分布式文件存储——GlusterFS
Posted 明王不动心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式文件存储——GlusterFS相关的知识,希望对你有一定的参考价值。
一、概论
1.简介
GlusterFS (Gluster File System) 是一个开源的分布式文件系统,主要由 Z RESEARCH 公司负责开发。
GlusterFS 是 Scale-Out 存储解决方案 Gluster 的核心,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。
GlusterFS 借助 TCP/IP 或 InfiniBand RDMA 网络将物理分布的存储资源聚集在一起,使用单一全局命名空间来管理数据。
GlusterFS 基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
2.特点
(1)扩展性和高性能
GlusterFS利用双重特性来提供几TB至数PB的高扩展存储解决方案。
Scale-Out架构允许通过简单地增加资源来提高存储容量和性能,磁盘、计算和I/O资源都可以独立增加,支持10GbE和InfiniBand等高速网络互联。
Gluster弹性哈希(Elastic Hash)解除了GlusterFS对元数据服务器的需求,消除了单点故障和性能瓶颈,真正实现了并行化数据访问。
(2)高可用性
GlusterFS可以对文件进行自动复制,如镜像或多次复制,从而确保数据总是可以访问,甚至是在硬件故障的情况下也能正常访问。
自我修复功能能够把数据恢复到正确的状态,而且修复是以增量的方式在后台执行,几乎不会产生性能负载。
GlusterFS没有设计自己的私有数据文件格式,而是采用操作系统中主流标准的磁盘文件系统(如EXT3、ZFS)来存储文件,因此数据可以使用各种标准工具进行复制和访问。
(3)全局统一命名空间
全局统一命名空间将磁盘和内存资源聚集成一个单一的虚拟存储池,对上层用户和应用屏蔽了底层的物理硬件。
存储资源可以根据需要在虚拟存储池中进行弹性扩展,比如扩容或收缩。
当存储虚拟机映像时,存储的虚拟映像文件没有数量限制,成千虚拟机均通过单一挂载点进行数据共享。
虚拟机I/O可在命名空间内的所有服务器上自动进行负载均衡,消除了SAN环境中经常发生的访问热点和性能瓶颈问题。
(4)弹性哈希算法
GlusterFS采用弹性哈希算法在存储池中定位数据,而不是采用集中式或分布式元数据服务器索引。
在其他的Scale-Out存储系统中,元数据服务器通常会导致I/O性能瓶颈和单点故障问题。
GlusterFS中,所有在Scale-Out存储配置中的存储系统都可以智能地定位任意数据分片,不需要查看索引或者向其他服务器查询。
这种设计机制完全并行化了数据访问,实现了真正的线性性能扩展。
(5)弹性卷管理
数据储存在逻辑卷中,逻辑卷可以从虚拟化的物理存储池进行独立逻辑划分而得到。
存储服务器可以在线进行增加和移除,不会导致应用中断。
逻辑卷可以在所有配置服务器中增长和缩减,可以在不同服务器迁移进行容量均衡,或者增加和移除系统,这些操作都可在线进行。
文件系统配置更改也可以实时在线进行并应用,从而可以适应工作负载条件变化或在线性能调优。
(6)基于标准协议
Gluster存储服务支持NFS, CIFS, HTTP, FTP以及Gluster原生协议,完全与POSIX标准兼容。
现有应用程序不需要作任何修改或使用专用API,就可以对Gluster中的数据进行访问。
这在公有云环境中部署Gluster时非常有用,Gluster对云服务提供商专用API进行抽象,然后提供标准POSIX接口。
3.整体架构、常见术语以及常用命令
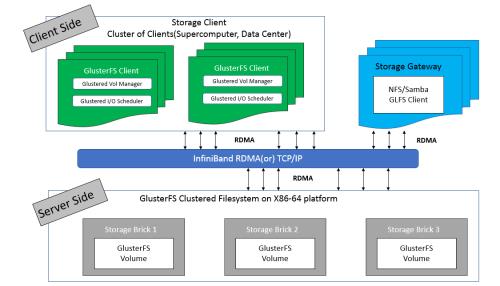
GlusterFS 有非常多的术语,理解这些术语对理解 GlusterFS 的动作机理是非常重要的,表1给出了 GlusterFS 常见的名称及其解释。
| brick | GlusterFS的基本单元,以节点服务器目录形式展现 |
| Volume | 多个 bricks 的逻辑集合 |
| Metadata | 元数据,用于描述文件、目录等的信息。 |
| Self-heal | 用于后台运行检测复本卷中文件和目录的不一致性并解决这些不一致。 |
| FUSE |
Filesystem Userspace是一个可加载的内核模块,其支持非特权用户创建自己的文件系统而不需要修改内核代码。 通过在用户空间运行文件系统的代码通过FUSE代码与内核进行桥接。 |
