mfsdata
# crm(live)configure# order mfs-after-mfstdata inf: mfsdata mfs
在chunk 和client端加入hosts解析
172.25.10.100 mfsmaster
————————————————
原文链接:https://blog.csdn.net/gew25/article/details/51924952
以上是关于GlusterFS 存储的主要内容,如果未能解决你的问题,请参考以下文章