| GlusterFS Server | 数据存储服务器,即组成GlusterFs存储集群的节点。 |
| GlusterFS Client |
GlusterFS 客户端常用命令:
| gluster peer probe | 添加节点 |
| gluster peer detach | 移除节点 |
| gluster volume create | 创建卷 |
| gluster volume start | 启动卷 |
| gluster volume stop | 停止卷 |
| gluster volume delete | 删除卷 |
| gluster volume quota enable | 开启卷配额 |
| gluster volume quota enable | 关闭卷配额 |
| gluster volume quota limit-usage | 设定卷配额 |
二、卷类型及其操作
为了满足不同应用对高性能、高可用的需求,GlusterFS 支持 7 种卷,即 distribute 卷、stripe 卷、replica 卷、distribute stripe 卷、distribute replica 卷、stripe Replica 卷、distribute stripe replica 卷。
其实不难看出,GlusterFS 卷类型实际上可以分为 3 种基本卷和 4 种复合卷,每种类型的卷都有其自身的特点和适用场景。
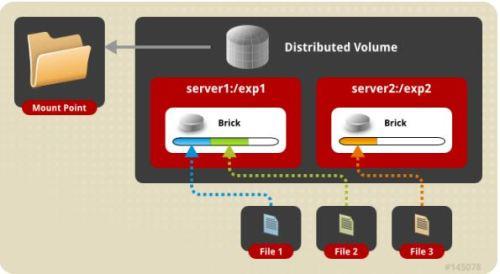
1.distribute volume 分布式卷
基于 Hash 算法将文件分布到所有 brick server,只是扩大了磁盘空间,不具备容错能力。
由于distribute volume 使用本地文件系统,因此存取效率并没有提高,相反会因为网络通信的原因使用效率有所降低,
另外本地存储设备的容量有限制,因此支持超大型文件会有一定难度。
分布卷也称为哈希卷,多个文件在多个 brick 上使用哈希算法随机存储。
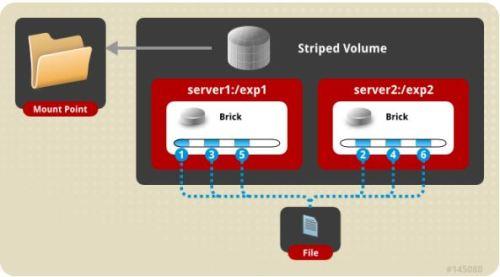
2.stripe volume 条带卷
类似 RAID0,文件分成数据块以 Round Robin 方式分布到 brick server 上,并发粒度是数据块,支持超大文件,大文件的读写性能高。
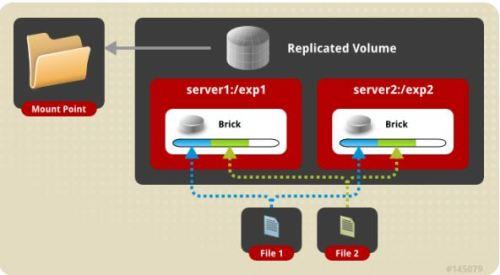
3.replica volume 复制卷
文件同步复制到多个 brick 上,文件级 RAID1,具有容错能力,写性能下降,读性能提升。Replicated 模式,也称作 AFR(Auto File Replication),相当于 RAID1,即同一文件在多个镜像存储节点上保存多份,每个 replicated 子节点有着相同的目录结构和文件,replica volume 也是在容器存储中较为推崇的一种。
4.distribute stripe volume 分布式条带卷
Brick server 数量是条带数的倍数,兼具 distribute 和 stripe 卷的特点。分布式的条带卷,volume 中 brick 所包含的存储服务器数必须是 stripe 的倍数(>=2倍),兼顾分布式和条带式的功能。每个文件分布在四台共享服务器上,通常用于大文件访问处理,最少需要 4 台服务器才能创建分布条带卷。
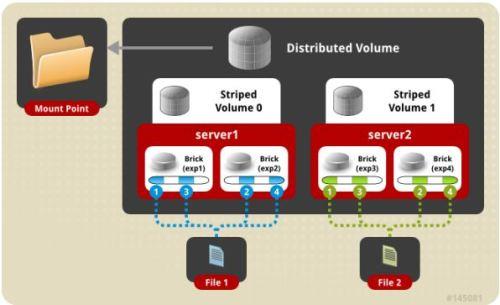
5.distribute replica volume 分布式复制卷
Brick server 数量是镜像数的倍数,兼具 distribute 和 replica 卷的特点,可以在 2 个或多个节点之间复制数据。分布式的复制卷,volume 中 brick 所包含的存储服务器数必须是 replica 的倍数(>=2倍),兼顾分布式和复制式的功能。
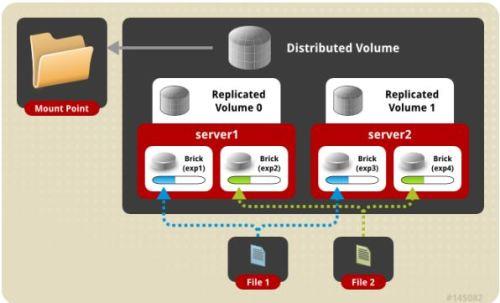
6.stripe replica volume 条带复制卷
类似 RAID 10,同时具有条带卷和复制卷的特点。
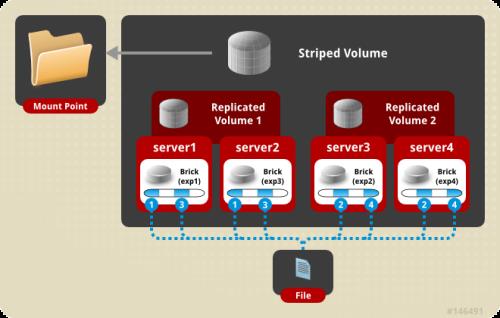
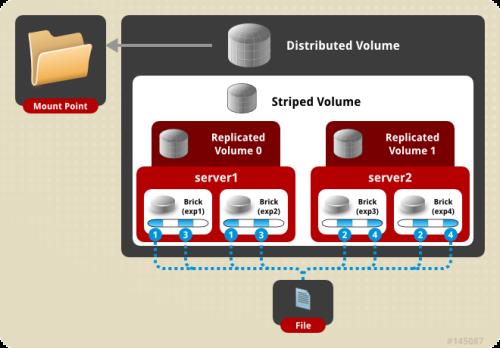
7.distribute stripe replica volume:分布式条带复制卷
三种基本卷的复合卷,通常用于类 Map Reduce 应用。
以上是关于分布式文件存储——GlusterFS的主要内容,如果未能解决你的问题,请参考以下文章